一、当效率遭遇主权:一个CTO的选型困局
某制造企业的CTO张总最近陷入两难:集团刚决策,半年内必须上线一套智能客服与合同审核系统,以应对海外订单的激增。技术团队提出两条路径——要么直接调用闭源大模型的API,两周内即可完成验证,但所有客户合同数据将流经第三方服务器;要么部署开源模型,数据全部保留在内网,但需额外投入两名资深工程师,上线周期可能延长至三个月。
“这早已不是单纯的技术问题,而是一场能力、成本与数据主权之间的三角博弈。”张总表示。
这句话精准点出了2026年企业级AI模型选型的核心挑战。当Gartner提出企业应采用“组合架构”来管理AI模型——将模型视为可灵活分配的基础设施——选型的本质便从“哪个模型最强”转变为“在质量、风险与成本的多维天平上,为每个具体工作负载找到最优解”。
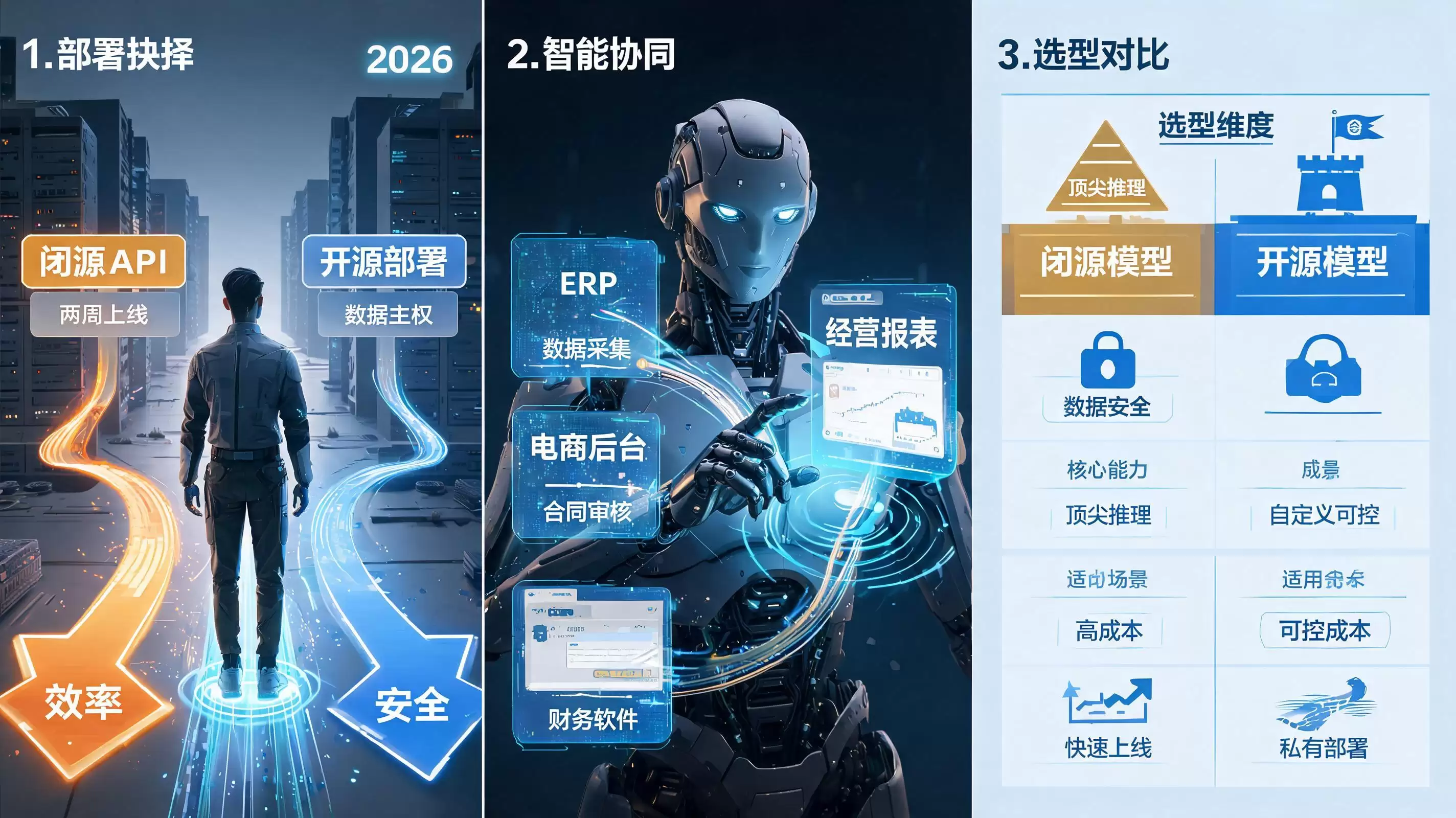
二、模型层选型:在能力天花板与数据主权之间走钢丝
闭源模型:当业务场景为关键任务“押注”
金融量化分析、复杂合同审核、多模态诊疗报告解读这类对精准度要求极高的场景,闭源模型依然是首选。以GPT-5.5和Claude Opus 4.8为代表的前沿模型,在综合推理、指令跟随和长上下文理解方面确实保持领先。这种领先在智能体任务中尤为明显——Claude Code在编程智能体领域已证明,闭源模型能将复杂任务拆解为可执行的步骤,自主完成。
这种“能力溢价”在某些场景中是必要投入,但代价同样显著:数据上传至第三方服务器,既要面对合规审查压力,又存在厂商锁定风险。API定价调整、服务条款变更,甚至模型迭代方向的变化,都可能让企业的技术规划发生变动。
开源模型:当“够用”哲学重塑性价比认知
与闭源模型的“能力天花板”形成对比的,是开源模型阵营打出的成本优势与数据主权牌。以DeepSeek V4、智谱GLM 5.2、阿里Qwen为代表,中国开源模型的价格通常仅为同级别闭源模型的十分之一甚至更低。大量标准化场景中——智能客服、文档摘要、营销文案生成——开源模型已能完成95%以上的工作。这种“够用且经济实惠”的特性,正在削弱闭源模型绝对领先的市场信心。
更关键的是,开源模型为企业带来的不仅是成本优势,更是一种战略级的自主可控。数据全部保留在内网,还能针对特定垂直领域进行深度微调,从长期看,这能转化为独特的技术资产壁垒。
一个值得关注的现象是:智谱GLM 5.2在FrontierSWE编程基准上已与Claude Opus 4.8表现接近。虽然开源模型在复杂智能体任务上的实用性仍有追赶空间,但差距正在以肉眼可见的速度缩小。
三、当“数字员工”成为刚需:从模型选型到平台选型的战略跃迁
模型选型只是第一步。当企业不只需要“会说话的模型”,更需要“能办事的智能体”——让它自动完成跨系统操作、数据采集和业务闭环——选型逻辑便发生了根本性变化。焦点从“选哪个模型”转向了“谁能将模型能力转化为具体的业务价值”。
在这一维度上,企业级智能体平台分化出了明显的流派。
无界务实派:让智能体直接操控业务系统
某卫生用品企业的财务负责人算过一笔账:公司电商业务横跨天猫、抖音、京东等平台,光经营数据采集就得靠人工每天登录180多个后台页面,耗时超过500小时。大促期间,数据更新频率根本无法满足小时级的投放策略调整需求。
突破出现在他们引入实在Agent之后。实在Agent属于“无界务实派”——这类智能体的独特之处在于,它们不仅能“读懂”业务需求,更能直接“操作”软件界面。依托自研的ISSUT屏幕语义理解技术,实在Agent可以像人一样“看懂”任何软件界面上的按钮、表格和输入框。即便ERP系统没有API接口,智能体也能自动完成数据采集。
