DeepSeek 近日开源了 DeepSpec 代码库及配套论文DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation。论文作者列表中间出现了梁文锋的名字,目标非常直接:让 DeepSeek-V4 这类大模型在线上高并发生成时,吐 token 更快。

论文给出的核心成果是,在 DeepSeek-V4 serving system 的 live user traffic 下,相比此前生产基线 MTP-1,DSpark 在 matched throughput levels 下让单用户生成速度提升了 60%-85%。
Fireworks AI 联合创始人兼 CTO、PyTorch 核心维护者 Dmytro Dzhulgakov(下称 Dmytro)也在 X 上发了一系列推文,把这篇论文拆解成 10 个概念。
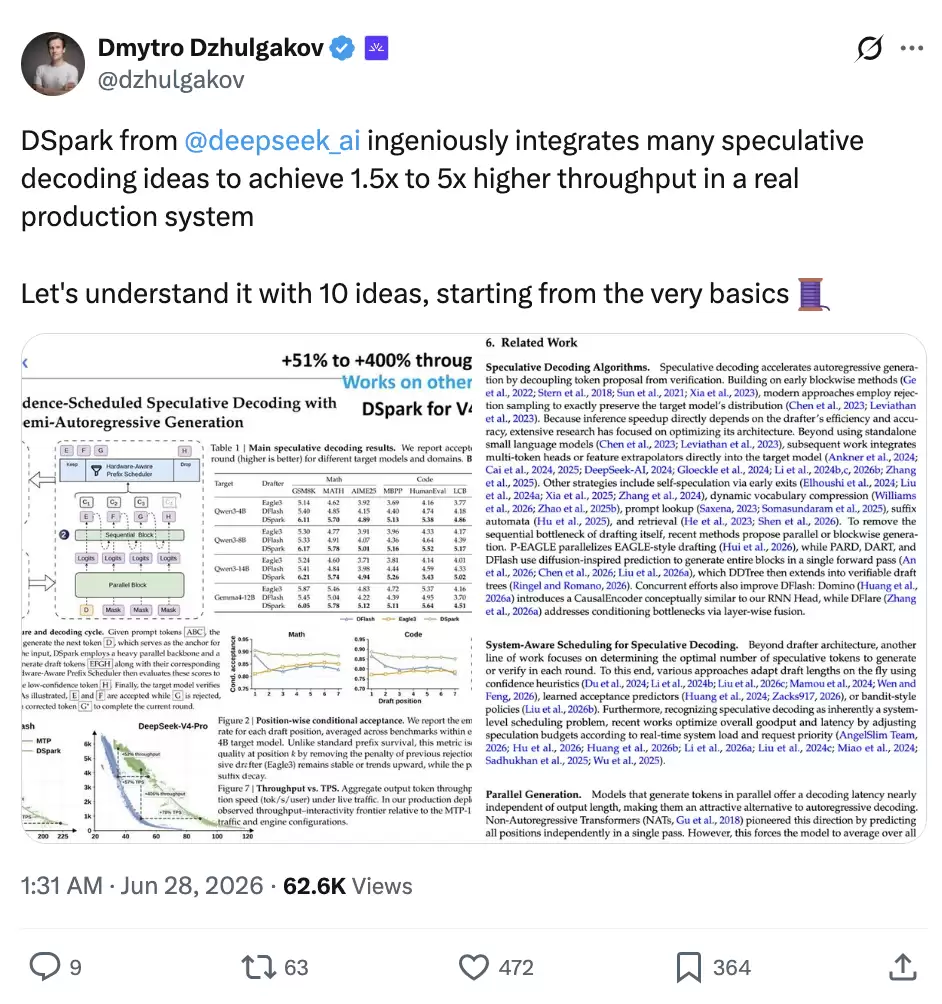
这 10 个概念的排序很有深意:先从 LLM 解码阶段的访存瓶颈和批处理机制讲起,再进入推测解码、草稿器、旧方法的取舍,最后落到 DSpark 的结构、硬件感知调度和在线校准。按这个顺序看下来,DSpark 更像一套围绕“猜得快、猜得准、验得聪明”搭建起来的推理系统。
1. Batching in LLM decoding:GPU 为什么适合批量处理 token
大模型解码阶段有一个容易被忽略的事实:很多时候,GPU 的瓶颈压根不在算术运算上,更多发生在模型权重从显存搬到计算单元附近的过程中。
这就解释了为什么一次处理 10 个 token,通常不会比处理 1 个 token 慢上 10 倍。权重已经被读出来了,如果能让它服务更多的 token,硬件利用率自然会更高。
