一场基于智算领域真实生产环境的实操考核

当智能体走进 GPU 集群运维现场,真正难的不是回答问题,而是定位问题。


智能体在GPU集群运维中到底行不行?光靠聊天框里对话肯定不够。最近针对这个方向,行业里搞了一套硬核的评测基准——AISHPerf。它不玩虚的,直接拉了一套真实的生产环境,有多大劲儿使多大劲儿,考的就是智能体在处理实际问题时的真本事。
从结果看,当前最先进的模型,论“动手能力”——也就是实际修复问题的成功率——跟一线运维专家比,还有不小的差距。但有意思的是,它们的反应速度和执行效率,已经倒逼我们开始重新审视传统运维的工作流了。
说到底,这套基准到底厉害在哪儿?主要有三点:
1. 真刀真枪的生产环境
市面上多数评测,要么是空中楼阁的问答,要么是简化的模拟场景。但AISHPerf不一样——它搭建了真实的、多厂商的国产芯片集群,跑的是真正的GPU训练任务。这意味着智能体面对的不是教科书,而是一个会报错、会卡顿、会出各种幺蛾子的真实系统。它能让你看到,一个模型在面对“显卡温度异常飙升”或者“分布式训练断连”时,到底能不能像个老手一样冷静拆解。
2. 多样化的跨层栈问题覆盖
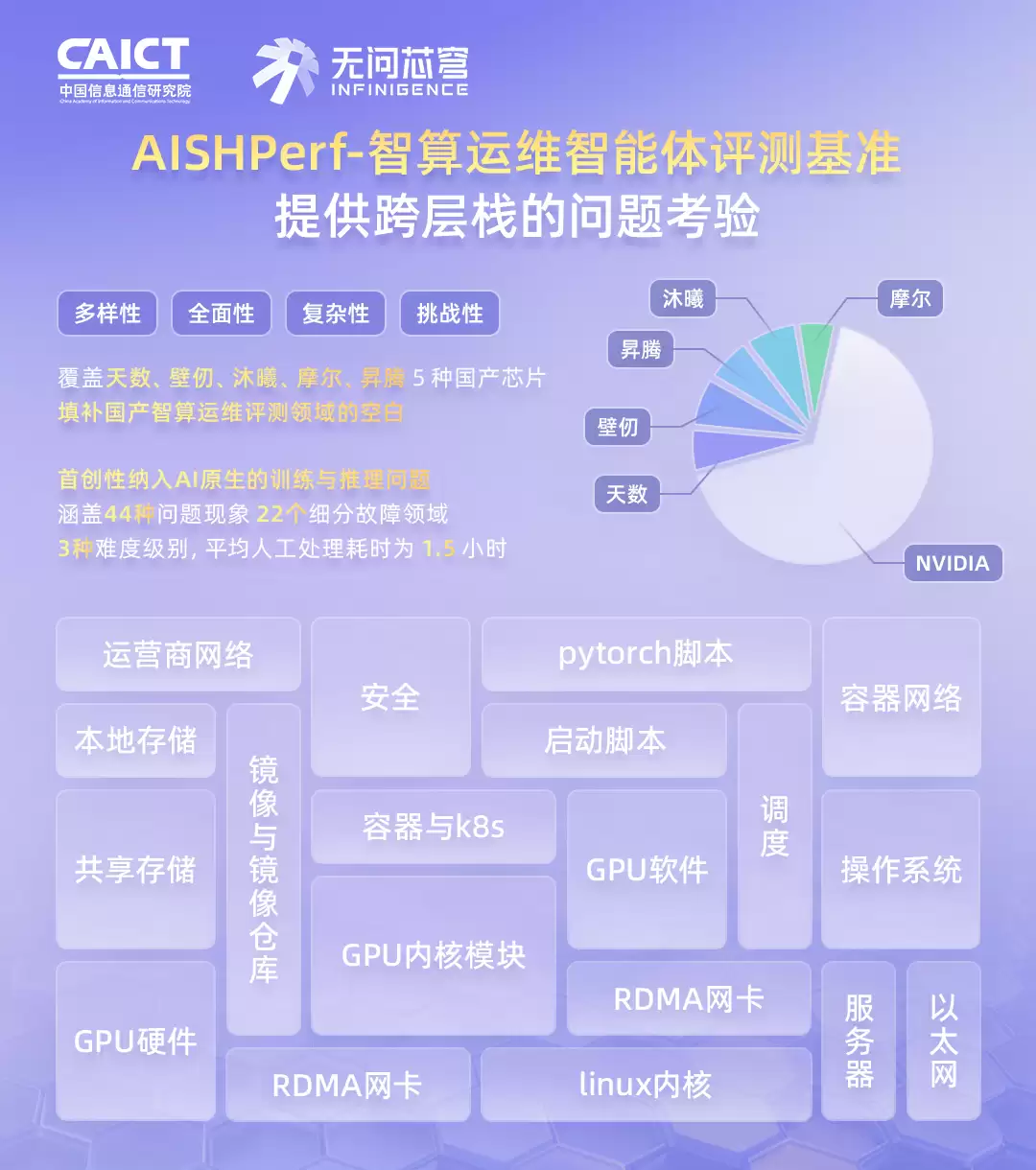
AI基础设施的运维复杂度,可远不是修修服务器那么简单。一个故障,可能从最底层的裸金属硬件,一路传染到上层的训练框架。为了应对这种复杂性,这套基准从底层硬件一路打通到用户侧的软件Bug,涵盖了你能想到的几乎所有故障类型。
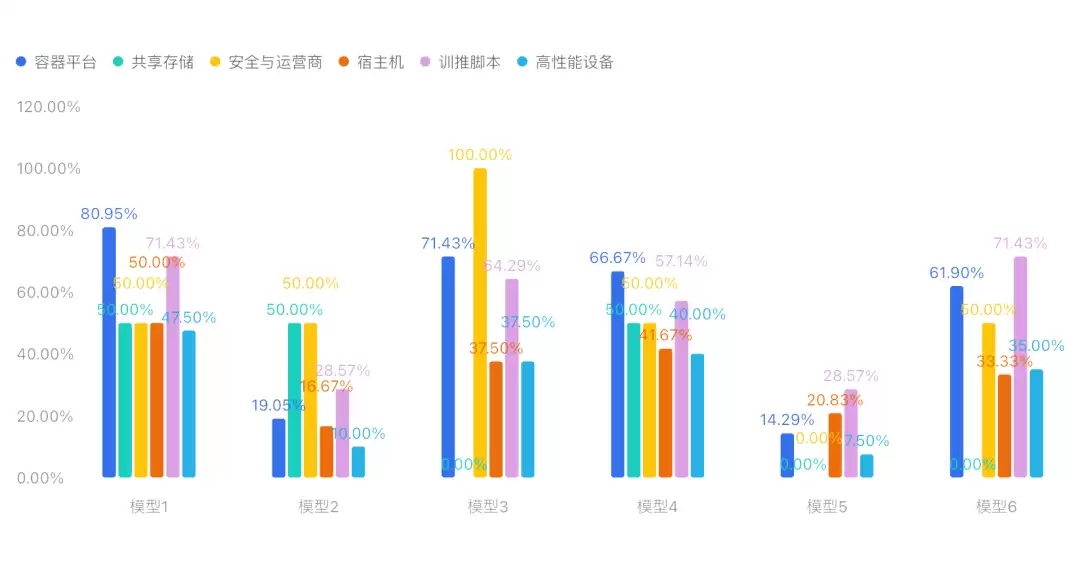
