提升RAG问答系统效能,探索Query Translation的创新路径。
核心内容:
1. Query Translation在RAG系统中的重要性和作用
2. Multi-query技术:生成多个查询以提高检索范围和准确性
3. RAG-Fusion技术:融合多个查询结果,提升答案的相关性和精确度
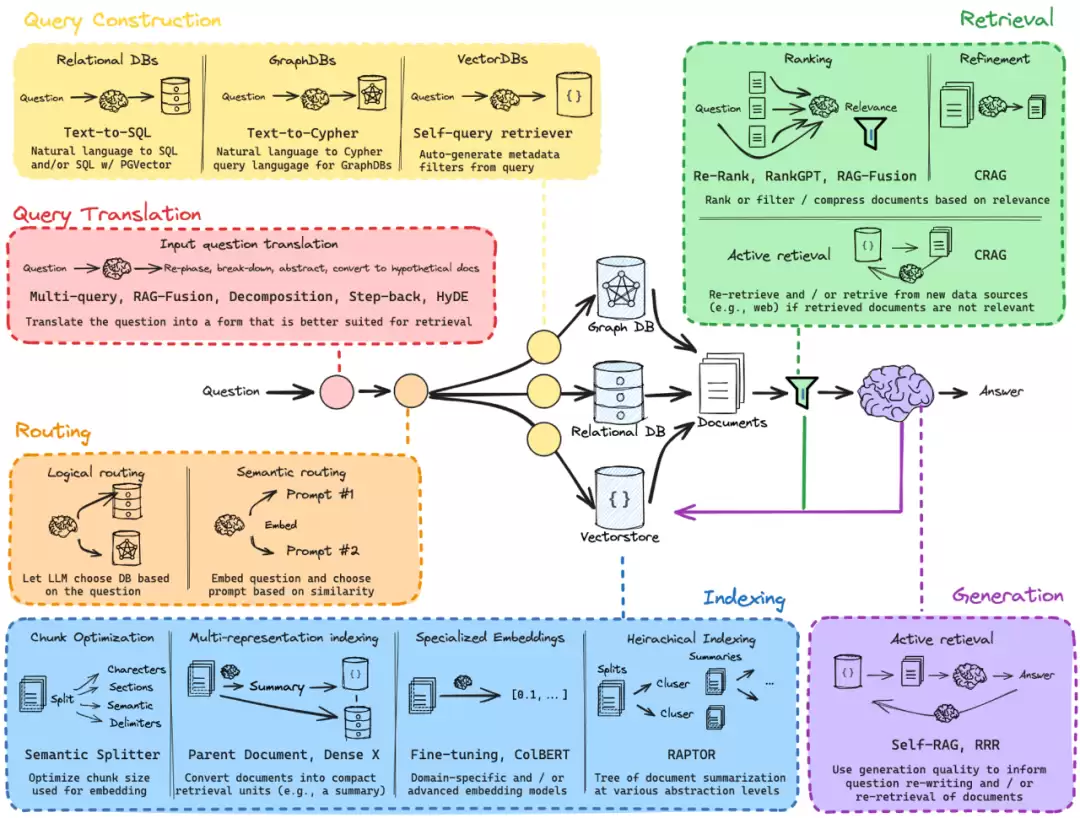
先直接进入正题。在RAG(检索增强生成)系统里,用户的原始查询往往不是最优的检索输入——要么太模糊,要么缺乏上下文,要么根本没法匹配数据库的结构。这就是Query Translation要解决的问题:把自然语言查询翻译成检索系统更“喜欢”的形式。
Query Translation
Query Translation的核心任务,是将用户的自然语言查询转换为更适合检索和生成的形式。在这个过程中,系统会把原始问题重新表达成一种或多种更易检索的版本,确保能从不同数据源中高效提取相关信息。
为什么需要这个步骤?直接拿原始问题去检索,常见的问题有三个:
- 查询过于模糊或复杂,数据库难以直接匹配相关内容。
- 信息缺失,例如用户只输入“DeepSeek-R1 的优势?”而没有明确上下文。
- 不同数据库的适配性——原始查询可能需要调整才能适应结构化数据、文档、向量数据库等不同数据源。
Query Translation涉及的技术方法主要包括以下几种:
Multi-query
Multi-query的思路很直接:针对同一个问题,先生成几个不同角度的查询,然后分别去检索,最后合并结果。这样能显著扩大检索覆盖面,提高召回率。举个例子:
- 原始查询:“如何提高 DeepSeek-R1 的推理能力?”
- 生成的多个查询:
- “DeepSeek-R1 的推理能力受哪些因素影响?”