线上推理里的连续批处理,利用的正是这个特性。服务端把不同用户、不同请求的 token 塞进同一个 batch,让一次前向计算处理更多工作。DSpark 后面所有设计,都建立在这个基础上:候选 token 如果能被批量验证,验证成本就不会按候选数量线性增长。
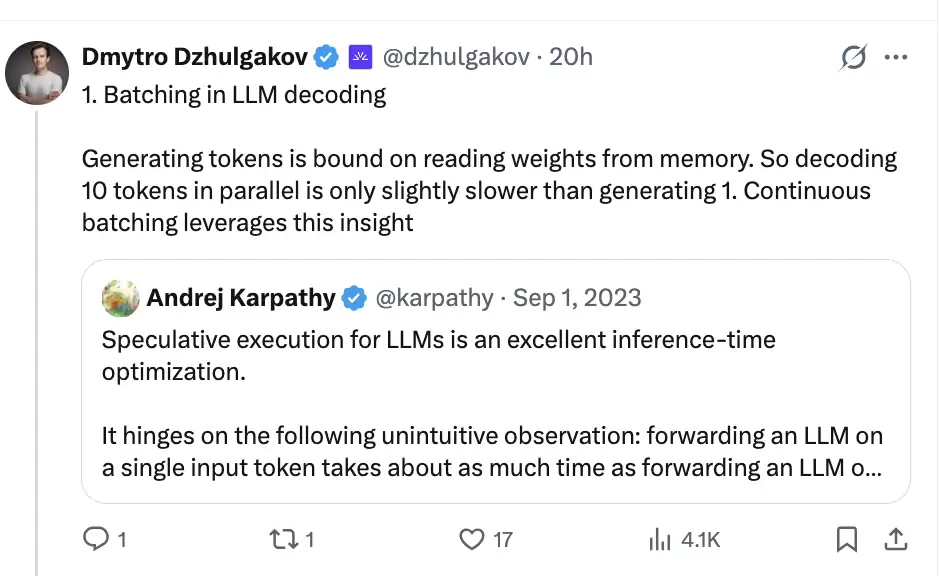
2. Speculative decoding:先猜,再让大模型验
大模型正常生成是自回归的。第 N+1 个 token 依赖第 N 个 token,所以自然流程只能一步一步往前走。
推测解码绕了一下路:先让一个更便宜的草稿器猜出后面几个 token,再让目标大模型批量验证这串候选。验证时,系统从开头算起,接受最长正确前缀;遇到第一个分歧点,由目标模型重新采样。
这套方法把生成拆成了两个角色:草稿器负责“猜”,目标模型负责“验”。如果草稿器猜得准,一轮验证就能前进多个 token;如果猜得不准,后面的候选会被拒绝,加速收益自然也会下降。
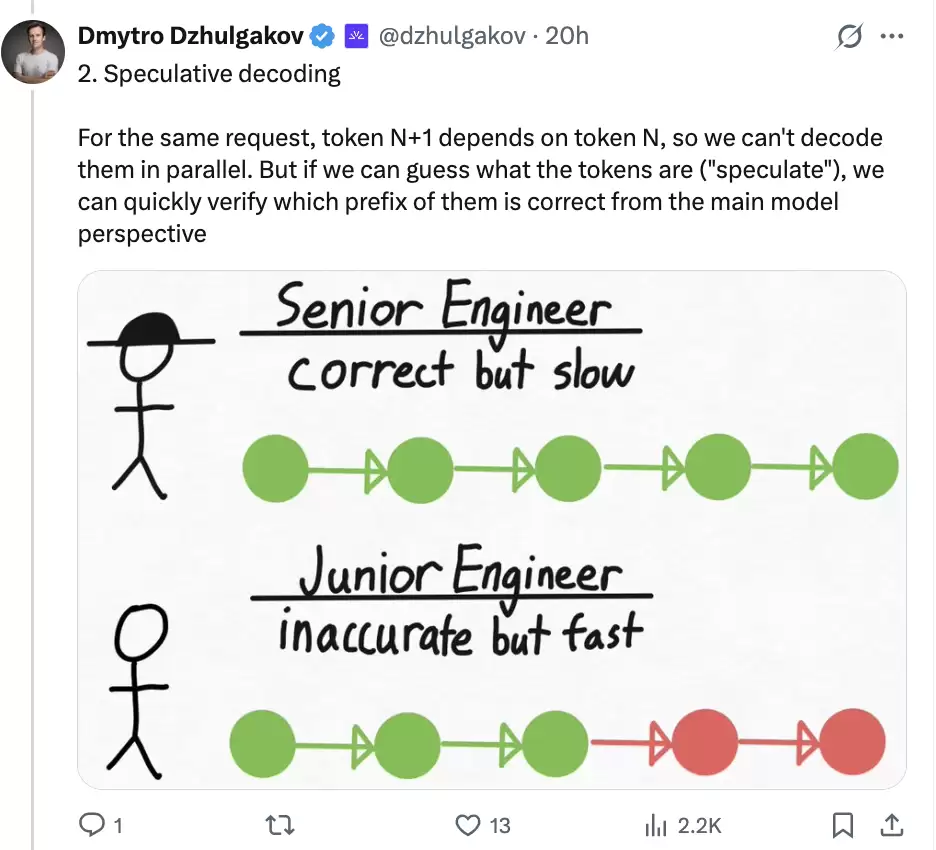
3. Draft model:草稿器可以是一颗小模型
最直接的草稿器,就是一颗更小的模型。
Dmytro 举的例子是,用 Qwen 0.8B 给 Qwen 397B 探路。小模型速度快,先生成候选;大模型再做一次批量验证。通过的候选直接收下,遇到第一个分歧点,再由大模型重新生成。
这个设计很直观,但要让两者配合好并不容易。草稿器得足够快,否则节省下来的验证时间会被草稿生成时间吃掉;草稿器也得足够贴近目标模型,否则猜出来的 token 经常被拒绝,batch 资源还是会被浪费。