更难得的是,它纳入了天数、壁仞、沐曦、摩尔、昇腾5种国产芯片,而不是只盯着某一家。按照技术栈层级,问题被划分为宿主机、高性能设备、容器平台、训推脚本、安全与运营商五大类,一共44种问题现象,22个细分领域。这基本意味着,你在真实运维中能碰到的坑,这里都能找到对应场景。
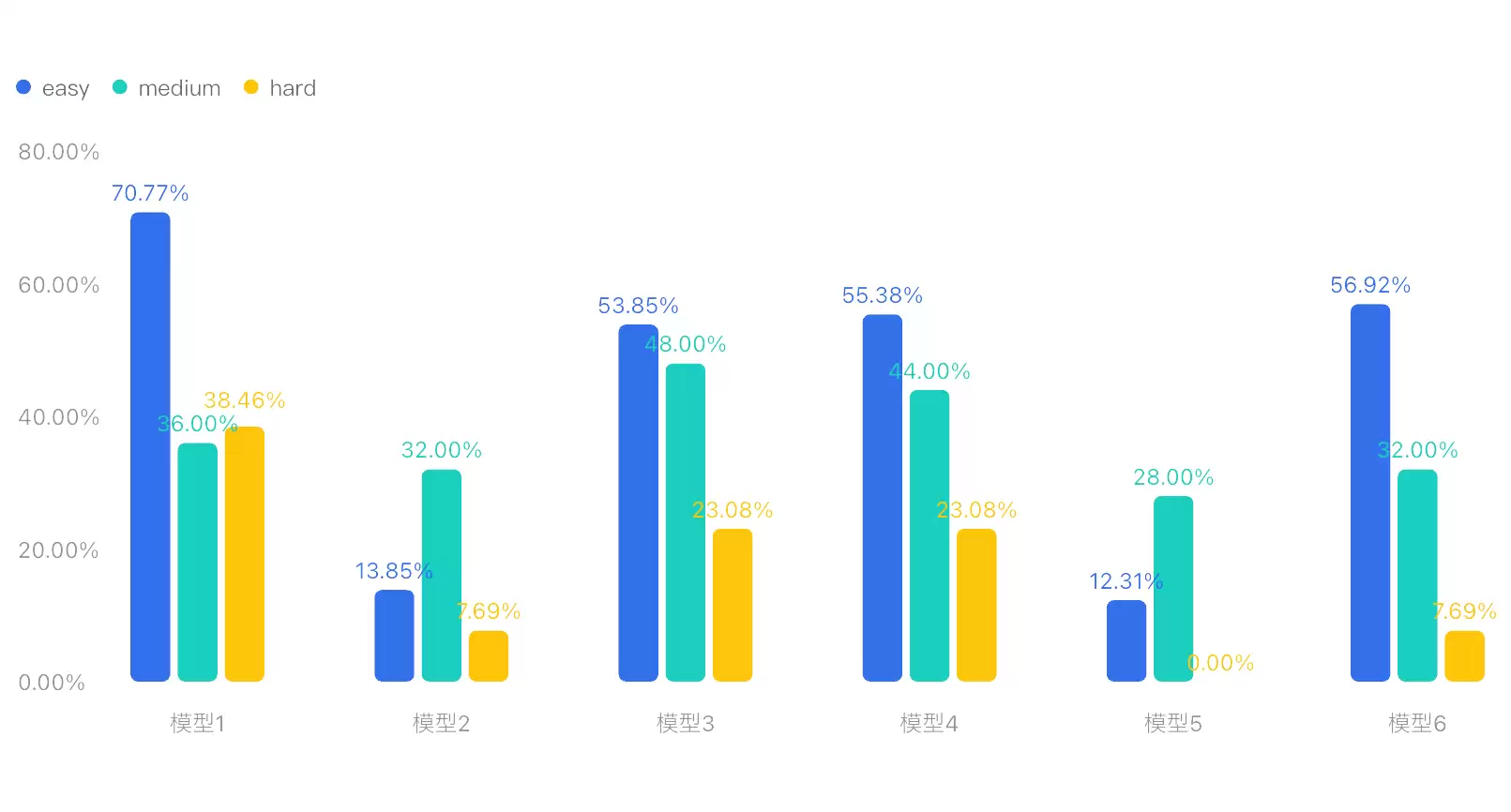
所有题目按难度分了三级,人工平均处理时间是1.5小时——充分说明想靠蒙过关是不可能的,每一道题都是硬骨头。
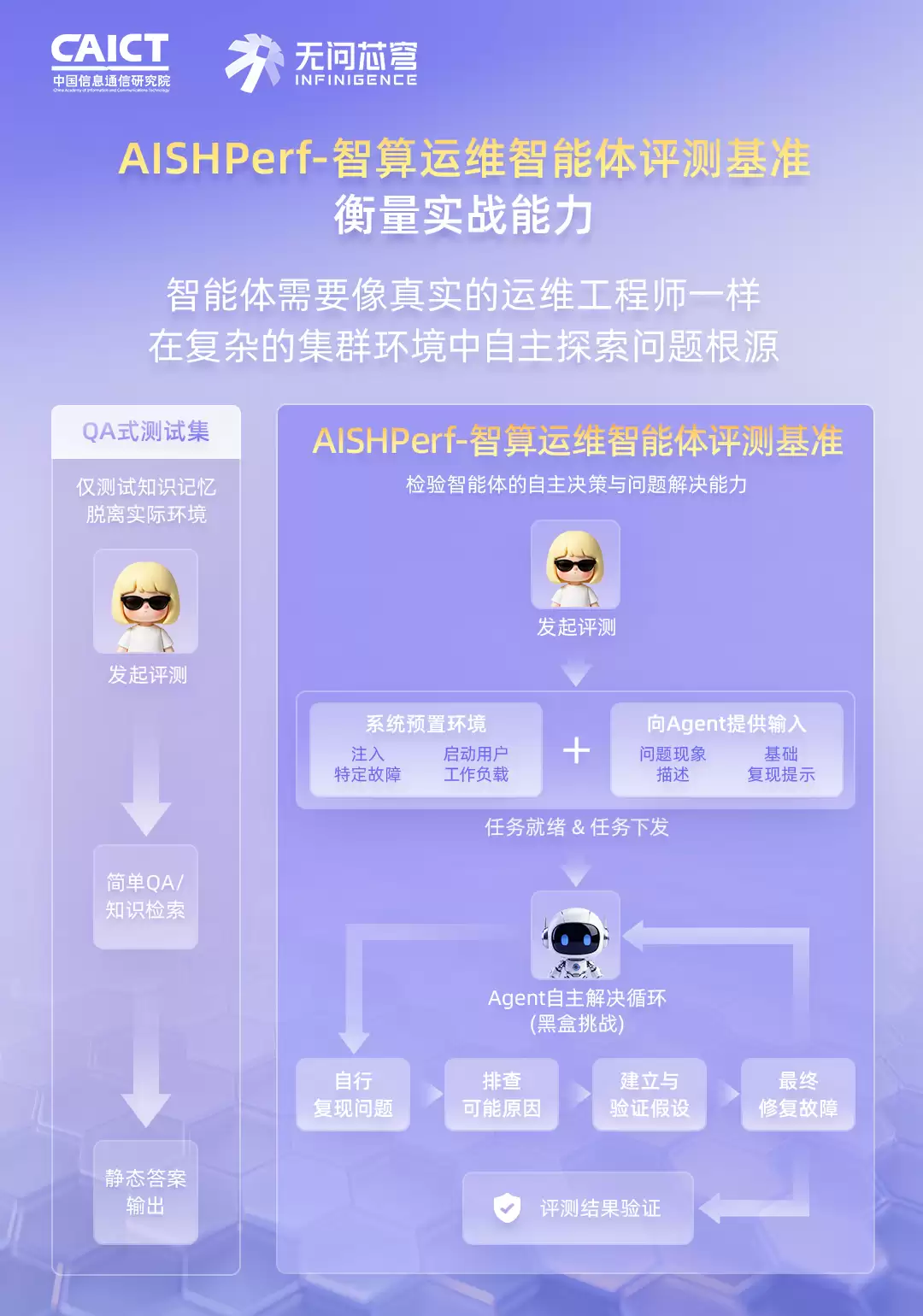
