随着DeepSeek R1、OpenAI o1及o3等一系列推理大模型的陆续面世,目前可供选择的模型类型确实丰富了许多。但需要先厘清一个关键点:推理大模型与普通大模型并非非此即彼的对立关系,面对不同的问题场景,它们各自拥有不可替代的优势。为了让广大开发者与AI从业者更清晰地把握两类模型的应用边界,OpenAI官方专门发布了一份面向推理大模型的最佳实践指南,深入对比了二者差异,并总结了提示词(Prompt)编写的关键要点。以下是对该指南的精炼梳理与核心总结。

本文目录:
- 推理大模型与普通大模型的简明对比
- 各类大模型分别适合哪些典型场景?
- 推理大模型的提示词(Prompt)该如何编写?
- 推理大模型适用场景的实际案例解析
推理大模型与普通大模型的简明对比
此前已有非常详尽的对比分析,全面解读了推理大模型与普通大模型的差异。简单来说,推理大模型在给出最终回答之前,会先进行内部思考——它在返回用户结果之前,会自动生成一条较长的思维链,从而显著提升其推理能力。对OpenAI而言,当前普通大模型指GPT系列,推理大模型则指o系列。值得关注的是,Sam Altman也曾透露,未来几周即将发布的GPT-4.5将是OpenAI最后一款常规大模型,此后所有模型都将演变为推理型AI系统,系统会根据输入内容自动判断是否启用思维链推理。
这里需要特别强调:OpenAI的o系列推理大模型采用了与GPT系列不同的训练方式,因此提示词的设计也需要进行相应调整。推理大模型在某些任务上确实表现卓越,但并非在所有场景下都能优于其他模型。
推理大模型能够针对复杂任务进行更持久、更深入的思考,因此在制定战略、设计复杂问题的解决路径,以及从大量模糊信息中做出精准决策时尤为有效。这些模型还能以高精度与高准确度完成任务,非常适合原本需要人类专家介入的领域,如数学、科学、工程、金融和法律等。
而普通GPT系列大模型延迟更低、成本更可控,更适合直接执行明确的任务。因此在实际应用系统中,一个常见的实践模式是:利用推理大模型进行任务规划与决策,再由普通大模型负责具体执行——尤其是当执行速度和成本优先级高于准确性时。
各类大模型分别适合哪些典型场景?
在正式讨论具体场景之前,先通过一张对比表格来直观把握两者的差异。
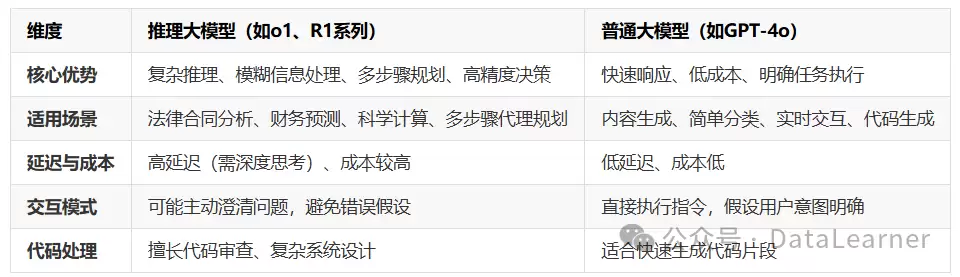
从上表可以清晰看出:
推理模型擅长复杂问题求解、策略规划与模糊信息处理,适用于对精度要求极高的领域(如法律、金融、工程)。
GPT模型则突出低延迟与低成本,适合明确任务的快速执行。
选择标准可归纳为以下四点:
- 速度与成本优先 → 优选普通大模型(如GPT-4o)
- 任务明确性 → 优选普通大模型(如GPT-4o)
- 准确性/复杂性 → 优选推理大模型(如o1、R1系列)
- 典型工作流:推理大模型负责规划,普通大模型负责执行。
根据OpenAI官方的建议,大多数工作流场景都可以将推理大模型与普通大模型混合使用:让推理大模型充当Agent的推理、规划与决策中枢,而普通大模型则负责具体的执行环节。
推理大模型的提示词(Prompt)该如何编写?