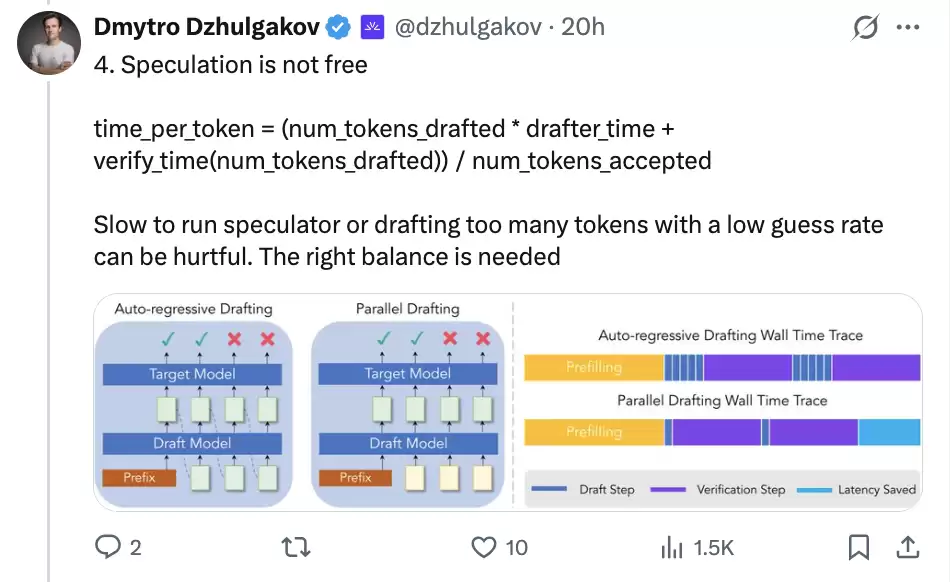
4. Speculation is not free:推测也要算成本账
DSpark 论文里有一笔很重要的账:
time_per_token =
(num_tokens_drafted * drafter_time + verify_time(num_tokens_drafted))
/ num_tokens_accepted每个 token 的平均耗时,取决于草稿生成成本、验证成本,以及最终被接受的 token 数量。
如果草稿器自己很慢,drafter_time会吃掉收益;如果一次猜了很多 token,但只有前几个被接受,num_tokens_accepted会变小;如果验证长度太长,低质量后缀大概率被拒绝,却仍然占用了 batch 资源,verify_time就会被浪费。
所以 DSpark 要解决的问题,比“能不能多猜几个 token”复杂得多:三笔账必须同时算清楚。
| 要拉动的杠杆 | 对应问题 |
|---|---|
| 猜得快 | 草稿器本身不能拖慢生成 |
| 猜得准 | 每轮要有更多候选 token 被接受 |
| 验得聪明 | 验证资源不能浪费在低概率后缀上 |
后面的几个概念,实际上就是围绕这三笔账展开的。
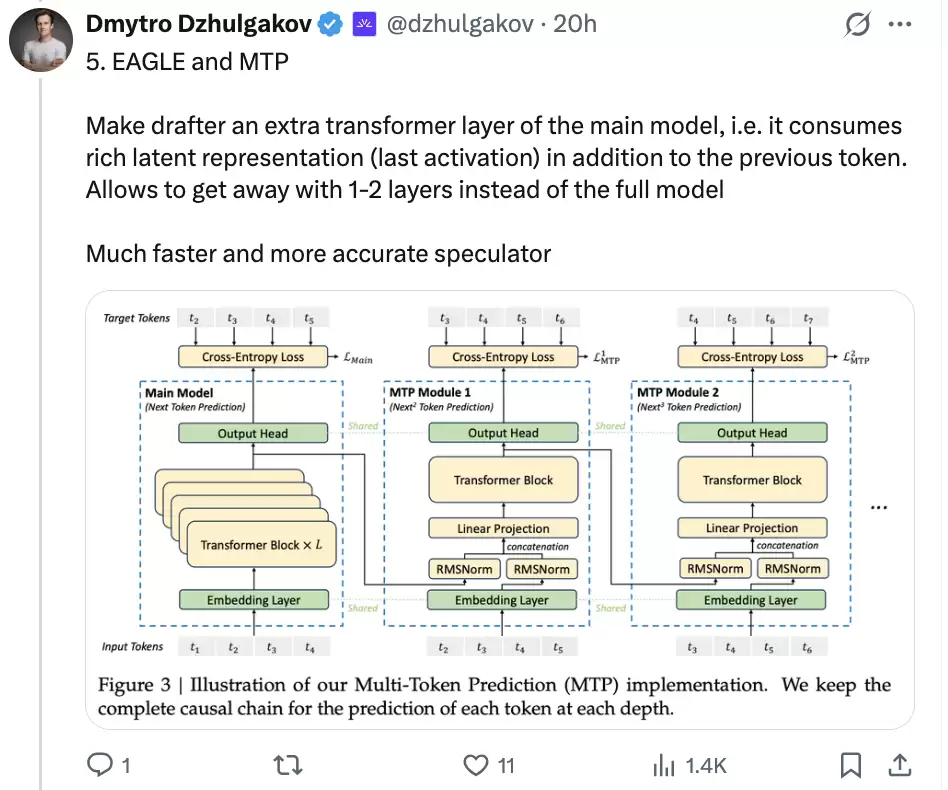
5. EAGLE and MTP:复用目标模型的内部表示
第五个概念开始进入草稿器本身。
EAGLE 和 MTP 的思路,不是从零训练一个完整小模型,而是把草稿器做成目标模型上的额外轻量层。它可以利用目标模型最后一层激活等 latent representation,再结合前一个 token 来预测后续 token。