3. 开放式故障探索与处置
传统的模型评测更像一场笔试,考的是“这道题的标准答案是什么”。而AISHPerf是真正的实操考核。它不告诉你故障出在哪儿,只给你一个真实的集群环境和一段模棱两可的现象描述。智能体得自己摸索、自己排查、自己动手修复。
这要求可太高了:它得理解从物理设备到上层软件的每一层技术栈,得能和真实环境顺畅交互,还得在信息错杂的长上下文中,完成多跳推理和决策。一个判断失误,可能就把整个集群搞崩了。



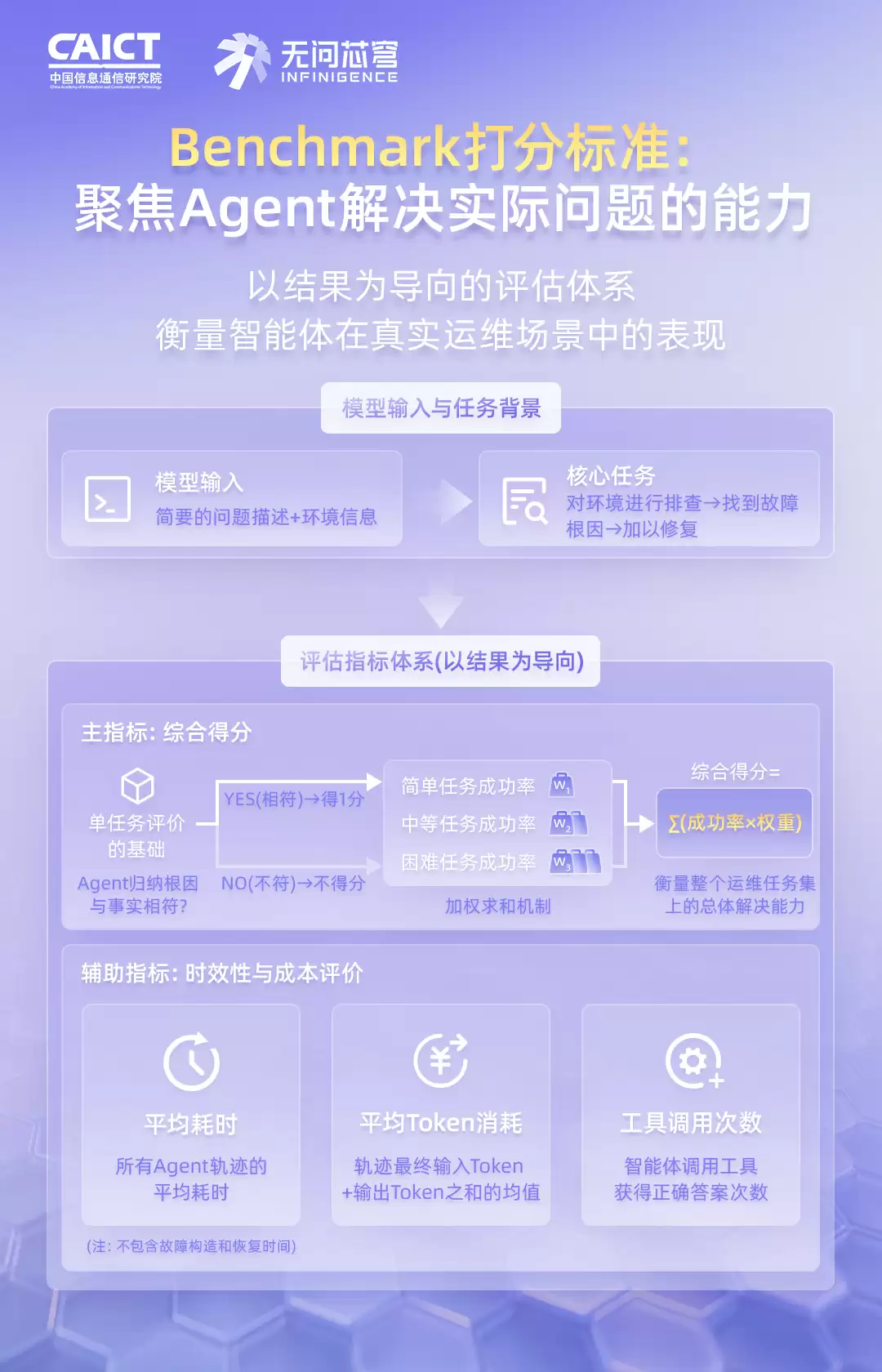
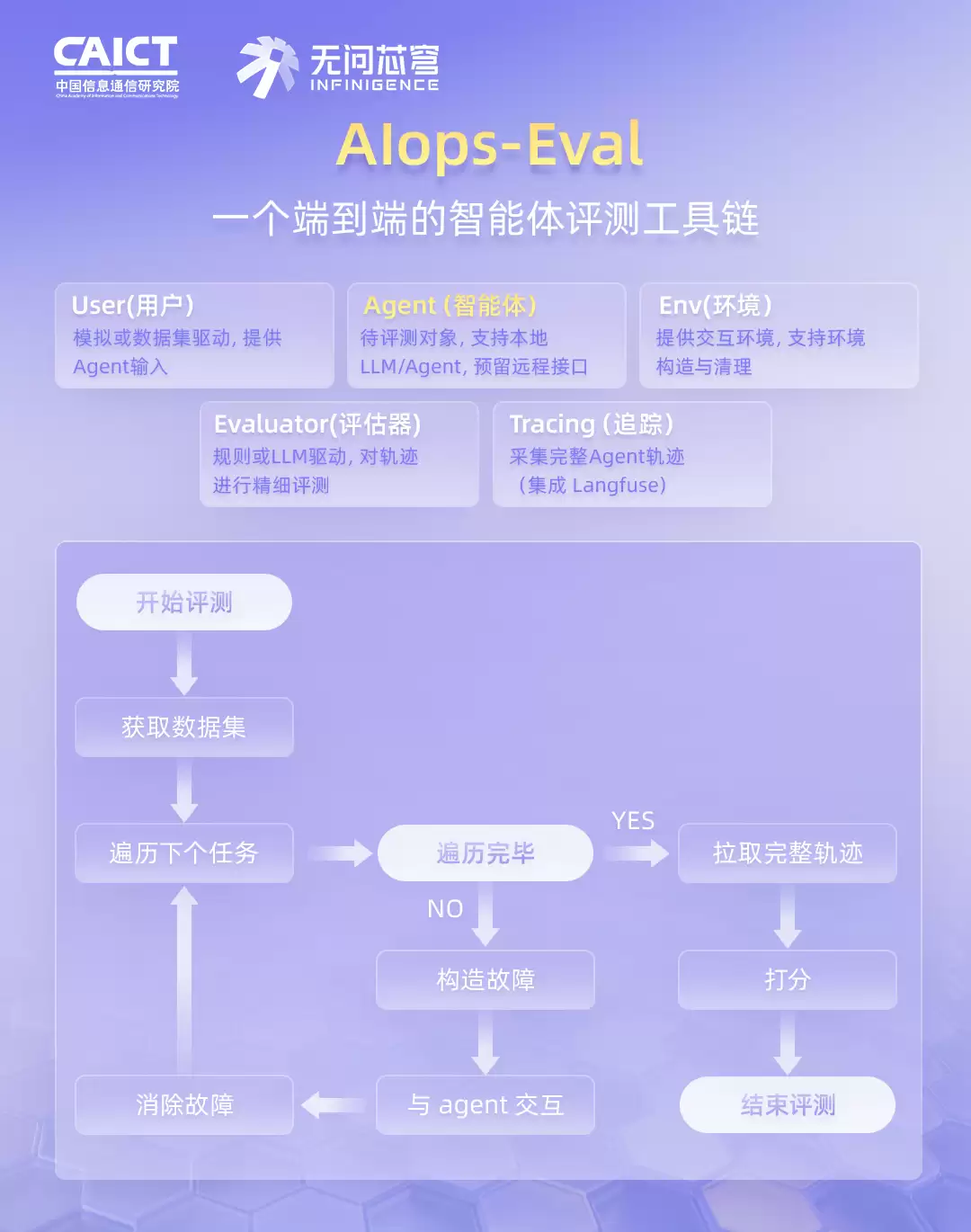
4. 评估框架:一个完整的评测工具链
评测框架本身也是一大亮点。社区里现有的工具,普遍有三大硬伤:各自为政的接口、只看结果不看过程、没有环境定义和构造能力。
为此,这套基准中集成了一款端到端的工具链——AIops-Eval。它由五个核心模块组成,像一个精密的流水线:
User 模块:负责模拟用户提问,既支持固定输入,也支持由大模型驱动的真实用户行为模拟。
