对称性在深度学习领域一直是一个引人入胜的话题。从科学计算到医学影像分析,这一概念几乎渗透到了每一个子领域。然而,一个经久不衰的争论始终存在:我们究竟应该将对称性像“紧箍咒”一样直接嵌入神经网络架构(即构建等变神经网络),还是更省事一些,让模型通过数据增强自行学习这些对称性?
理论研究者自然倾向于前一种方法——它严谨规范、便于分析。而数据增强则显得棘手得多,因为要分析它,就必须深入训练动态的复杂泥潭。不过,近期有研究指出,一个无限深的深度集成,从期望角度看,实际上是完全等变的。这条线索极具启发性。受此启发,我们系统地研究了用变分推断训练的贝叶斯神经网络(BNNs)在数据增强下的表现,特别是当变分分布属于指数族时。我们的目标是明确:要达到完全等变性,需要满足哪些条件。
沿着这一思路,我们不仅推导出了等变误差的理论界限,还顺势提出了三种对称化新方法——几何平均、投影和轨道扩展——专门用于在此场景下提升数据增强的效果。大量实验表明,其中“轨道扩展”方法在等变性和整体性能上,均显著优于其他基线方法。


1 引言
对称性在深度学习任务中正受到越来越多的关注。早期,研究者们主要聚焦于如何将对称性约束逐层嵌入网络,从而催生了大量专用的等变网络。然而,近期风向有所转变,更多人开始探索通过数据增强来“偷懒”式地学习对称性。
这种做法的优势显而易见:只要具备数据变换能力,实现起来简单直接,还能直接与那些经过千锤百炼、性能优异的现成架构搭配使用。当然,天下没有免费的午餐。由于对称性是从数据中“学”来的,而非“与生俱有”,因此它只能是近似成立。这引出了一个关键问题:如何提高从增强训练中获得的对称性“质量”?这需要新的方法来解决。
反过来看,显式的逐层等变网络在理论分析上非常顺手,而数据增强则复杂得多,因为任何分析都必须考虑训练动态。不过,一个关键发现是:如果对初始化过程取期望,数据增强实际上可以带来完全等变性。要近似计算这个期望值,一个成本高昂但直接的方法是训练一个深度集成。
我们这篇工作的核心目标是:寻找一种更经济的途径来实现这种“期望中的等变性”。具体来说,我们在增强后的数据上,使用变分推断来训练贝叶斯神经网络。在这种设定下,从后验预测分布中采样,不仅替代了集成推理步骤,还顺便提供了贝叶斯不确定性估计。更重要的是,整个流程只需一次训练就能获得变分后验,而深度集成需要为每个集成成员单独运行训练。此外,BNN 在处理分布外数据方面以稳健著称,因此特别适合数据量不大、但数据增强最能发挥威力的场景。
简要概括我们的主要贡献:
* 我们深入分析了在增强数据上训练的 BNN,其变分分布来自指数族。结果表明,只要训练从一个不变的先验出发,在几个温和的假设下,变分分布在训练全程都能保持等变性。这相当于将 Nordenfors 等人早期针对非贝叶斯网络训练的结果,推广到了贝叶斯场景。 * 如果先验不是等变的,我们也给出了变分分布偏离等变性的理论界限,并证明了因有限采样导致的预测等变误差的界限。这些理论分析均在实验中得到了验证。 * 我们一口气介绍了三种对称化操作:几何平均、投影和轨道扩展。这些操作可以在训练期间直接使用,以改善 BNN 的等变特性。在大量图像分类实验中,我们测试了这些技术,发现轨道扩展方法在模型性能和等变性方面均超过了其他基线。2 相关工作
等变神经网络
深度神经网络的对称性问题——即不变性和等变性——已经发展成一个名为“几何深度学习”的完整子领域。最经典的构建等变网络的方式是逐层构造。这条思路源于群卷积神经网络,但如今,它已经能够处理几乎所有群所能表达的对称性。当然,还有别的方法,比如从不变量中学习、通过帧平均、基本域投影或群平均来实现。也有些研究尝试近似地强加对称性,例如所谓的“权重退火”。
数据增强与训练动态
关于数据增强对神经网络训练动态的影响,已有学者在一些简化情境下进行过探讨,例如特征平均模型和线性神经网络。在这些情况下,通常可以证明数据增强与等变性是等价的。对于完全非线性网络的研究,我们将其推广到了贝叶斯网络。至于数据增强与“硬约束”孰优孰劣,经验性研究文献很多,但更系统的探讨可参考 Gandikota 和 Gerken 等人的工作。
贝叶斯神经网络
深度学习的贝叶斯方法早已被研究,因为它能为通常像黑盒一样的神经网络提供不确定性估计。不过,要让 BNN 真正实用,还需要将变分推断整合到深度学习训练的方法论中。在强调实际应用的 BNN 综述文章中,可以找到更详细的介绍。
有趣的是,此前很少有研究深入探讨 BNN 中的对称性问题。有学者提出过一种概率上的群平均方法给 BNN,以实现数据驱动的、软的对称性约束。与我们最接近的工作是使用了某种特定的先验,然后将不同的权重共享方案(对应不同的对称性约束)结合起来。在训练过程中,网络会自行学习哪种对称性最适用于手头的数据。而我们的方法则是在增强数据上训练,使用不强制权重共享的通用先验,路径完全不同。
3 理论
让我们系统梳理一下,数据增强是如何在变分贝叶斯推断中诱发等变性的。基本思路分为三步:首先,刻画指数族在群作用下何时是封闭的;其次,展示数据增强训练如何使 ELBO(证据下界)保持不变,以及这又如何影响训练;最后,提出几种对称化机制,并分析它们的性质。
3.1 预备知识
先介绍后面要用到的数学工具。首先是指数族——它是我们理论分析的结构骨干;接着回顾变分推断;最后是形式化对称性所需的群论概念。
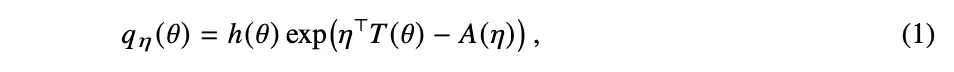

