对于大多数Python数据工程师而言,pandas往往是入门最早的数据处理库。将其视为行业标准毫不夸张——它稳定可靠且持续满足需求,因此长期以来很少有人对其产生质疑。
然而,pandas诞生于2008年,其设计理念基于当时的数据处理场景:默认每个操作即时返回结果、默认单CPU核心即可胜任、默认数据能够完全载入内存。这些前提条件在多年间一直成立,但随着数据管道规模的持续扩张,它们正逐渐失去有效性。
本文并非否定pandas的价值——它确实优秀,我至今仍在日常工作中使用。核心问题在于:它是否仍然匹配你当前实际运行的工作负载?
对于超过1GB规模的文件型ETL任务而言,问题并非pandas本身能力不足,而是生态系统中已经涌现出一个架构上更为契合的替代方案——Polars。两者之间的性能差异绝非简单的量级差距。
Polars架构性能优势的底层原理
在深入探讨基准测试数据之前,有必要先理解其工作原理。下图并排展示了两种执行模型。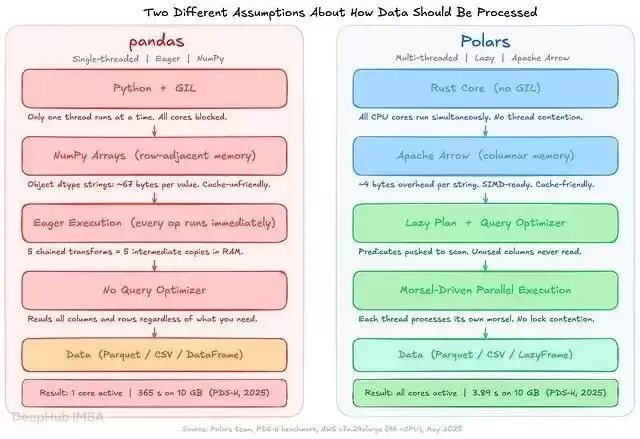
Pandas的单线程即时执行(eager execution)与Polars的多线程惰性执行(lazy execution)形成鲜明对比。
Pandas的执行机制
Pandas构建于NumPy之上,大多数操作采用单线程模式。Python的全局解释器锁(GIL)阻碍了并行执行,即使存在多个可用线程也无济于事。每个操作都会立即执行,因此无论是否必要,中间结果都会被创建并载入内存。对一个5GB的DataFrame执行五步变换,就要生成五份中间副本,内存占用迅速攀升。
此外,pandas默认将字符串存储为NumPy object数组:每个值对应一个Python对象指针,每个唯一字符串大约占用67字节,而列式存储仅需4字节的额外开销。100万个18字符的字符串,在pandas object dtype下约占75MB,同样的列在Arrow格式下仅需约22MB。
Polars的执行机制
Polars采用Rust编写,完全运行在GIL之外。数据以Apache Arrow列式格式存储:每列是一块连续的类型化内存,对CPU缓存友好,同时支持SIMD指令。调用scan_parquet时,并不会实际读取任何数据。Polars首先构建逻辑执行计划,在触碰任何字节之前完成优化:谓词下推到扫描层、未使用的列在读取前裁剪、Join顺序重新排列以提升效率。
执行采用morsel驱动模式。每个CPU线程获取一块输入,使用独立的本地状态进行处理,最后合并结果。计算过程中没有锁竞争,所有核心能够同时运行。
处理一个10GB的Parquet文件时,pandas会读取全部10GB数据,在单核上顺序处理,并在过程中产生中间副本。同样的Pipeline在Polars中,仅读取满足过滤和聚合所需的列与行组,在所有核心上并行处理,不会实体化任何不必要的中间结果。每次对Pipeline进行计时,都能感受到这种差异:pandas还在读取数据时,Polars已经在规划执行,但Polars总是率先完成。
基准测试对比
下表汇总了不同规模和负载类型下的测试结果。
三项独立基准测试分别对比了查询Pipeline、生产ETL迁移和调度负载场景下Polars与pandas的表现。
PDS-H基准测试
Polars团队于2025年5月发布了更新的PDS-H测试结果,运行环境为AWS c7a.24xlarge实例(96 vCPU、192 GB RAM)。测试对10GB CSV数据集运行全部22条TPC-H衍生查询。Polars流式处理耗时3.89秒,pandas 2.2.3(启用PyArrow dtype)耗时365.71秒——整条多步分析Pipeline下来,性能差距达到94倍。
在Scale Factor 100(100GB)场景下,pandas直接出局。单线程执行加上缺乏查询优化器,导致在完成基准测试之前就触发了内存溢出(OOM)。Polars流式处理耗时23.94秒。
当然,这是厂商自行运行的基准测试,可将其视为方向性参考。在普通硬件上的独立测试差距通常较小,单个操作一般在5到22倍之间。那个标题级别的倍数,是查询优化器和多线程在完整Pipeline中叠加后才出现的。
生产环境的实证案例
荷兰出行服务商Check Technologies在一个Sprint内将全部100多个Airflow DAG从pandas迁移到了Polars。驱动力并非性能基准,而是最数据密集的Pipeline上反复出现的OOM错误。迁移耗时不到两周:最严重的DAG速度提升了3.3倍,几乎所有其他DAG提升约2倍,云基础设施成本降低了25%。其高级数据工程师Paul Duvenage表示,团队一旦切换到声明式表达式API,迁移过程就非常顺畅。