这样做有两个好处。第一,草稿器只需要很少的层数,速度比完整小模型更快;第二,它吃到的正是目标模型自己的内部表示,猜测分布更接近目标模型,候选更容易被接受。
DeepSeek-V3 已经用过 MTP 做单 token 推测。DSpark 论文里的生产基线 MTP-1,也正是后面所有线上对比的参照物。换句话说,DSpark 那 60%-85% 的单用户速度提升,起点是 MTP-1 这个已经投入生产的基线。
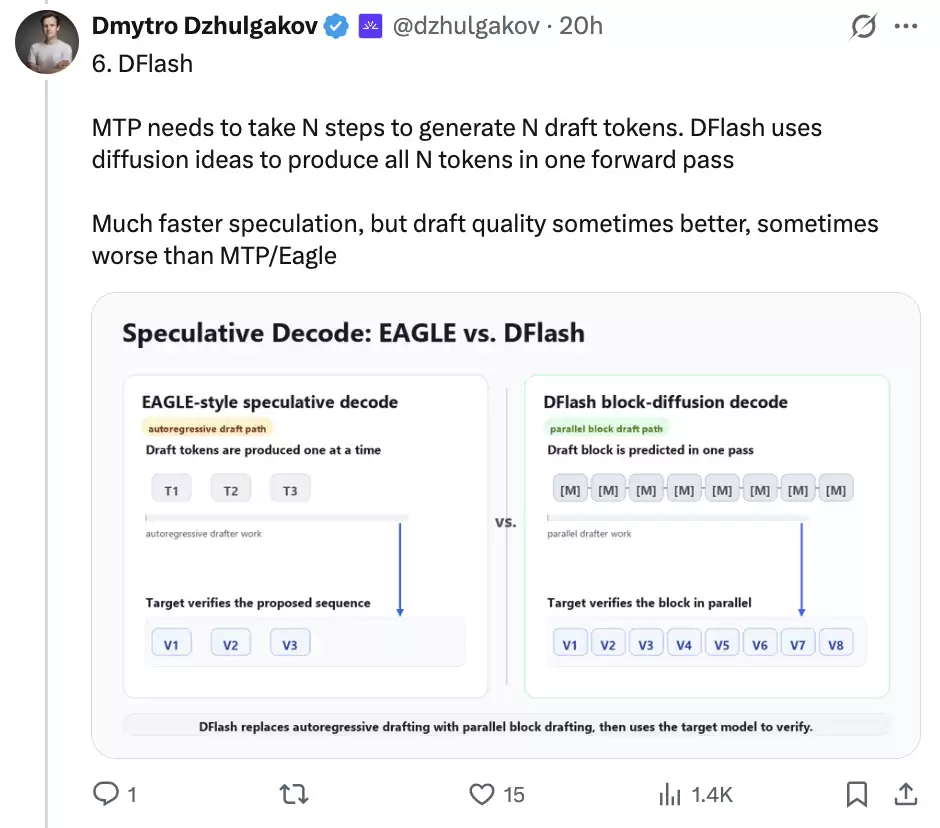
6. DFlash:一次并行猜一段
EAGLE/MTP 更准,但它仍然偏串行。要猜第 2 个 token,先要有第 1 个 token;要猜第 3 个 token,又要等第 2 个 token。候选越长,草稿过程越拖。
DFlash 走的是另一条路线:借鉴并行生成思路,一次前向就把多个候选位置同时产出。
它的速度优势很明显。多个候选 token 一起出来,不用一步一步等。但问题也随之出现:每个位置独立预测,后面的 token 缺少前面已采样 token 的约束,候选序列越往后越容易跑偏。
论文里把这种现象称为 acceptance decay。可以把它理解成“后缀接受率衰减”:前几个 token 还比较准,后面的 token 因为缺少前缀依赖,更容易被目标模型拒绝。
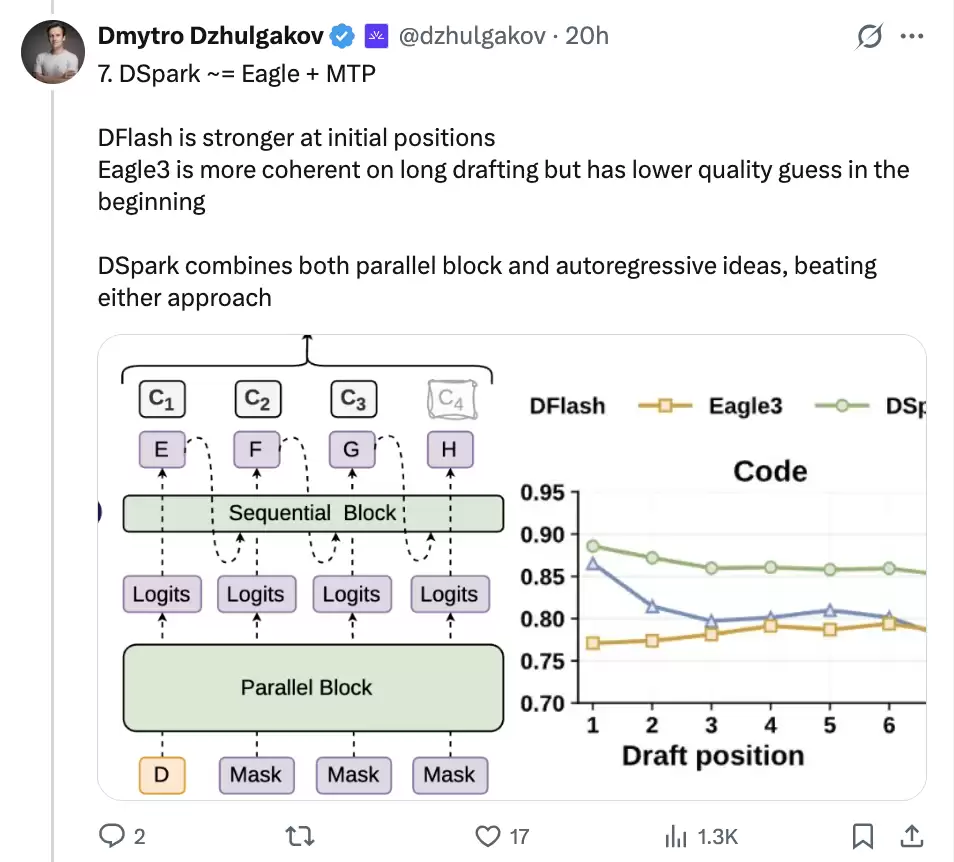
7. DSpark = EAGLE + DFlash:先并行,再轻量纠偏
第七个概念才真正进入 DSpark。
