长文本正在成为大模型服务的常态。RAG 系统会将大量检索片段拼接进 prompt,编程 agent 会连续调用工具并累积历史上下文,而长会话系统则会把记忆、工具结果和历史状态一并放入同一个输入。随之而来的问题是:输入越长,KV Cache 越大,显存占用、首字延迟(TTFT)、并发能力以及分布式 KV 传输都会受到严重拖累。
传统推理系统通常将 KV Cache 视为一个稠密的 [B, H, L, D] 张量:同一段 token 内,所有注意力头被一起存储、一起搬运、一起计算。但 RedKnot 换了一个视角:KV Cache 的价值并非按 token 均匀分布,而是强烈地按注意力头分化。有些头确实需要查看完整的上下文,有些头则主要关注局部窗口。既然不同头的职责不同,缓存系统也不应将它们捆绑在一起。
基于这一洞察,RedKnot 将 KV Cache 沿着「注意力头」这个维度拆分开来,并配合一套专门的存储与计算机制,在保持输出质量的同时显著提升了效率。论文实验显示,RedKnot 最高可带来 1.6–3.54 倍的 TTFT 加速、4.7–7.8 倍的单卡并发提升,并将预填充阶段的算力(FLOPs)削减 67%–79.5%。
关键词:LLM 推理,KV Cache 优化,长上下文,注意力稀疏化,推理加速
论文地址:
https://arxiv.org/abs/2606.06256
工程项目持续在开源社区维护:
https://github.com/rednote-machine-learning/RedKnot

在长上下文服务里,预填充阶段需要为输入 token 生成 KV Cache。上下文越长,KV Cache 越大,后续注意力计算需要读取的历史状态也越多。这意味着巨大的算力消耗,会显著降低吞吐量。同时,长文本输入会引入一定程度的噪声,即使对文本进行标准的推理,也会因为模型输入自身的噪声而导致推理精度下降。
为了应对这一挑战,业界主要沿两条路线优化:
位置无关 KV 复用(Position-Independent Cache, PIC):相同文档片段即使出现在不同位置,也尽量复用预先计算好的 KV cache,打破前缀的限制。
稀疏化:利用注意力天然稀疏的特性,只保留或重算一部分重要 KV 头的注意力。
但这里存在一个核心错位:如何将 KV cache 按照头进行解耦?问题在于,使用 KV cache 和计算 KV cache 的粒度不匹配——算法知道有些头不重要,存储却还是把所有头绑在同一个 token block 里;算法想表达稀疏,执行时却往往变成稠密布局加 attn_mask。RedKnot 的目标就是将算法、存储和内核的粒度统一到同一个事实上:不同 KV head 有不同的上下文需求。

RedKnot 总结了现有方案的三个核心错配:
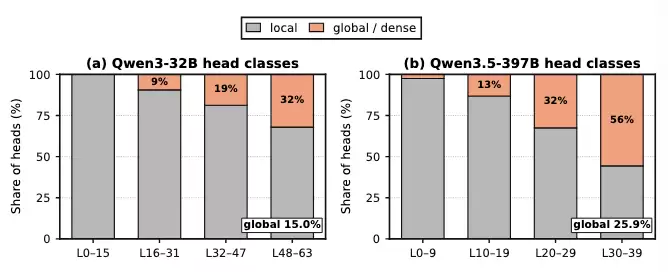
图1
1. 稀疏其实是「按头」的,而恢复却是「按 token」的。现有 PIC 方案在 token 粒度上挑选要重算的子集,但不同的头关注的 token 子集并不相同。要同时满足所有头,系统只能取各头重要 token 的并集——这个并集往往覆盖了片段中很大一部分 token,复用的意义随之被抵消。如图一所示,我们统计了多个模型在多个数据集 LongBench 推理时每个 head 的最重要 tokens(注意力分数大于 95%)的并集,图中清晰显示:在模型的浅层基本上需要重算所有的 token,而深层需要重算的 token 则显著减少。这也解释了为什么 CacheBlend、Epic 和 ProphetKV 这些预先挑选一部分 token 的方法并不可靠。
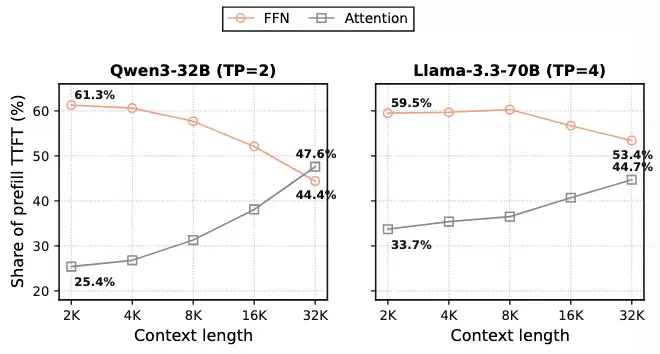
图2
2. 短上下文里,真正的瓶颈是 FFN,而不是注意力。PIC 默认注意力主导预填充开销,但在 agent 场景常见的 2–8K 片段长度下,前馈网络(FFN)贡献了 57%–62% 的 TTFT(图2)。即使把注意力重算降到零,FFN 这块成本也难以撼动。
3. 算法上省了字节,工程上没省算力。即便算法只保留了每个头的一小部分 KV,存储上仍用稠密的 [B, H, L, D] 布局,并在运行时通过 attn_mask 表达稀疏。这会让 PyTorch SDPA 无法走上 FlashAttention 的快速路径,带来 4.9–7.6 倍的内核惩罚(论文 3.4 节)。
三者的共同根源是:现有方法在恢复、计算、存储这三个粒度,都没有和工作负载真实的「按头、按通道」稀疏结构对齐。

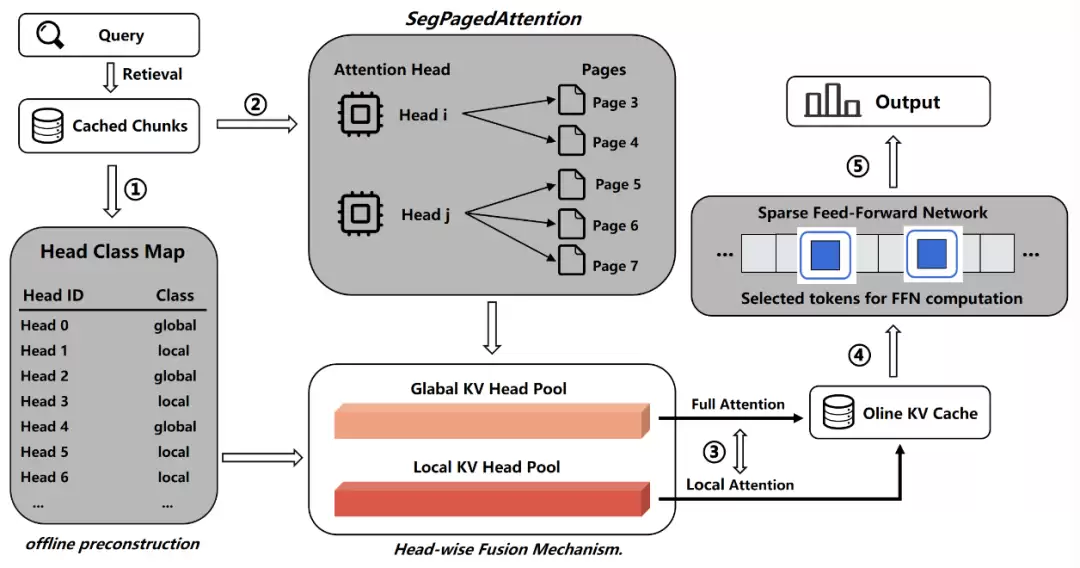
图3
RedKnot 用三个沿正交维度协同设计的机制,把上述三处错位同时对齐(图 3):
头分类稀疏(Head-Class Sparsification)
离线对每个
(层, 头)做一次分类:少数为「全局头」(约占 12%–15%,复用时重新预填充),多数为「局部头」(约占 85%–88%,在滑动窗口内直接复用)。论文图 4 进一步显示,在 Mistral-7B、Qwen3-32B、Llama-3.3-70B、Qwen3.5-397B、DeepSeek-V4-Flash 等代表性模型上,局部头占比为 83.4%–96.8%,全局头仅 3.2%–16.6%。由于分类在请求间是稳定的,离线做一次即可,在线零额外开销。稀疏 FFN(Sparse FFN)
只对注意力得分最高的 top-k token 执行稠密 FFN,其余 token 走残差恒等路径。这条维度与上下文长度无关,因此是加速短上下文 agent 负载的唯一抓手——而这恰恰是注意力侧优化够不着的地方。
SegPagedAttention(存储与执行底座)
它把稠密布局换成「按
(层, 头)分段」的分页 KV 存储,并用一个融合的变长(varlen)注意力内核,物理上只保留每个头真正需要的 token。这样每个头都能留在 FlashAttention 快速路径上,全程不构造attn_mask,内核加速比还会随上下文变长而单调增长——这与「稠密 + mask」方案收益递减的趋势正好相反。
三个机制作用在「头、存储、通道」三条正交维度上,因此它们的收益是相乘叠加,而非互相争抢同一份余量。
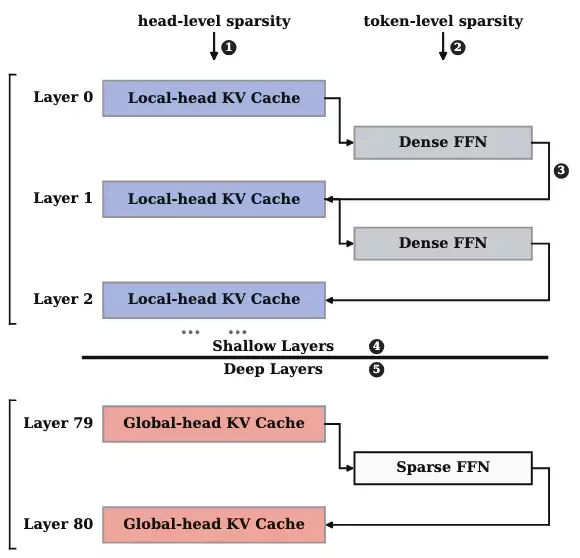
图4
Elastic Sparsity(弹性稀疏恢复)
RedKnot 把恢复拆成三步:RoPE 位置对齐、按头注意力恢复、部分稀疏 FFN 恢复。其中浅层保守——用局部注意力恢复 + 稠密 FFN,保护早期残差流;深层才启用全局头重算 + 稀疏 FFN,因为深层语义选择性更强、注意力更集中,如图4所示。
SegPaged Attention(段页注意力)
RedKnot 在存储层面尝试不按照 token-level 来存储 KV cache,而是按照 head 来存储,因为不同的 head 的 I/O 频率不一样。