DB Systel(德国铁路子公司)使用Polars 0.20重写了一个列车调度重处理任务。该任务原本需要96分钟,Polars版本仅需5.5分钟——在真实生产负载上实现了17.5倍的提升,而非合成基准测试中的数据。
在小数据场景下,性能差距基本消失,有时甚至会反转。Polars的查询优化器存在规划开销,当数据集小于几百MB时,这个开销会超过计算节省。对于小DataFrame上的快速脚本,pandas编写更快,运行速度也足够。
安装与运行指南
安装只需一条命令:
# 创建项目并添加 Polars
uv init polars-pipeline
cd polars-pipeline
uv add polars pyarrow
# 标准安装
uv run pipeline.py无需编译,无需系统依赖。Polars以预编译wheel形式发布,Rust运行时已打包在内。
开始之前有一点值得注意:在Apple Silicon(M系列Mac)上,标准polars wheel会触发CPU兼容性警告,并建议使用运行时兼容版本。
# Apple Silicon:改用这个
uv add "polars[rtcompat]" pyarrowLinux和Intel Mac上使用标准安装即可。在M系列硬件上,polars[rtcompat]可避免警告,并确保使用适合该处理器的正确SIMD指令。
并排对比:两个库实现相同操作
第一次接触Polars代码时,语法可能会显得陌生。表达式API需要大约一天时间来适应,适应之后,你会发现它比pandas的等价写法更易读,而非更难读。下面的代码执行完全相同的ETL变换:读取Parquet文件、过滤行、按类别聚合、排序结果。先是pandas版本,然后是Polars LazyFrame版本。
# pandas 版本
import pandas as pd
import time
start = time.perf_counter()
df = pd.read_parquet("sales.parquet")
result = (df[df["revenue"] > 1000]
.groupby("category")
.agg(total_revenue=("revenue", "sum"),
a vg_price=("price", "mean"),
order_count=("order_id", "count"))
.sort_values("total_revenue", ascending=False)
.reset_index())
print(f"pandas: {time.perf_counter() - start:.3f}s")
print(result)# Polars 版本——带谓词下推和投影下推的惰性执行
import polars as pl
import time
start = time.perf_counter()
result = (pl.scan_parquet("sales.parquet") # 此时不读取任何数据
.filter(pl.col("revenue") > 1000) # 下推到扫描层
.group_by("category")
.agg(total_revenue=pl.col("revenue").sum(),
a vg_price=pl.col("price").mean(),
order_count=pl.col("order_id").count())
.sort("total_revenue", descending=True)
.collect() # 执行在这里发生
)
print(f"Polars: {time.perf_counter() - start:.3f}s")
print(result)结构上的关键差异在于scan_parquet与read_parquet的对比。Pandas版本立即读取整个文件;Polars版本构建执行计划,仅读取满足过滤和聚合所需的行和列。对于一个1GB、20列、实际仅需3列的文件,Polars读取的字节数可能不到pandas的20%。
流式处理超出内存容量的数据
当数据集超过可用内存时,在collect中加入engine="streaming"。Polars以称为morsel的批次处理数据,自适应地溢出到磁盘,始终不将完整数据集保留在内存中。
result = (pl.scan_parquet("large_dataset/*.parquet")