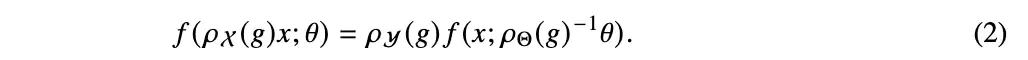




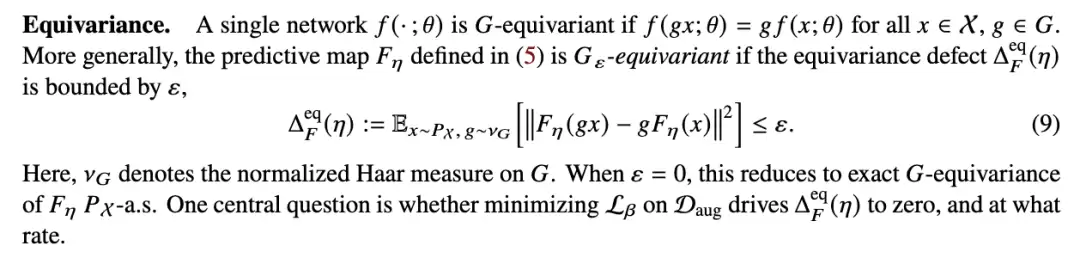
3.2 群作用下封闭的指数族
要让神经网络真正从增强数据中学习到等变性,一个先决条件是:其参数空间必须在群变换下是封闭的。同样,在贝叶斯框架下,我们也需将变分分布族限制为在群变换下封闭的类型。这一限制对指数族施加了一些条件。具体的证明细节,我们放在了附录 C 中。

