人机协同场景下传播动力学的理论迭代研究
谣言、疫情、观点、恐慌与社交媒体情绪——这些看似属于不同领域的现象,本质上都指向同一类问题:某种状态如何在相互作用的个体之间扩散。这正是传播动力学的核心议题,也是数字社会亟待解答的关键难题。
传统研究通常将个体抽象为节点,将接触或影响关系抽象为边,并用感染、恢复、采纳、转发等状态转移来刻画传播过程。这套框架在统计物理、网络科学和流行病学中已经相当成熟。然而,真实传播并不只由网络结构决定。谣言是否被相信,取决于它的叙事方式、情绪强度和群体认知;疫情是否扩散,也受到个体行为、政策理解以及风险感知的影响。这些语义和认知因素,很难被简单压缩成几个固定参数,而这也正是人机协同背景下传播动力学需要突破的瓶颈。
大语言模型(large language models, LLMs)的出现,让传播动力学进入了一个全新的问题域。2026年2月发表于 Physics Reports 的一篇综述指出,LLMs 不再只是外部分析工具,它们正成为传播系统中的主动参与者——生成内容、交互行为和人机反馈,都可能改变传播路径、反馈结构与系统演化方式。这意味着,传播动力学不再是单纯的“节点—边—状态”问题,也开始转向“语义—认知—行为—反馈”的问题。传播内容,不再是被动载荷,而是可以建模、可以生成、可以调控,并反过来改变传播路径的动力学变量。
从网络传播到语义传播
复杂系统的基本思想是:大量个体通过相互作用形成整体行为。疾病在人群中扩散,观点在社交网络中扩散,错误信息在平台中扩散,都可以被看作传播过程。传统传播动力学通常以网络为基础,节点代表个体,边代表接触或影响关系,状态转移则描述个体从易感到感染、恢复,或从未采纳到采纳的变化过程。
在生物流行病中,经典模型包括SIS(易感-感染-再易感)和SIR(易感-感染-恢复)模型。它们强调感染率、恢复率和传播阈值,非常适合描述病原体通过接触网络扩散的基本规律。在数字流行病中,研究对象则是谣言、错误信息、假新闻、观点和行为,常见的是阈值模型和独立级联模型:前者强调多次社会强化后才发生采纳,后者强调每次接触都有一定概率触发传播。这类模型在谣言传播与舆论演化分析中应用广泛。
这些模型的优点很突出:清楚、可计算、可解释。缺点也同样直接:它们通常把传播内容简化成一个标签,把个体行为简化成预设规则。然而,真实社交平台上的传播远不止于此。一条消息是否传播,不仅取决于谁看见了它,还取决于它如何措辞、是否煽动情绪、是否符合受众已有的立场、是否嵌入某种社会语境。传统模型很难自然处理这些语义和认知因素,这也为语义传播研究提供了新的突破口。
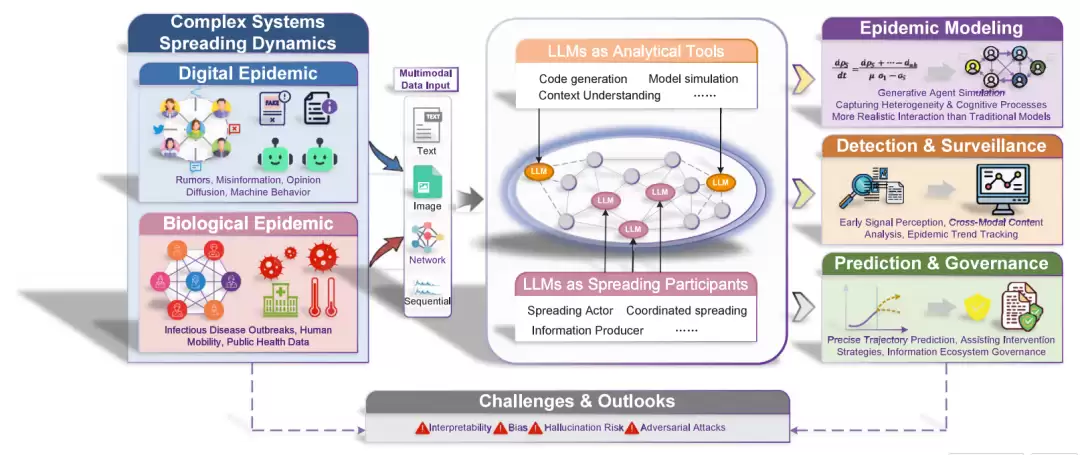
图1. 文章整体框架。左侧区分数字流行病与生物流行病,中间展示文本、图像、网络、时间序列等异质数据,右侧展示LLMs在建模、检测、监测、预测和治理中的作用。
LLMs为什么改变了传播动力学
LLMs的能力来自其训练流程,主要包括预训练、指令微调和基于人类或人工智能反馈的强化学习。在预训练阶段,模型通过大规模文本学习语言规律和世界知识;在指令微调阶段,模型学习如何按照人类任务要求作答;在强化学习阶段,模型根据偏好反馈进一步优化输出,使其更符合有用性、安全性和任务目标。这一机制让LLM具备了处理复杂语义传播场景的能力。
传播动力学之所以会受到LLMs影响,关键在于它们能够处理文本语义、上下文线索、多模态信息和社会情境。对于数字传播,这意味着模型可以识别一条信息中的立场、情绪、叙事逻辑和潜在误导性。对于疫情传播,意味着模型可以从新闻报道、症状描述、公共卫生政策文本、病例时间序列和移动轨迹中提取相关信息,并将这些信息转化为建模所需的结构化表示。这种人机协同能力正在重塑传播研究的方法论。
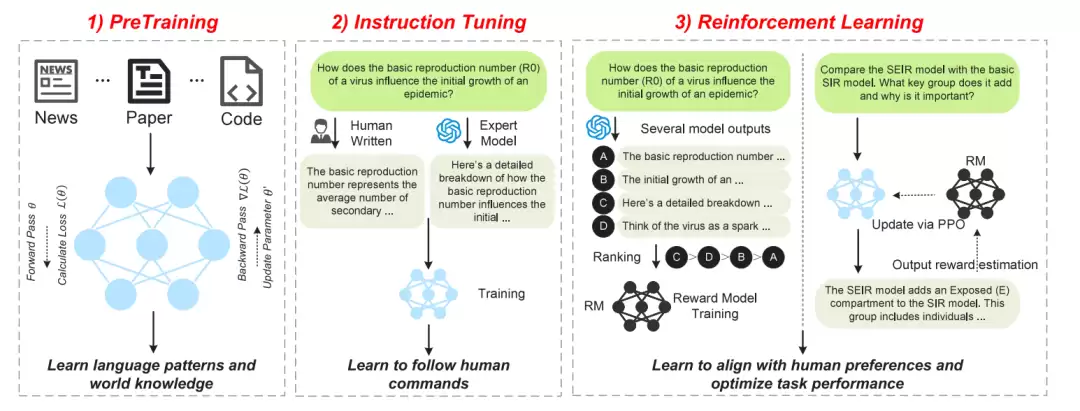
图2. LLMs 通过预训练、指令微调和强化学习获得任务能力。
更重要的是,LLMs并不只是外部分析工具。它们可以生成帖子、回复评论、模拟用户、构造社交网络,甚至通过对话影响人类的风险判断和行为选择。因此,LLMs在传播系统中具有双重身份:一方面是分析工具,另一方面是传播参与者。这改变了传播动力学中的反馈结构——人类生成的数据训练模型,模型生成的内容影响人类行为,人类行为又重新进入数据环境,形成持续的人机共演化(human-AI co-evolution)。这正是人机协同传播动力学的核心特征。
从建模到治理:LLM 如何进入传播研究链条
传统传播动力学通常从预设规则出发:仓室模型规定个体如何感染与恢复,阈值模型和级联模型规定个体如何采纳与转发,基于智能体的模型(agent-based models, ABMs)则进一步为不同个体设定属性和行为规则。这类方法清晰、可控、可复现,但真实传播中的语言表达、情绪动员、社会身份、认知偏见和政策理解,往往难以被压缩成固定参数。而引入LLM后,传播建模开始向语义认知方向演进。
基于LLM的ABM,其关键变化在于:智能体不再只是执行预设的转移规则,而是可以根据身份、立场、知识背景和社会关系进行语言推理,并在传播过程中生成情境化反应。在数字流行病中,这使研究者能够模拟错误信息传播、观点演化、群体极化和回音室效应。在生物流行病中,LLM则可用于刻画个体如何理解风险、响应政策、改变出行和社交行为。也就是说,LLM本身不直接改变病原体的传播机制,但它可以改变人们对疫情信息的理解和行为选择,进而影响接触网络与传播曲线。这就是LLM在疫情传播建模中的独特价值。
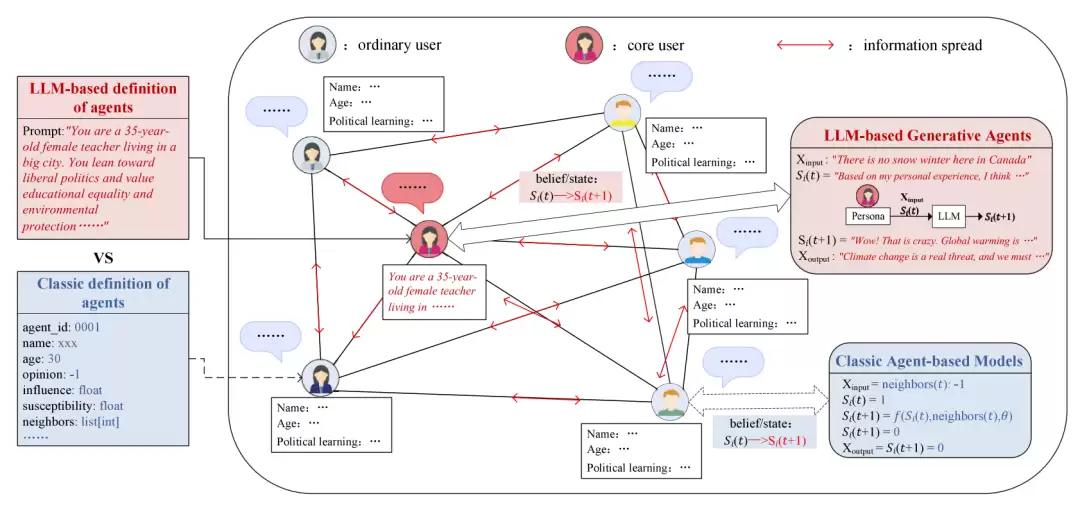
图3. 经典流行病建模与LLM-based流行病建模的对比。
传播研究的第二个环节是检测与监测。传统模型主要关注节点状态和传播规模,而LLM擅长处理传播内容和语境。在数字流行病中,它可以识别文本中的主题、立场、情绪、叙事结构和事实一致性,帮助判断信息是否具有误导性,并进一步分析为什么相信、为什么转发、为什么扩散。在公共卫生场景中,LLM则可以从新闻、社交媒体、论坛帖子和搜索记录中提取早期流行病信号,使监测对象从结构化病例数据扩展到更分散、更噪声化但更接近真实行为的数据源。这种人机协同监测机制正在成为传播治理的新手段。
预测与治理则对应传播研究的下一步:判断接下来会发生什么以及如何干预。LLM可以结合文本语义、用户画像、网络结构和传播历史,预测话题热度、转发概率、级联规模和群体反应。也可以参与事实核查、反驳文本生成、恶意内容识别和公共信息解释。但这一点必须谨慎理解:LLM既可能帮助抑制错误信息,也可能被用于生成更具迷惑性的内容,并通过自动化互动放大特定观点。因此,LLM不只是传播研究的新工具,它也可能成为数字流行病中一种新型的传播因素。在谣言传播治理中,这种双刃剑效应尤其值得关注。
新边界:当 LLM 成为传播系统变量
这篇综述的核心意图,并不是把LLM当作一个更聪明的预测器来简单拥抱,而是要提醒我们:模型本身已经进入了传播现场。过去,研究者关心的是信息如何在人与人之间流动。现在,信息可能先由模型生成,再被人类阅读、转发、质疑或相信,随后又变成新的数据,反过来影响下一代模型。这意味着传播系统多了一个新的回路,人机协同的传播动力学正在形成全新的研究范式。
谣言不再只是人在社交网络中扩散的内容,也可能由模型改写、放大和包装。公共卫生信息不再只是由机构发布、公众接收,也可能经过模型解释后影响个体的就医、出行和防护选择。LLM不一定改变病毒本身,却可能改变人们对病毒的反应;它不一定创造社会情绪,却可能改变情绪被组织和扩散的方式。这些变化使得语义传播与数字流行病的边界日益模糊。
因此,问题不再只是“能不能用LLM预测传播”,而是“当LLM也参与传播时,我们还在研究同一个传播系统吗?”这正是LLMs给传播动力学提出的新边界:传播内容、传播主体和传播环境之间的界限正在变得模糊,而经典模型需要重新回答——语言、认知和生成式反馈,究竟如何进入动力学机制。人机协同场景下的传播理论迭代,已经成为未来研究的重要方向。