- “如何优化提示(prompt)来增强 DeepSeek-R1 的推理能力?”
- “有哪些方法可以提升 DeepSeek-R1 在数学推理任务上的表现?”
RAG-Fusion
RAG-Fusion不只是生成多个查询,它更关注如何把这些查询的检索结果融合起来——比如使用Reciprocal Rank Fusion(RRF)这类算法,对不同结果进行加权排序,最终得到一个更精确、更丰富的答案。简单说,Multi-query是“多路出击”,RAG-Fusion是“集大成者”。
Multi-query 主要是生成多个查询,而 RAG-Fusion 侧重于如何融合这些查询的检索结果(例如 Reciprocal Rank Fusion)。
Decomposition
对于复杂问题,直接检索往往力不从心。Decomposition的做法是先把问题拆成几个简单子问题,然后分别检索每个子问题的答案,最后再组合。比如:
- 原始查询:“比较 Transformer 和 RNN 在文本摘要任务上的优缺点。”
- 分解后的查询:
- “Transformer 在文本摘要任务上的优点是什么?”
- “RNN 在文本摘要任务上的优点是什么?”
- “Transformer 和 RNN 在文本摘要任务上的对比研究有哪些?”
Step-back
当直接查询找不到足够相关的文档时,不妨先退一步,检索更高层次的信息,再逐步细化。这特别适合探索性查询。例如用户问“李白的诗风如何?”,可以先检索“李白的代表作品有哪些?”、“李白的诗风如何在《将进酒》中体现?”等,再精确定位。
HyDE
HyDE(Hypothetical Document Embeddings)则更进一步:它根据用户查询先生成一则“假设性的文档”,然后把这个假设文档拿去嵌入和检索。这种“以文找文”的方式能更好地捕捉用户意图,提升检索效果。
总结一下,Query Translation通过上述技术,把原始问题转化成更易检索的形式,最终优化检索过程并提升答案质量。
Query Translation 的优势
- ✅ 提高召回率:通过 Multi-query、RAG-Fusion 等方法确保检索更全面。
- ✅ 提升查询精度:Step-back 和 HyDE 方法优化查询表达,提高相关性。
- ✅ 增强复杂查询的可操作性:查询分解可以让复杂问题更容易匹配数据库内容。
QA:Multi-query 和 RAG-Fusion 有什么区别?
这个问题很常见——两者都先生成多个相关查询,但目标不同。
- Multi-query 的核心是扩展检索范围:生成多个不同角度或表达方式的查询,分别去检索,增加找到相关信息的机会。比如同样问“如何提高机器学习模型的准确性?”,生成“提高机器学习模型准确性的技巧”、“机器学习精度优化方法”、“如何训练更精确的机器学习模型”等,然后各自检索。
- RAG-Fusion 则专注于结果融合:在生成多个查询后,重点是如何整合这些查询的检索结果(比如加权、排序),最终给出一个更全面、更准确的答案。
关键区别:Multi-query是检索层面的扩展,RAG-Fusion更多是在生成层面上的整合。
QA:RAG-Fusion 中的文档融合方法——RRF
RRF(Reciprocal Rank Fusion)是RAG-Fusion中常用的融合算法。基本思想是根据每个结果在不同查询中的排名来加权计算得分,从而把多个查询的检索结果整合成一个排序列表。这种方法尤其适合处理多来源的检索结果,能有效提升最终答案的质量。
Demo
代码示例:https://github.com/realyinchen/RAG/tree/main/QueryTranslation