Agent 模块:待测智能体本身,支持本地LLM和基于langgraph构建的本地智能体,同时留了远程智能体的接口。
Env 模块:为智能体提供交互环境,负责每轮测试前、后的环境搭建和清理,保证测试的公平。
Evaluator 模块:对智能体的完整执行轨迹进行打分,支持你写自定义规则,也可以用大模型当裁判。
Tracing 模块:基于开源的langfuse,完整记录智能体每一步的执行动作,方便事后复盘。

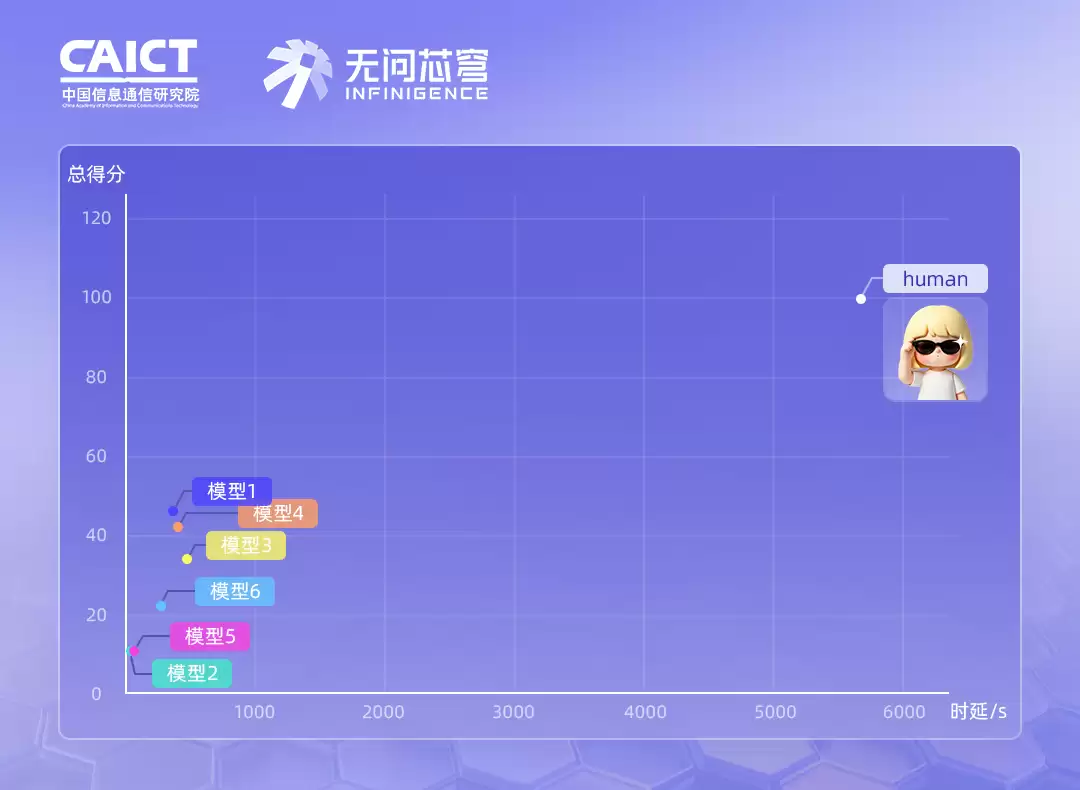