3.3 数据增强诱导等变性



值得关注的是,定理 3.7 并不直接依赖增强数据,它只与不变的似然性有关。而根据命题 3.1,这个不变的似然性是由数据增强本身隐含的。因此,即使对称性确实存在于数据中但我们事先并不知晓,该定理也依然成立。然而,在这种情况下,要保证先验也是不变的,就比较困难了。下一个定理(证明在附录 E)会告诉我们,随着数据集增大,非不变先验的负面影响会自动消失。
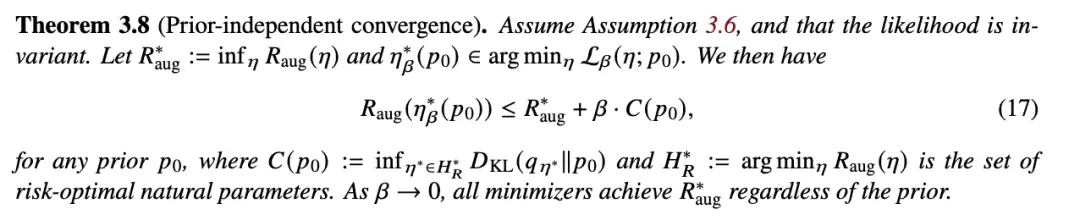


3.4 变分后验的对称化

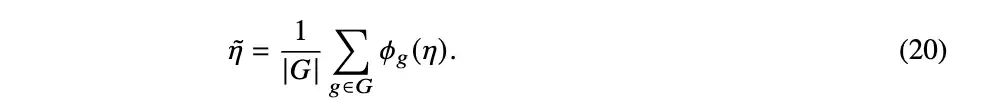
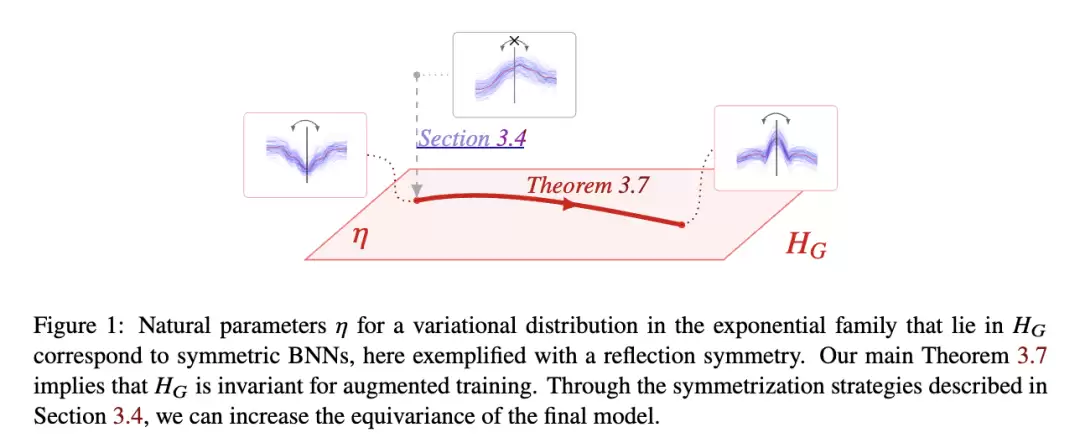