Routing
Routing(路由)要解决的是另一个关键问题:面对不同的数据源(关系数据库、图数据库、向量数据库等),应该把用户的查询派送到哪里去?它智能地选择合适的处理路径,系统才能高效定位相关数据。
Routing分为逻辑路由和语义路由两种方式。
1. Logical Routing
逻辑路由基于预定义的规则或查询的结构化特征来选择数据源。比如,如果查询涉及结构化数据(如“找出所有销售量最高的商品”),系统自动路由到关系数据库;如果查询涉及社交关系(如“查找与某个用户关系最密切的其他用户”),系统会选择图数据库。
2. Semantic Routing
语义路由则依靠查询的语义相似度来决定路由。系统把用户查询转换成向量,与预定义的“提示词”或模板的向量进行比对,选择最相似的处理路径。比如用户问“推荐给我一些科技书籍”,语义路由会识别出这是书籍推荐类查询,路由到向量数据库或推荐系统。
Routing 的优势
- ✅ 智能分流,提高检索效率:直接跳转到最相关的数据源,避免无效路径。
- ✅ 精准匹配:根据查询内容和类型匹配最佳处理方法,确保结果质量。
- ✅ 适应多模态数据:可以处理结构化、非结构化和语义搜索任务。
Demo
代码示例:https://github.com/realyinchen/RAG/tree/main/Routing
Query Construction
Query Construction是将自然语言查询转换为特定数据库能理解的查询语句或过滤条件。在整个RAG架构中,它让系统能够更智能地处理复杂的异构数据源。
1. 关系型数据库
对于关系型数据库,需要把自然语言转换成SQL语句。例如用户问“列出销售量大于1000的产品”,生成:
SELECT * FROM products WHERE sales > 1000;
如果数据库支持向量搜索(如PostgreSQL + PGVector),SQL可能还会包含ANN搜索:
SELECT * FROM products ORDER BY embedding <-> '[query_embedding]' LIMIT 10;
2. 图数据库
图数据库需要转换成Cypher查询(Neo4j)或Gremlin。例如“查找与用户123关系最密切的用户”:
MATCH (u:User)-[:FRIEND_WITH]->(f:User) WHERE u.id = 123 RETURN f ORDER BY f.interaction_score DESC LIMIT 5;
3. 向量数据库
向量数据库的查询构造除了计算查询嵌入的相似度,还常常需要附加元数据过滤条件,以减少噪声、提高精度。比如用户问“找一些关于Transformer论文的摘要”,常规搜索是:
vector_db.search(query_embedding, top_k=10)
结合元数据过滤后:
vector_db.search(query_embedding, top_k=10, filters={"category": "paper", "year": {"$gte": 2020}})
这样只检索2020年以后的论文类别,既快又准。
Query Construction 的优势
- ✅ 更精准的查询:为不同数据源定制查询,保证高质量结果。
- ✅ 支持多种数据库类型:适配结构化数据、关系型数据、向量数据。
- ✅ 自动元数据过滤:减少无关结果,提高相关性。
- ✅ 高效查询执行:合理构造的查询能更快获得响应。
Demo
代码示例:https://github.com/realyinchen/RAG/tree/main/QueryConstruction