架构无关的运行时,RedKnot 不是某个模型专用的稀疏内核,而是围绕「可复用状态对象」构建的通用运行时。通过 PROFILE / BUILDSTATE / SELECTVISIBLESTATE / EXECUTE 四个适配器接口,同一套高层策略可以覆盖标准 GQA 模型、Qwen3.5 这类混合注意力 + MoE 模型,以及 DeepSeek-V4 这类 MLA 压缩注意力模型(详见论文第四章节)。

RedKnot 基于 SGLang 实现,在 8 卡 NVIDIA H800(80 GB)服务器上,跨 3 个模型、6 个 QA 数据集、8K–128K 上下文做了评测。论文报告的主要结果包括(数据仅供参考,以开源社区实测为准):
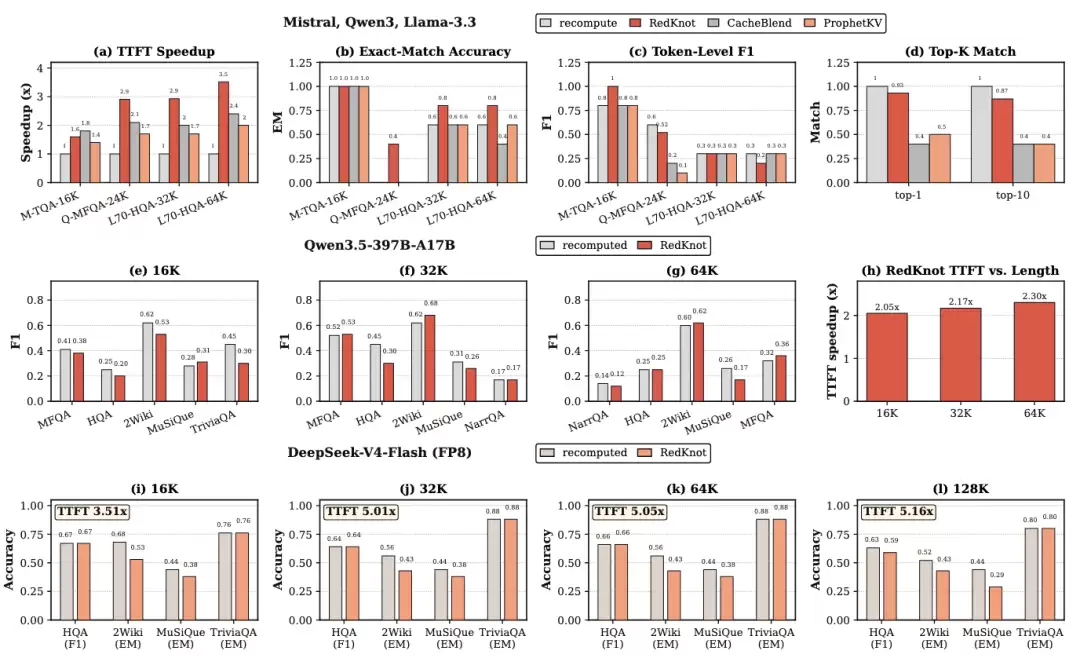
图5
质量优秀。在 Llama-3.3-70B HotpotQA 上,RedKnot 把精确匹配(EM)从稠密基线的 0.60 提升到 0.80;首字 top-1 / top-10 与稠密路径的一致性达到 0.93 / 0.87,远高于 token 级基线(≤ 0.5)。整体精度通常达到稠密 F1 的 95% 以上。
稀疏即降噪。上下文越长,注意力越集中。RedKnot 在长上下文区间上的准确率反而能「反超」稠密计算——因为它在抑制低价值 token 噪声的同时保留了高质量的注意力结构。
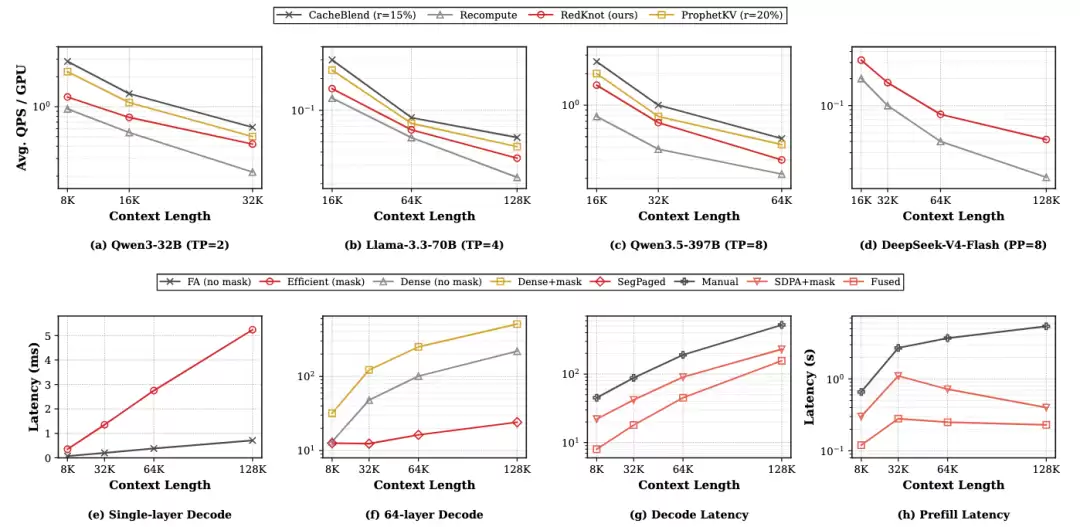
图6
速度更快。TTFT 加速在长上下文下尤为明显,DeepSeek-V4-Flash 上从 16K 的 3.51 倍升到 128K 的 5.16 倍,且加速比随上下文增长而提升,而 token 级基线则趋于饱和。
系统收益。SegPagedAttention 在内核微基准上把 64 层预填充从 5.42 秒降到 0.23 秒(128K,约 23.3 倍);PD 分离场景下,KV 传输字节最多节省 6.3 倍;单卡并发会话数在 32K 上下文下从 4 提升到 31。

RedKnot 给出的更大启示是:下一代推理引擎不应再围绕「稠密层、稠密序列、仅前缀命中」来组织。不同的头需要不同的上下文范围,不同的片段有不同的复用寿命,不同的 token 贡献的有效信号也截然不同。论文将方向归纳为:让 head-aware KV 成为引擎的一等公民、让位置无关 KV 复用成为默认缓存契约、引入跨注意力与 FFN 的「噪声感知调度」,并最终走向一个统一的稀疏服务栈。有望打造下一代以「稀疏层、稀疏序列、任意位置可复用KV」为核心的推理新架构。