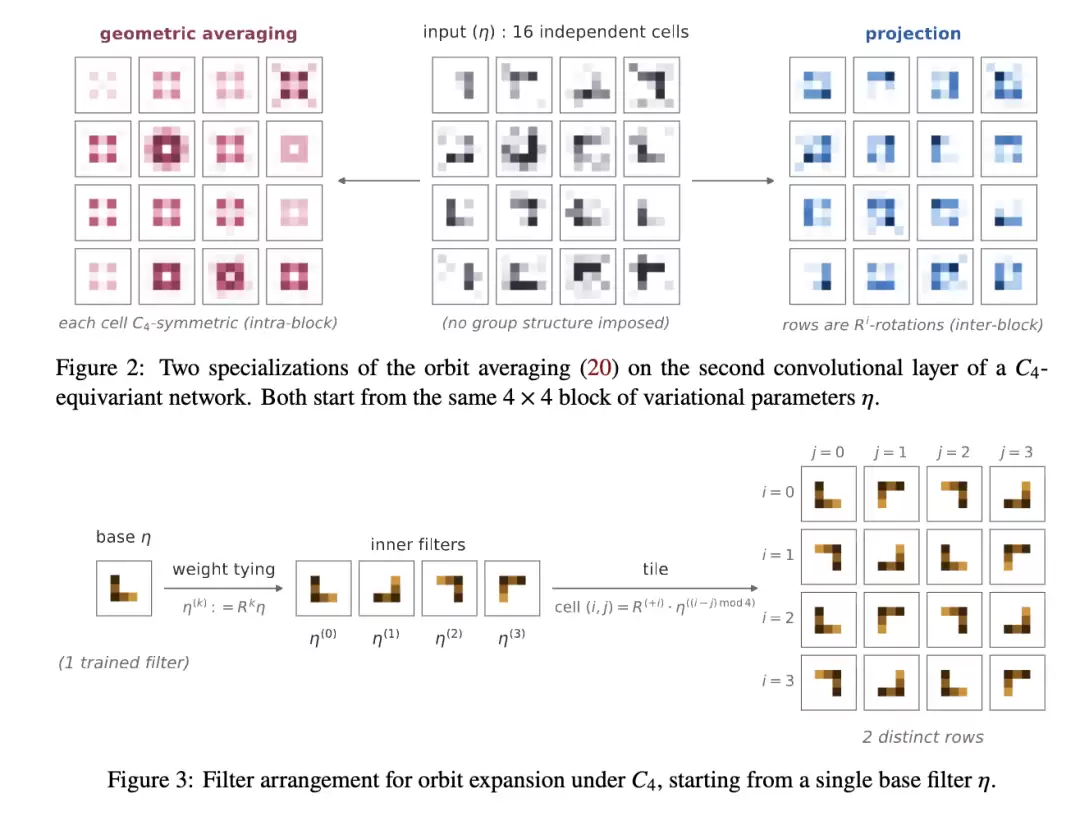

4 实验
在实验部分,我们选择了一个经典数据集:FashionMNIST,并且只考虑旋转 90° 倍数这种简单的循环群对称性。这样的设定一方面能让数据增强做得非常精确,另一方面也方便我们进行大范围的蒙特卡洛采样。整个实验过程中,我们都使用了高斯变分分布,这满足了定理 3.2 中的约束条件。在附录 J 中,我们还针对其他变分分布做了额外的消融实验。
4.1 定理验证

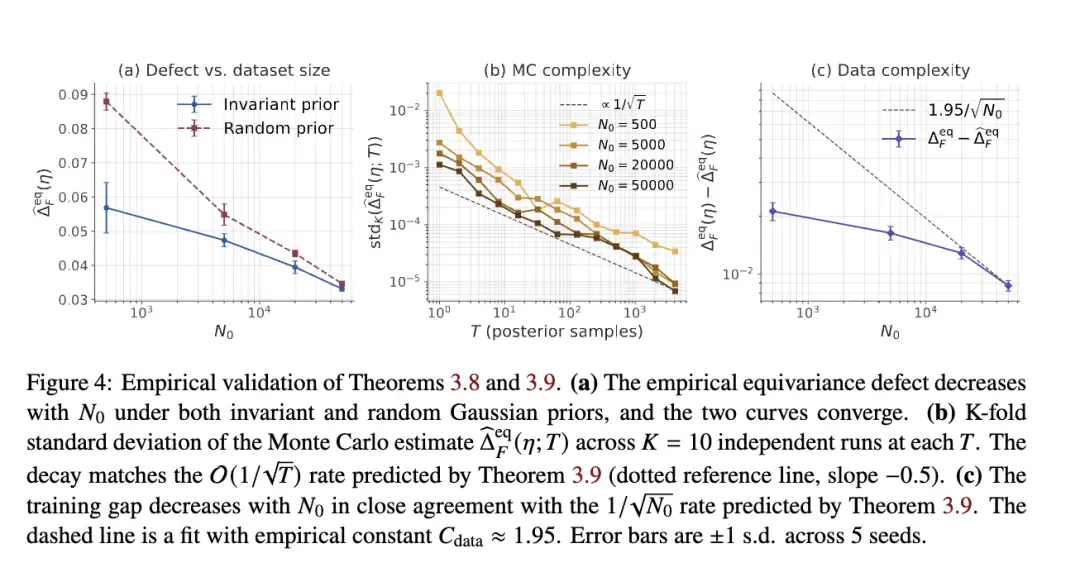

4.2 图像分类上的对称化
接下来,我们用真实数据,比较一下第 3.4 节中提出的几种对称化机制的实际表现。
实验设置。 我们训练了一个卷积贝叶斯神经网络:两个卷积层,分别有 32 和 64 个通道,最后加一个分类层。变分分布采用对角高斯变分族,先验为标准各向同性高斯先验。训练集是从 FashionMNIST 中随机挑选的 5000 张图像,每张图像都完整地进行了旋转增强(共 20000 个训练样本)。