推理大模型的提示词编写与普通大模型确实存在细微差别。OpenAI官方专门总结了针对o1系列的提示词技巧(其他推理大模型如DeepSeek R1可能有所不同)。这里有一个核心原则:推理大模型在接受简洁明了的提示时表现最佳。某些传统的提示工程技巧,比如要求模型“逐步思考”,反而可能不会提升性能,甚至会产生反效果。
以下是最佳实践要点:
- 自2024年12月17日起,推理模型支持使用开发者消息替代系统消息,与模型规范中的命令链行为保持一致。
- 保持提示简单直接:这类模型擅长理解并回应简洁、清晰的指令。
- 避免链式思维提示:由于模型内部已经具备推理能力,无需再提示它“逐步思考”或“解释推理过程”。
- 使用分隔符提高清晰度:像Markdown、XML标签和章节标题这类分隔符,能够帮助模型清晰区分输入的不同部分。
- 优先尝试零样本提示,再按需使用少量样本提示:推理模型通常不需要少量示例就能产出好结果,所以先尝试没有示例的提示。如果输出需求复杂,再适当加入几个输入和预期输出的示例,但要确保示例与指令高度一致。
- 提供具体指导:如果希望输出受到某些限制(比如“提出一个预算在500美元以内的解决方案”),务必在提示中明确说明。
- 明确目标:在指令中给出清晰、具体的成功标准,并鼓励模型不断推理和迭代,直到满足这些标准。
- Markdown格式:自2024年12月17日起,API中的推理模型默认避免生成Markdown格式的回答。如果确实需要Markdown输出,可以在开发者消息的第一行加上字符串“Formatting re-enabled”。
可以看到,第一条和最后一条是OpenAI推理大模型特有的建议,其他推理大模型(如DeepSeek R1)可能并不适用。
推理大模型适用场景的实际案例解析
为了更直观地展示推理大模型的能力边界,这里整理出OpenAI官方给出的7个具体案例。
1. 推理大模型适合处理模糊信息的任务
法律和金融领域的文档常包含不完整或难以解读的信息,传统模型的理解能力和准确性往往不足。以Hebbia为例,这是一家专注于法律和金融分析的AI平台,需要快速处理复杂的信贷协议并提取关键条款。过去人工分析既耗时又易出错,而引入o1模型后,通过简单的提示就能理解并提取出“限制性支付篮子”等关键条款,即使面对模糊信息也表现出色。与其他模型相比,o1在处理密集、模糊的法律条款时,成功率提升了52%。
2. 推理大模型擅长从大量数据中提取关键信息
在并购交易中,合同文件包含大量复杂条款和潜在法律风险,尤其当条款隐藏在脚注或小字中时,手动审查极易遗漏。Endex是一家金融智能平台,专注于分析并购交易文档,其挑战在于从海量合同文件中快速找出影响交易的关键条款。使用o1后,Endex能精准识别出合同中的“控制权变更”条款,明确指出如果公司被收购,需立即偿还7500万美元贷款。这种高效的推理能力帮助企业快速锁定重大财务风险。
3. 推理大模型适用于跨文档推理和复杂决策
税务研究往往需要处理大量文档,且文档之间逻辑关系复杂,需要跨文档推理才能得出结论。Blue J是一家税务分析AI平台,他们从多个法律文档中提取信息并进行推理,从而形成准确的税务报告。传统方法需人工逐一分析每个文档,使用o1后,模型能有效进行跨文档推理,提取多个文档之间的内在联系,处理复杂税务问题的效率提升了4倍,推理结果也更加准确。
4. 推理大模型能高效执行多步骤规划任务
复杂任务规划中,如何有效拆解并分配步骤始终是一个难题。Argon AI为制药行业提供AI解决方案,他们面临的挑战是将复杂任务分解为多个步骤,并确保每一步精准执行。通过使用o1,Argon AI不仅能为复杂任务制定清晰规划,还能在每个步骤中选择最合适的执行模型。尤其在需要精确拆解的大型制药项目中,o1作为“规划者”的角色,显著提升了项目执行效率和准确性。
5. 推理大模型在处理复杂视觉数据中的表现优异
图表或结构模糊的图片,传统模型往往难以精准分析,尤其当图像质量较差时。Safetykit是一家在线产品合规审核AI平台,需要处理低质量的产品图像(例如珠宝类图片),这些图像常缺乏明确结构。他们最初尝试GPT-4o进行图像识别,准确率仅50%。改用o1后,准确率飙升至88%。无论是模糊图像还是含有复杂信息的视觉数据,o1都展现出强大的推理和视觉理解能力,极大提升了合规审核的准确性。
6. 推理大模型在代码审查中的优势
代码审查常涉及大量的代码比对,多文件比较时任何微小差异都可能被遗漏。CodeRabbit是一家代码审查AI平台,面临如何自动化处理大规模代码库细节差异的挑战。引入o1后,模型能精确检测出代码中的细微变化,尤其在多文件差异检测上表现突出。最终,CodeRabbit的代码审查准确性大幅提高,产品转化率实现了3倍增长。
7. 推理大模型在数据评估和模型质量检测中的应用
数据验证和模型评估,尤其是医疗等敏感领域,传统方法往往局限于预设规则和模式,无法充分考虑上下文。Braintrust是一家AI评估平台,专门从事数据验证和模型评估,在医疗行业需要对不同模型生成的摘要进行质量评估。使用o1后,Braintrust能更精准地评估模型输出,根据上下文推理并识别细微的质量差异。评估精度大幅提升,F1分数从0.12跃升至0.74,充分证明了推理大模型在复杂数据评估中的卓越能力。