.filter(pl.col("status") == "active")
.group_by("region")
.agg(pl.col("amount").sum())
.sort("amount", descending=True)
.collect(engine="streaming") # 核外执行
)如需直接写入磁盘而完全不在内存中实体化,使用sink_parquet:
(pl.scan_parquet("raw/*.parquet")
.filter(pl.col("error_code").is_null())
.sink_parquet("clean/output.parquet") # 分批流式写入磁盘
)生产环境注意事项
在生产环境中显式设置线程数,以避免与其他进程争抢资源:
import os
os.environ["POLARS_MAX_THREADS"] = "8" # 必须在导入 polars 之前设置
import polars as pl
# Polars 在导入时初始化线程池——
# 导入后再设置此变量无效在pyproject.toml中锁定Polars版本。1.x API已稳定,但小版本更新会引入新特性,在边缘情况下可能改变行为。锁定版本,在与生产OS一致的容器中测试,有意识地升级。
Pandas仍然占优的场景
Polars是1GB以上文件型ETL的更优选择,下图按数据规模和负载类型梳理了决策框架。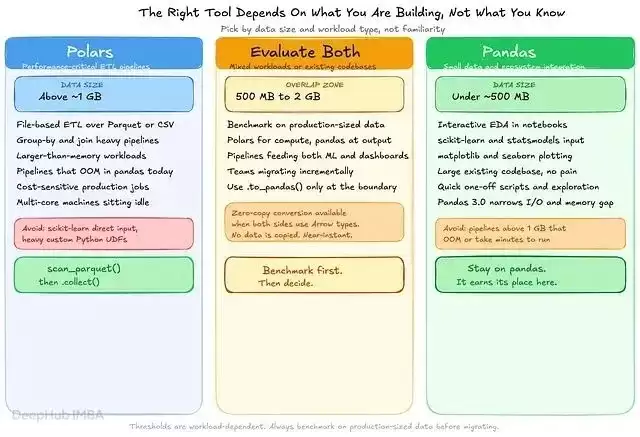
按数据规模和负载类型选择工具,并明确标注了机器学习生态系统的约束。
大多数机器学习库以pandas DataFrame作为原生输入格式。scikit-learn、statsmodels以及众多绘图库,要么明确要求pandas,要么默认如此。为了省一次.to_pandas()调用而重写整个技术栈,这笔投入并不值得。
在每一个需要给模型喂数据的Pipeline中,实践中的做法是采用混合方案:用Polars处理繁重的计算工作,在最后一步进行转换:
# 用 Polars 做重活
features = (pl.scan_parquet("events/*.parquet")
.group_by("user_id")
.agg([pl.col("session_duration").mean().alias("a vg_session"),
pl.col("purchase").sum().alias("total_purchases"),
pl.col("event_date").max().alias("last_seen")])
.collect(engine="streaming"))
# 在边界处零拷贝转换
import sklearn
X = features.to_pandas() # 基于 Arrow,几乎瞬间完成转换几乎瞬间完成,因为Polars和新版pandas共享Apache Arrow内存格式——当两边都使用Arrow类型时,不会发生数据拷贝。
Pandas 3.0带来了哪些变化
2026年1月发布的pandas 3.0,将PyArrow支持的字符串设为字符串列的默认类型,并将写时复制(Copy-on-Write)设为唯一执行模式。这些改动使字符串密集型数据集的内存占用降低了最多70%,并消除了一类静默的变异bug。
这是实实在在的改进。它在I/O和内存方面实质性地缩小了差距。但多核执行的差距依然存在——pandas的聚合操作在任何版本中仍然是单线程、即时执行的,也没有查询优化器。如果瓶颈在于计算而非内存,3.0版本并未改变这一判断。
总结与决策建议
有三个信号说明一条Pipeline已经到了需要迁移的时候:
第一:在生产规模的数据上触发OOM,或者已经为了绕过内存限制加入了分块逻辑。第二:本该几秒完成的任务跑了好几分钟,性能分析显示pandas的groupby或join操作占据了主要运行时间。第三:运行在一台多核机器上,执行期间那些CPU核心基本处于空闲状态。
迁移时可以选择最慢的那条Pipeline,或者最常触发OOM的那条。仅用Polars LazyFrame重写计算密集的部分,在输出端保留pandas边界以衔接机器学习或绘图,然后在生产规模的数据上进行基准测试,再推上线。如果在超过1GB的数据集上看不到至少3倍的提升,瓶颈可能根本不在DataFrame库上。
Pandas并非遗留技术,它是精准的专用工具;Polars则是另一种场景下的精准专用工具。为每项工作选择合适的工具——这不是迁移项目,而是工程判断力。