DSpark 的结构可以分成两步。第一步,用 Parallel Block 一次性给出一段候选 token 的基础 logits,保住 DFlash 那种并行草稿速度。第二步,用轻量 Sequential Block 从前往后修正候选,让后面的 token 能看到前面已经采样出来的 token。
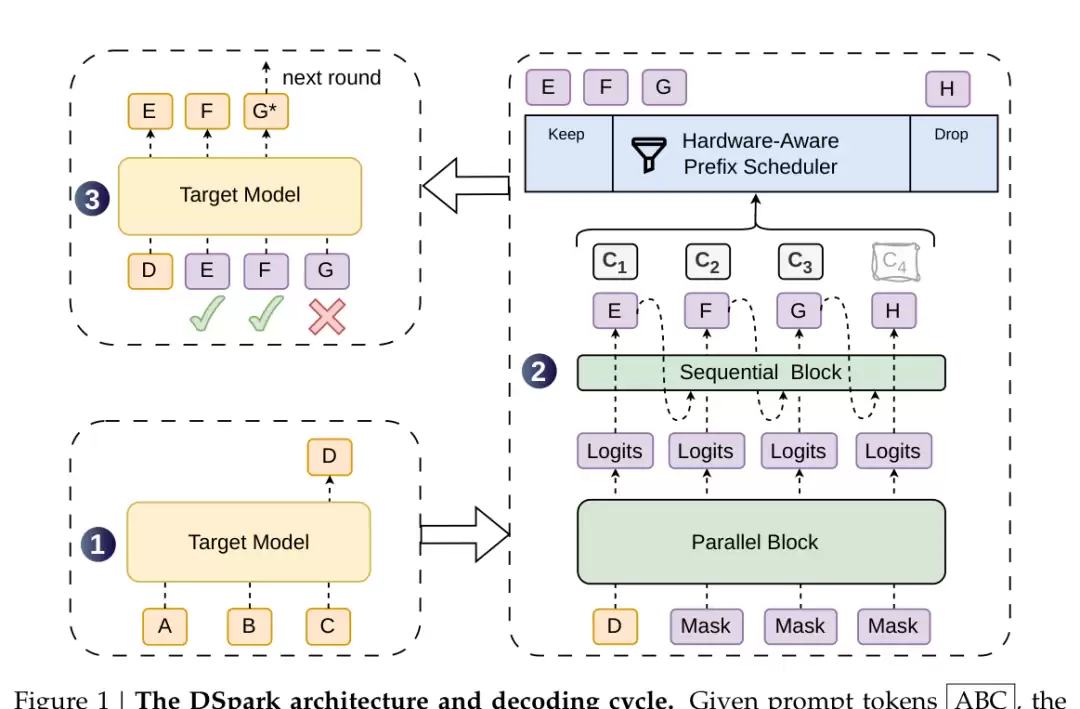
这一步对应前面两笔账:并行骨干负责“猜得快”,顺序修正负责“猜得准”。
如果用 DFlash 的纯并行方式,后面位置可能各猜各的,形成不自然的组合;DSpark 的顺序修正会把前面已经采样出来的 token 信息注入后续位置,让候选序列更像一个连贯的前缀。
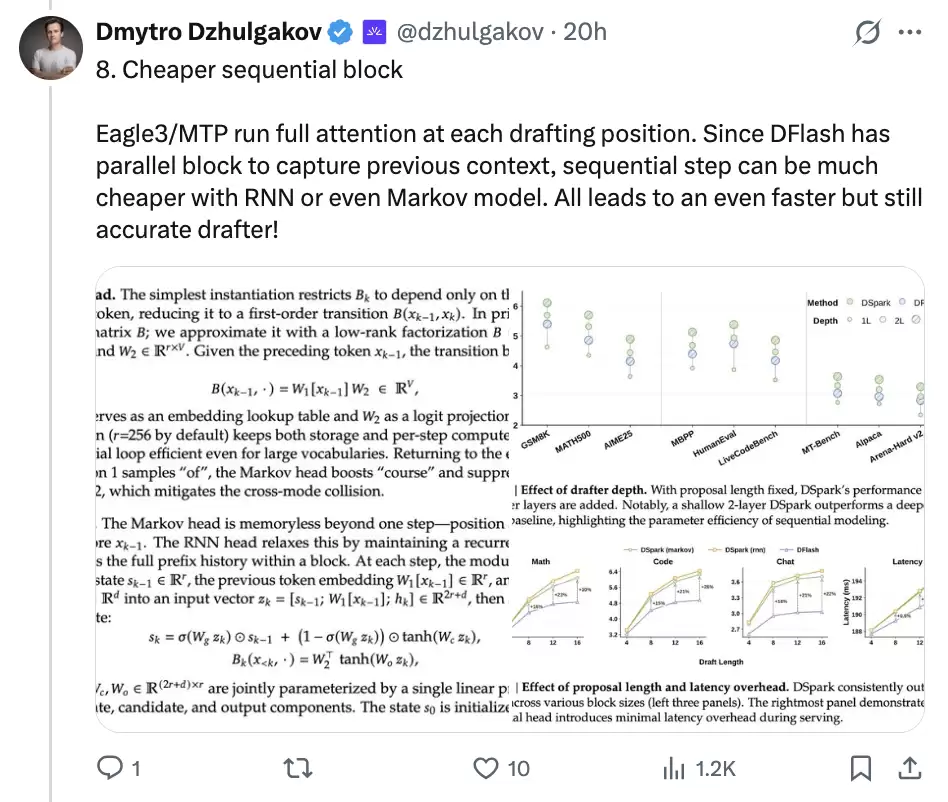
8. Markov head:把顺序修正做轻
顺序修正听起来会带来新的串行成本。DSpark 的第八个概念,解决的就是这个问题。
论文里给了两种 Sequential Block:
| 结构 | 作用 |
|---|---|
| Markov head | 只看前一个 token,用低秩转移矩阵修正当前位置 logits |
| RNN head | 维护 recurrent state,能追踪更长的块内前缀信息 |
默认方案更偏向 Markov head。原因很工程化:它足够轻。论文提到,rank 默认设为 256,即使词表很大,额外计算成本也能控制得住。
这也是 DSpark 的一个关键取舍。顺序模块没有被做重,只补足并行草稿最缺的那一部分前缀信息。这样并行速度没有被吃掉,后缀接受率又能被拉回来。
9. Variable-length drafting and hardware-aware scheduling:验证长度跟着请求和负载走
到这里,草稿器已经更快、更准,但第三笔账还没有结束:每轮到底该验证多长?