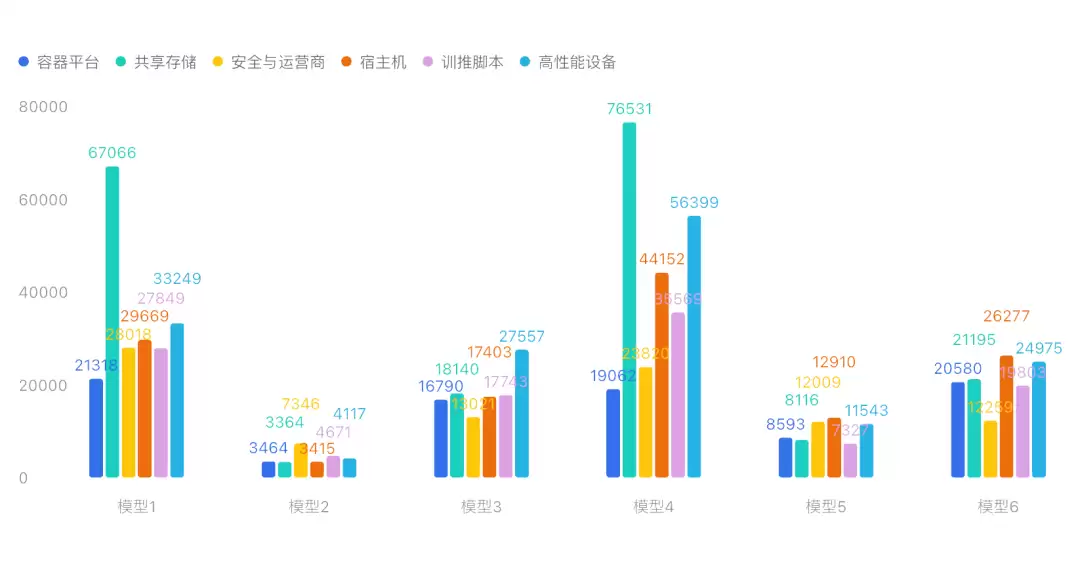
从图中可以看到两个关键结论:
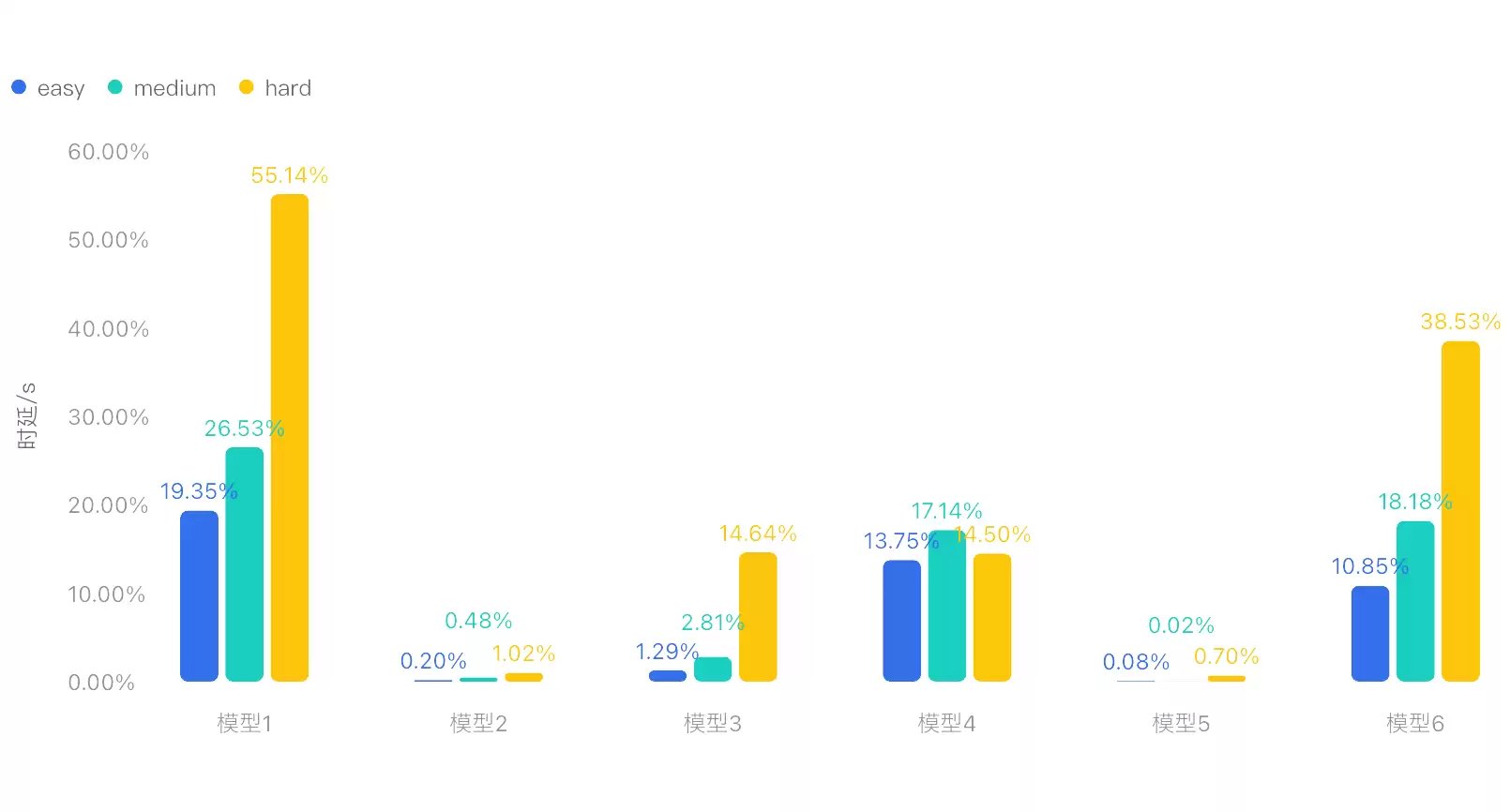
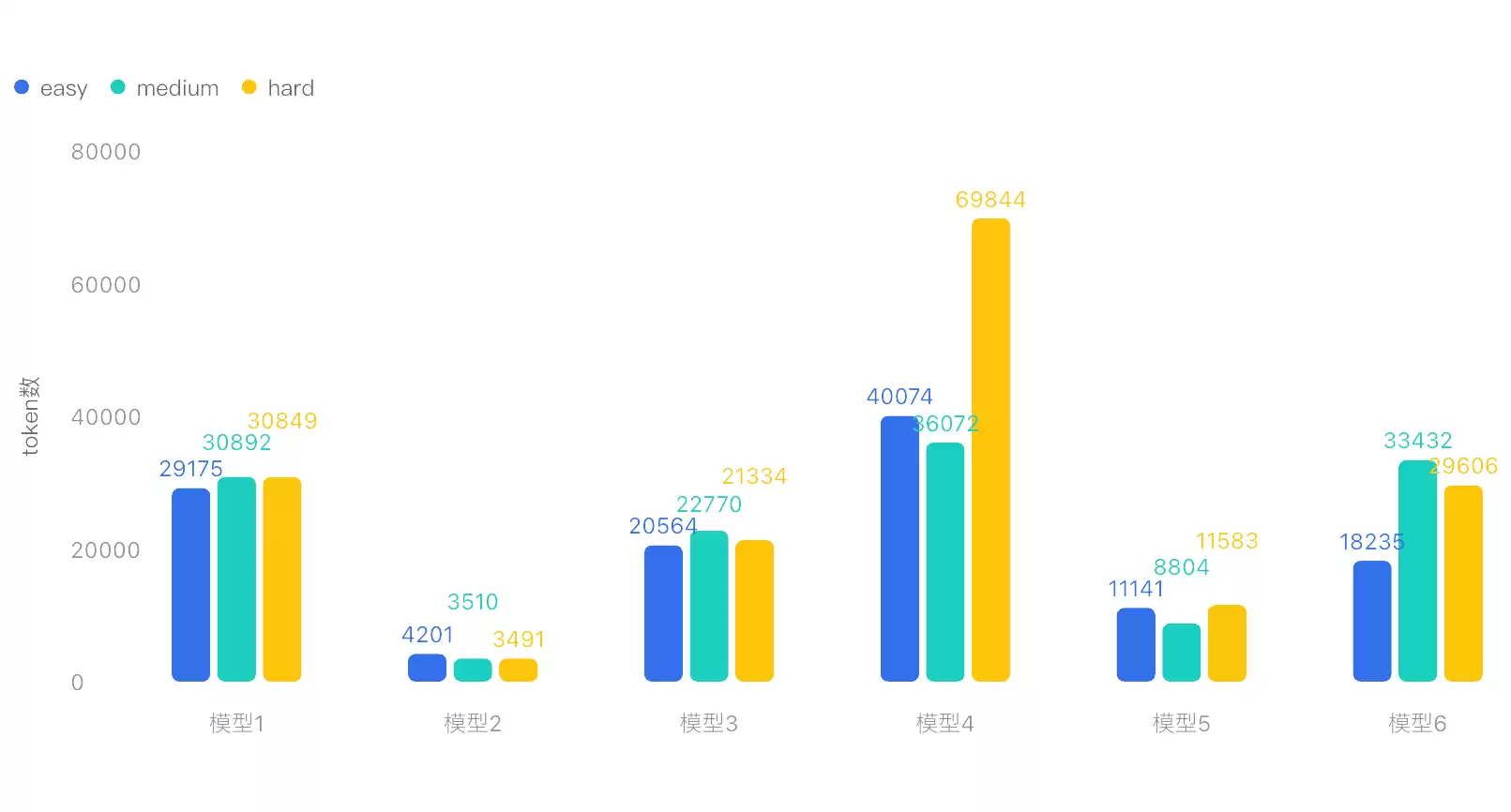
- 所有模型的总分都没能突破50分,但时效性倒是提升了几个量级。
- 相比有经验的运维专家,成功率上仍有明显差距。
下面的图则直观展示了不同难度下各个模型的表现: