近期,人工智能行业的风向正经历显著转变。美国科技企业纷纷从初步试探转向公开展示,逐步将中国开源AI模型纳入其生产级基础设施。
这并非个别公司的短期决策。其背后有一个直接动因:头部美国模型服务价格持续攀升,迫使企业重新审视成本结构。如何在控制用量增长的同时,压缩AI支出涨幅?答案逐渐指向中国开源模型。
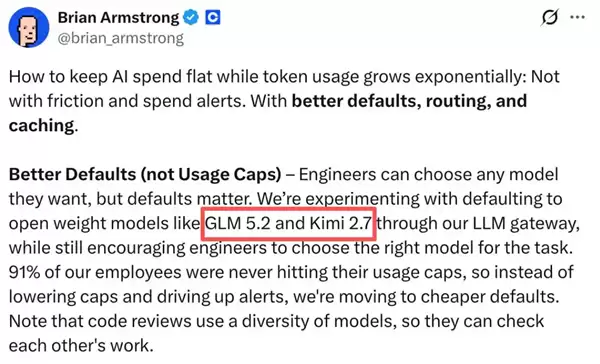
以加密货币交易所Coinbase为例,首席执行官Brian Armstrong上周末在社交平台X上公开表示,公司内部LLM网关已完成关键的默认模型切换。全体工程师的默认选项,现已替换为智谱GLM 5.2和月之暗面Kimi K2.7。

Armstrong并未透露具体节省金额,但给出了一个生动的成本账本:Token使用量持续呈指数级增长,而AI整体支出却压缩了近一半。如何实现的?核心在于三点:更换默认模型、启用智能路由、强化缓存策略。他强调,这套方法路径清晰,任何公司都可复制。
值得关注的是其中的门道。公司91%的工程师,此前从未触及原有用量的上限。这意味着大多数人的调用需求,根本无需依赖顶尖价位模型。因此,Coinbase的优化并非削减员工的Token额度,而是将代码审查、文档总结等常规任务,从Anthropic、OpenAI的前沿模型转移至上述两款中国开源模型。
这种做法并非孤例。此前,Airbnb已将其客服模型从GPT替换为千问。近期,AI公司Lindy更是果断将模型从Anthropic Claude迁移至DeepSeek V4,理由是不换则AI开支将超过员工工资。Snowflake的CEO也曾测算,GLM 5.2能以显著更低的价格,达到Claude级别的性能表现。
仅凭个别案例难以服众?不妨看看OpenRouter平台。这个知名AI模型调用平台上,中国模型长期占据文本模型调用榜单的第一梯队。DeepSeek、小米MiMo、MiniMax、腾讯混元、智谱GLM等名字赫然在列,表现亮眼。
这里需要多提一句:这波趋势背后并非简单的“便宜替代”。从成本压缩到性能验证,从模型选型到实际部署,这些企业正用真金白银投票,证明中国开源模型已全面进入可用、好用、值得用的阶段。
这正是商业层面最具说服力的事实。