固定长度并不合适。代码生成、数学推理这类任务通常更受上下文约束,后续 token 更容易被猜中;开放聊天分叉更多,长后缀更容易被拒绝。同一个系统在低并发和高并发下,也不该使用同一套验证预算。
低并发时,GPU 还有余量,多验几个候选问题不大;高并发时,每个验证 token 都在占用 batch capacity。如果低置信度后缀大概率会被拒绝,还把它塞进验证 batch,就会拖慢整个系统。
DSpark 因此给每个候选位置加了置信度估计,预测这个位置以及它之前的前缀能否存活下来。只看置信度还不够,它还引入 Hardware-Aware Prefix Scheduler,预先测量不同 batch size 下的 engine throughput,运行时根据候选置信度、当前 batch 状态和硬件吞吐曲线,决定每条请求保留多长前缀去验证。
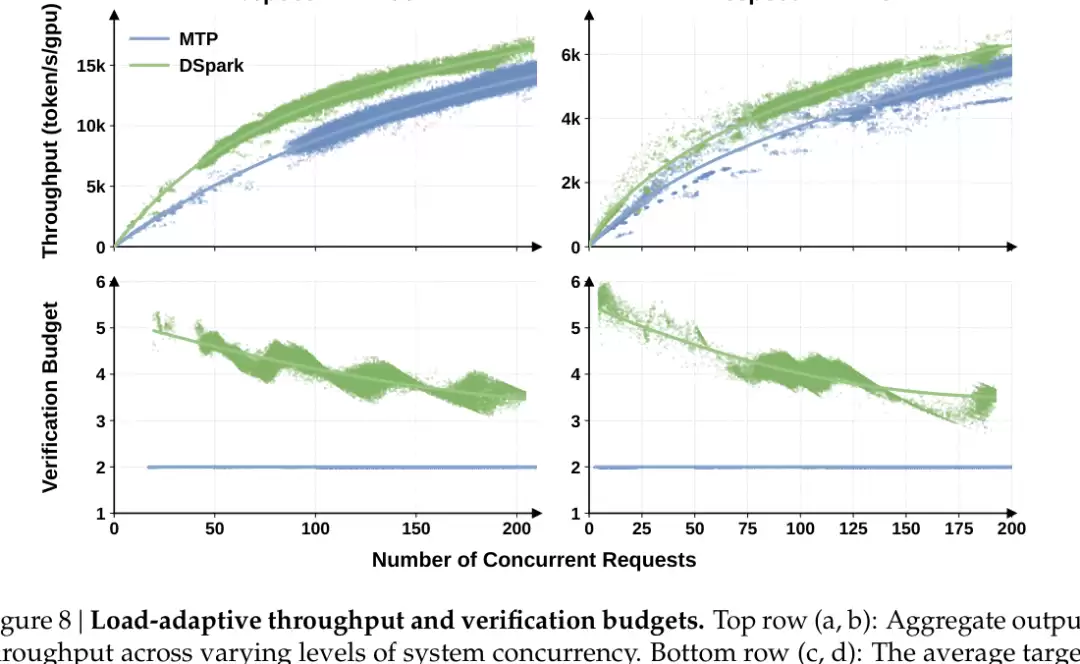
这张图解释了 DSpark 的调度思路:系统空闲时,可以给请求更长的验证预算;系统拥挤时,就更早丢掉低置信度后缀,把验证资源留给更可能被接受的 token。
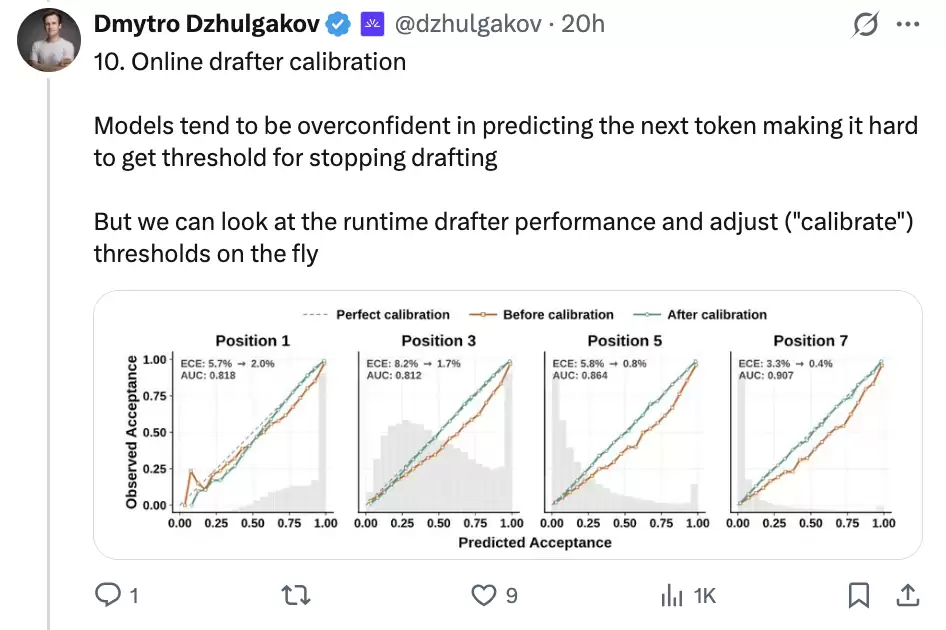
10. Online drafter calibration:让置信度在线校准
最后一个概念是在线校准。
置信度头本身也会出问题。神经网络经常过度自信,如果草稿器觉得每个候选都靠谱,调度器就会放过太多低质量后缀;如果它过度保守,又会浪费本来可以被接受的 token。
DSpark 使用顺序温度缩放做后处理校准。论文图 6 提到,校准前 expected calibration error 大约在 3%-8%,校准后可以降到约 1%。这一步看起来不如模型结构显眼,但在线上系统里很关键。调度器每一次判断,都会影响 batch 里到底塞哪些 token;置信度一旦不准,硬件感知调度也会跟着跑偏。
这 10 个概念回答的是 DSpark 为什么可能更快:候选 token 怎么来,后缀怎么修,验证长度怎么定,置信度又怎么校准。
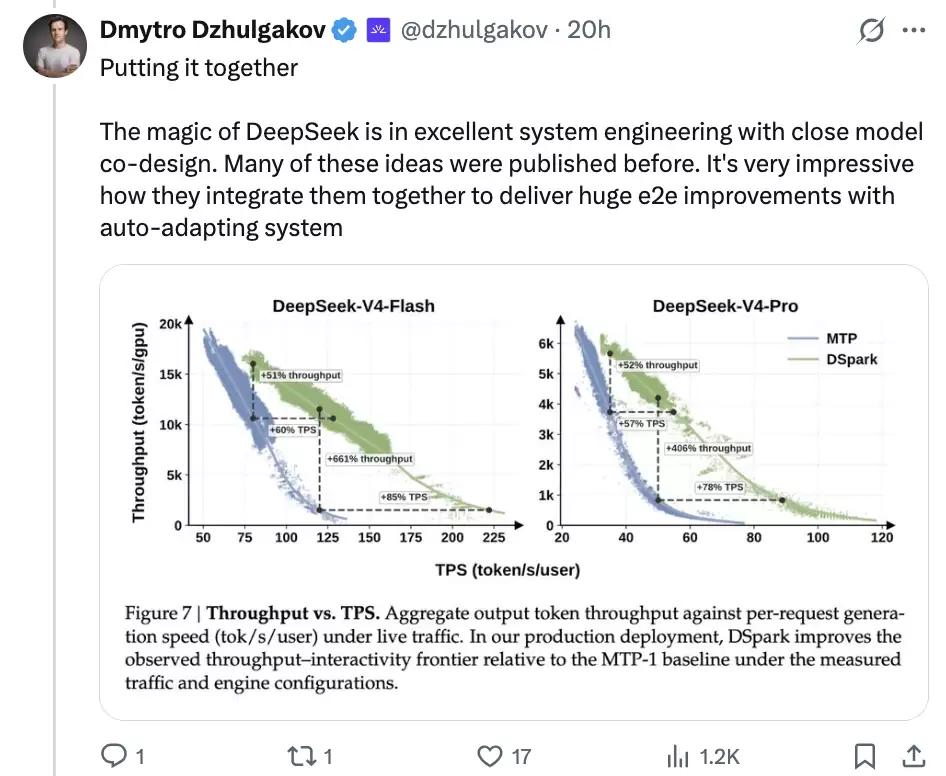
最后,我们再来看一下论文里的两组实验结果。第一组是离线 accepted length,验证 DSpark 的候选前缀是不是真的更容易被目标模型接受;第二组是 DeepSeek-V4 生产 serving 结果,验证这套机制放到真实流量里能不能换来吞吐和单用户生成速度的提升。