Indexing
Indexing是RAG系统中容易被忽视却极其关键的环节。它负责组织和优化文档,直接影响检索效率和召回质量。核心涉及四个方面:
1. Chunk Optimization(文本切片优化)
整篇文档直接索引会导致匹配不精准、计算开销大。更好的做法是按语义单元切分,比如使用Semantic Splitter,让每个切片包含完整语义信息,从而提高查询匹配精度,降低不必要的计算。
2. Multi-representation Indexing(多表征索引)
通过结合文档的摘要、块和完整内容,用不同粒度的表示弥补单一表示的不足。一个典型的实现是Proposition Indexing:先用LLM提取摘要,对摘要进行嵌入后存入向量库,同时保存原始文档。检索时匹配摘要,返回原始文本。这样对长上下文LLM更友好,甚至可以整篇输入。
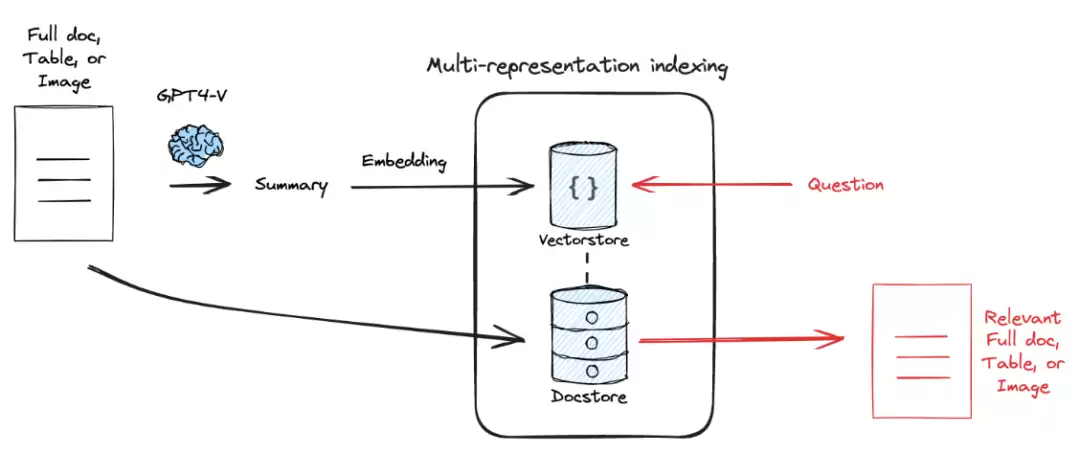
3. Specialized Embeddings(特定领域嵌入)
通用嵌入模型在法律、医学等专业领域往往表现不佳。这时可以用领域数据微调嵌入模型,或使用ColBERT这类细粒度交互模型。ColBERT实现了token级的相似度计算,通过最大池化(MaxSim)操作选出最相关文档,比直接压缩整篇文档为一个向量的做法精细得多。
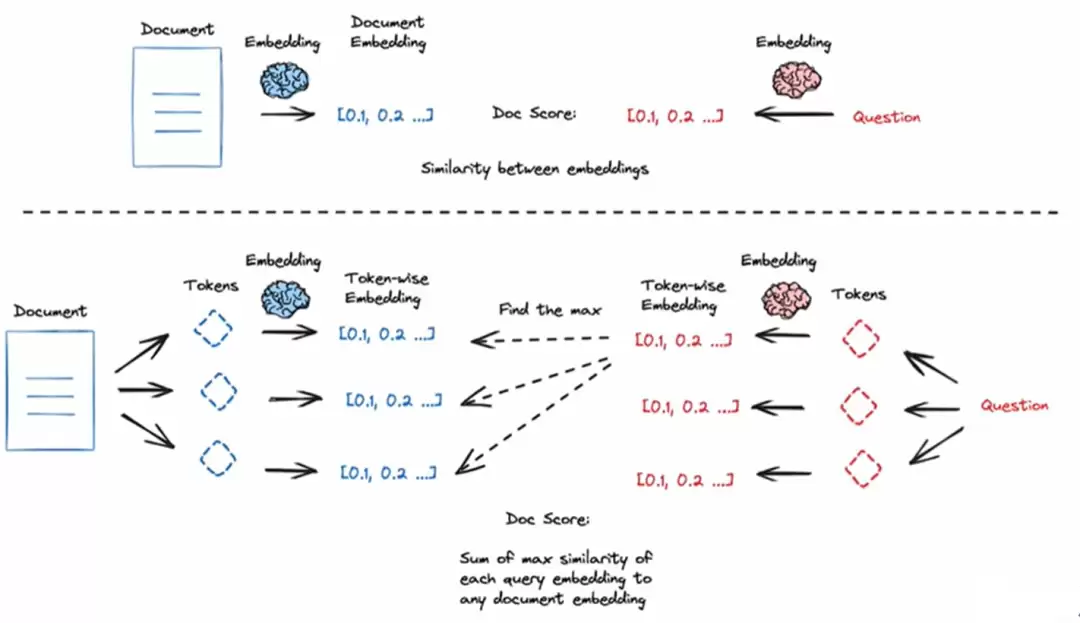
ColBERT的开源实现:https://github.com/stanford-futuredata/ColBERT
4. Hierarchical Indexing(层级索引)
对于大型文档集合(例如书籍、论文),RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)是一种有效方案。它将文档组织成树状结构:叶节点是原始块,高层节点是摘要。检索时可以根据查询粒度灵活地从不同层级获取信息,兼顾效率和精度。
Demo
代码示例:https://github.com/realyinchen/RAG/tree/main/Indexing
Retrieval & Generation
这是RAG系统的双引擎。检索负责找到最相关的外部信息,生成则基于这些信息产出高质量回答。两者互补,缺一不可。
Retrieval:找到最相关的信息
核心目标:高召回率、高精准度、可扩展性。关键技术包括:
- RAG Fusion:多查询+RRF融合,提高召回。
- Re-Rank:用Cross-Encoder等模型对初步结果重排序,把最相关的文档排在前面。
- Hybrid Retrieval:结合向量搜索、BM25、知识图谱,兼顾语义和关键词。
- Active Retrieval:LLM评估初步结果后决定是否需要额外查询,避免信息不足。
Generation:基于检索信息生成高质量答案
核心目标:增强事实性、提高推理能力、可控性。关键技术包括:
- CRAG(Corrective RAG):LLM评估检索文档的相关性,必要时触发额外检索补充数据。
- Self-RAG(Self-Reflective RAG):生成初步答案后自我检查,决定是否要调整或补充检索。
- Adaptive-RAG:根据查询复杂度动态选择检索和生成策略,提高效率、降低开销。
未来趋势
- 混合检索:向量搜索 + 关键字搜索 + 知识图谱,提高召回质量。
- 自适应RAG:LLM根据需求动态决定是否检索,提升系统效率。
- 端到端优化:将检索与生成集成训练,整体效果更优。
- 增强事实性:结合检索结果进行交叉验证,减少幻觉。