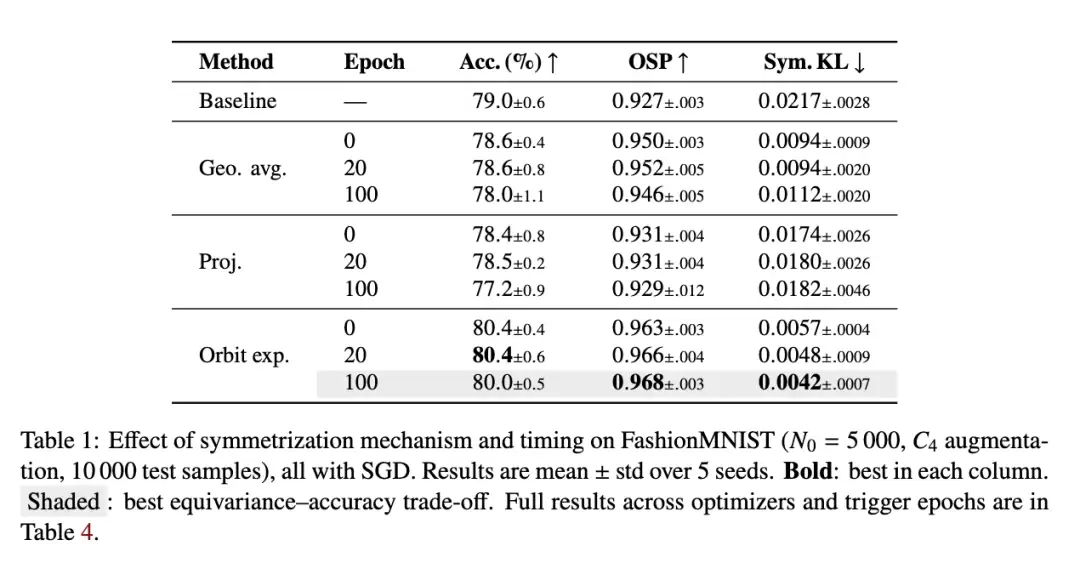
我们注意到一个现象:如果对称化干预应用得较晚,所有策略的性能通常都会下降。这很容易理解,因为触发晚意味着重新初始化后的训练时间较短。不过,几何平均方法在 OSP 和 Sym.KL 这两个指标上是个例外——虽然它也呈现下降趋势,但它是从一个比其他所有方法都要好得多的起点开始下降的。
最终,轨道扩展方案交出了最好的答卷。我们推测,这是因为与简单的轨道平均相比,轨道扩展产生的参数自带额外对称性,而这种额外对称性源于基滤波器数量有限(可参考图 3 和图 5)。这些多出来的对称性似乎能带来更强的稳定性。当然,这背后更深层的原因还有待未来继续探索。

5 结论与局限性

最后,必须坦诚地讨论我们工作的局限性。为了将问题阐述清楚,我们做了一些假设,这也为结果的适用范围划定了边界。例如,我们主要聚焦于指数族。虽然它覆盖面很广,但像高斯混合模型这样一些著名分布并不属于指数族。此外,我们的分析和实验都限制在有限群上,这样才能直接定义有限增强数据集。要推广到连续群,就需要用从对称群中采样的方法来实现数据增强。虽然这超出了目前这篇工作的范围,但我个人认为,沿着这个方向拓展我们的结果并不存在概念上的障碍(附录 A 中也做了讨论)。最后一个局限性是相容性假设(2)。考虑到中间表示的选择具有很大灵活性,这一限制总体上还算温和。