离线结果:accepted length 同时超过 Eagle3 和 DFlash
论文先看离线指标 accepted length,也就是每轮推测解码平均被目标模型接受多少个 token。
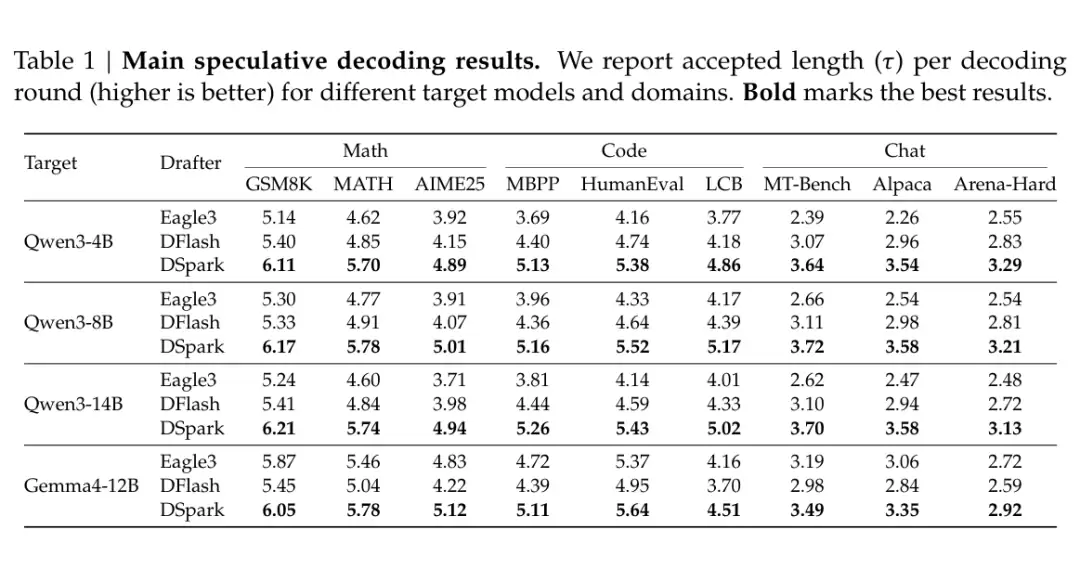
在 Qwen3-4B、Qwen3-8B、Qwen3-14B 上,DSpark 相比 Eagle3 的 macro-a verage accepted length 分别提升 30.9%、26.7%、30.0%;相比 DFlash 分别提升 16.3%、18.4%、18.3%。Gemma4-12B 上也有一致的收益。
这个结果和前面的机制能够对上:Eagle3 有顺序依赖,但草稿更串行;DFlash 并行更快,但后缀接受率会衰减;DSpark 把并行草稿和轻量顺序纠偏放在一起,离线接受长度自然更高。
线上结果:V4-Flash 60%-85%,V4-Pro 57%-78%
更关键的是生产环境的表现。
DSpark-5 被部署到 DeepSeek-V4-Flash preview 和 DeepSeek-V4-Pro preview 的生产 serving engine 中,对比此前生产基线 MTP-1。论文强调,这部分数据来自 live user traffic 下的 telemetry data。
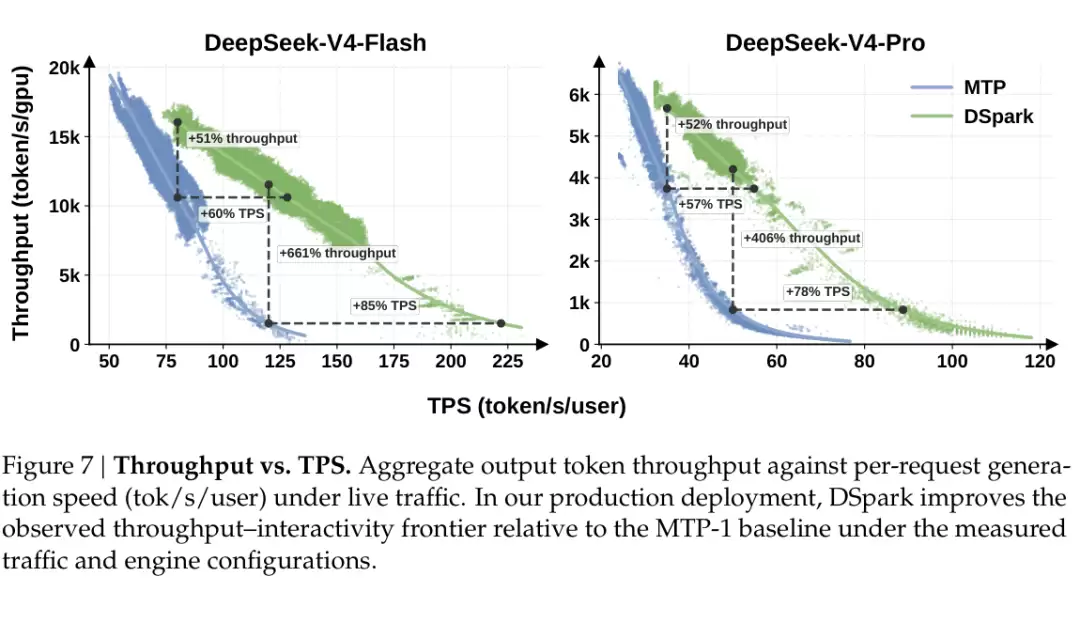
V4-Flash 上,在 80 tok/s/user 的 SLA 锚点,DSpark 相比 MTP-1 提升 51% 的 aggregate throughput;在更严格的 120 tok/s/user 锚点,论文给出 661% 的 nominal throughput 提升。按 matched practical throughput levels 口径来看,DSpark 让 V4-Flash 的单用户生成速度提升了 60%-85%。
V4-Pro 的趋势类似。在 35 tok/s/user 的 SLA 锚点,aggregate throughput 提升 52%;在 50 tok/s/user 的严格 SLA 下,论文给出 406% 的 nominal throughput 提升。按 matched practical throughput 口径看,V4-Pro 的单用户生成速度提升了 57%-78%。