在这个案例中,实在Agent打通了多平台数据链路,将经营分析的颗粒度从月度提升至小时级。每天上午11点前,管理层就能拿到分渠道、分单品级的利润报表,人工操作耗时减少了80%以上。该企业数字化负责人评价:“实在Agent让我们能获得更广、更深、更及时的经营数据,直接推动了经营决策的敏捷化。”
实在Agent的另一个关键能力是多智能体协同。面对复杂业务流程,系统可将任务分解为“非创造性工作”(如数据采集、发片核对)和“创造性决策”(如投放策略调整、定价优化),由不同的智能体组件协作完成。这种架构下,大模型负责“思考”,RPA负责“执行”,形成“感知—决策—执行”的闭环。
某大型跨境电商企业已将该模式应用于“AI-Native组织”转型中:20个编制里,17个已转型为“AI赋能型员工”,由实在Agent协同执行广告投放优化、全球知识产权监控、多平台商品一键刊登等任务,覆盖全球超过100个电商平台。
生态集成派:嫁接在企业数字化基座上
与实在Agent这类“无界操作”的策略不同,另一类平台选择深度融入特定生态。例如Salesforce Agentforce将智能体能力直接嵌入CRM工作流,使销售预测、客户意图识别、服务工单自动分配等环节无缝运行在Salesforce生态内。对于已深度使用Salesforce的企业而言,这种集成方式能最小化迁移成本,快速实现智能化升级。
但企业需要审慎判断自身场景。如果核心痛点在于打破遗留系统间的数据孤岛,或者需要智能体直接操控无接口的老旧软件,那么集成派的能力边界可能就需要重新评估了。
四、选型框架:从场景回溯到决策流
对于正在选型的企业决策者,建议采用“三层递进法”:
- 明确数据主权基线:涉及客户隐私、合同条款、财务核心数据的场景,优先选择可私有化部署的方案;非敏感场景(如营销文案生成、通用知识问答)可灵活选择闭源API。
- 评估系统环境复杂度:如果业务系统以标准API为主,生态集成派可能是性价比更高的选择;如果存在大量老旧系统、无接口软件或需要跨平台操作,无界务实派的能力更为匹配。
- 验证智能体闭环能力:进行概念验证时,不仅要测试模型的“对话能力”,更要测试智能体能否真正从理解指令一路走到操作系统、完成端到端执行。重点关注多智能体协同调度、UI自动化操作的成功率和稳定性。
| 选型维度 | 闭源模型(API调用) | 开源模型(自部署) | 无界务实派智能体 |
|---|---|---|---|
| 数据安全 | 数据流经第三方 | 数据全量留存在内网 | 支持私有化部署 |
| 核心能力 | 前沿推理与多模态能力 | 够用且可深度微调 | 可直接操作系统界面 |
| 成本结构 | 按调用量付费 | 前期硬件投入,长期成本低 | 根据企业规模灵活配置 |
| 适用场景 | 高精度关键任务 | 标准化批量任务 | 跨系统复杂业务闭环 |
五、结尾
2026年的企业AI模型选型,已不仅仅是技术路线的选择题,更是一场关于企业数字化主权的战略抉择。当ERP系统没有API接口,当预算执行需要跨多个平台手动操作,当门店巡检需同时对接十几个异构系统时,你需要的不是一个“更聪明的模型”,而是一个能直接操控业务系统的数字员工。
这场选型的终点,没有标准答案,只有企业对自己业务本质的深度理解。无论是选择开源闭源的混合架构,还是部署真正能“动手”的智能体平台,核心逻辑始终不变:让技术服务于业务闭环,而不是让业务迁就技术边界。