这里需要注意一下口径。661% 和 406% 这类数字来自严格 SLA 下的 nominal throughput 对比,更适合理解为 DSpark 能支撑 MTP-1 很难高效支撑的交互区间;不能简单理解为所有场景下吞吐都翻了几倍。更稳妥的说法仍然是:在论文定义的 matched throughput / SLA 口径下,DSpark 明显提高了 V4 系列模型的线上生成速度。
总结
DSpark 真正值得关注的地方,已经超出了某个模型结构本身:它把模型、推理算法和线上 serving 系统放在一起通盘优化。
从这组 10 个概念来看,它的逻辑是连续的:GPU 批处理让批量验证有意义,推测解码把生成拆成“猜”和“验”,草稿器决定候选质量,成本公式提醒推测会有额外开销,EAGLE/MTP 和 DFlash 分别代表“更准”和“更快”的旧路线,DSpark 再用并行骨干、Markov head、硬件感知调度和在线校准,把这两条路线接到了生产系统里。
大模型竞争进入 V4 这类阶段后,能力之外,谁能把 token 更快、更稳、更便宜地服务出去,正在变成另一条主线。
参考链接
- Dmytro Dzhulgakov 关于 DSpark 的 X 系列推文:https://x.com/dzhulgakov/status/2070922887595499930
- DeepSpec GitHub:https://github.com/deepseek-ai/DeepSpec
- DSpark 论文 PDF:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
- DeepSeek-V4-Flash-DSpark:https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash-DSpark/tree/main
- DeepSeek-V4-Pro-DSpark:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark/tree/main
- DeepSeek-V4 arXiv:https://arxiv.org/abs/2606.19348