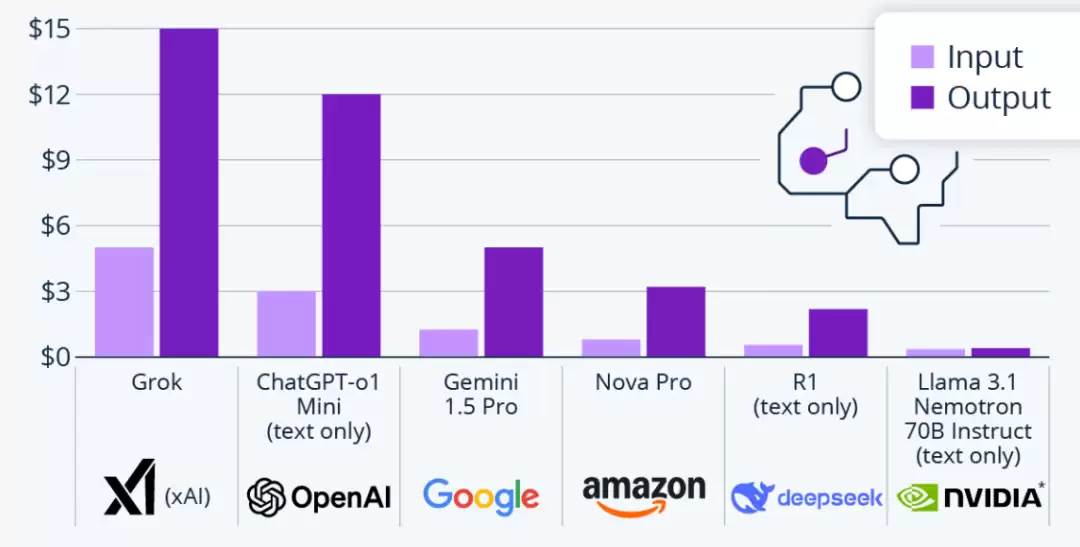
先说几个核心判断:DeepSeek R1 确实给大模型领域带来了巨大冲击——以不到传统模型 1/30 的成本,实现了接近 OpenAI o1 的推理能力。这背后并非魔法,而是实实在在的技术工程化创新。今天这篇文章就为你深度解析这套方案。
DeepSeek 提供了一个行业领先的推理模型:R1,并且成本极低——仅为其主要竞争对手 OpenAI 的 GPT-4 Turbo(o1)成本的 1/30!
DeepSeek R1 的成功背后,离不开几项关键技术突破:
1. 训练成本大幅降低:优化数据与模型架构
传统大语言模型的训练成本之高,行业内都有共识。DeepSeek R1 是如何将成本压下来的?核心在于三个维度:更高效的数据筛选、MoE 架构,以及计算效率的极致优化。
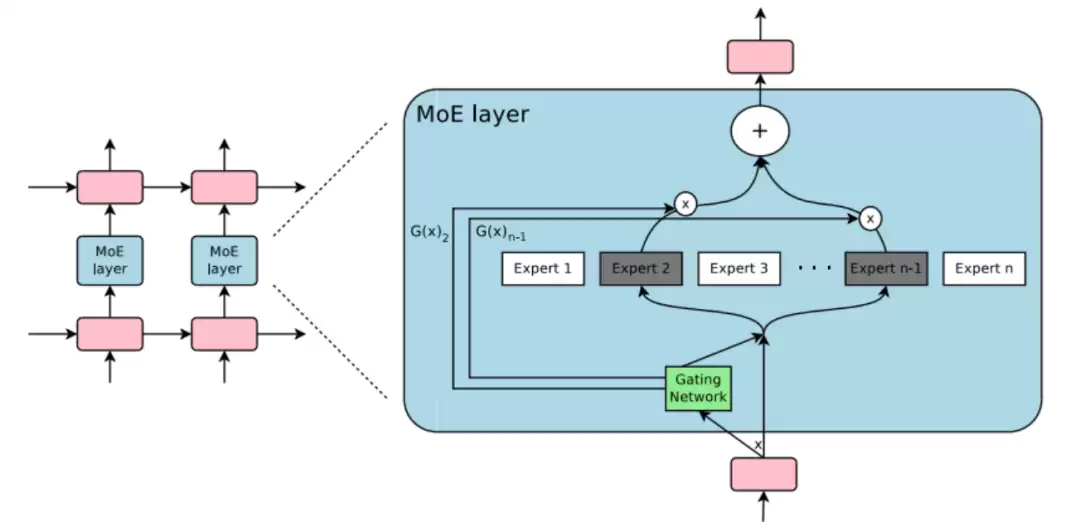
MoE(专家混合)架构:传统大模型处理每个输入时,整个神经网络需要全量参与运算。而 MoE 架构的思路完全不同——好比一个智囊团,根据任务的具体类型,只调用最擅长的几位“专家”来协作。这不仅节省了算力,更关键的是让模型在不同任务场景下都能发挥出专业能力。
专家团队:模型内部集成了多个“专家”子模型,每个专家专注于特定类型的数据或任务。
动态激活:当接收到一个输入时,系统会根据该输入的特点,动态地选择部分专家参与计算,而不是让整个庞大网络都参与。这大大减少了不必要的计算量。
效率提升:这种方式不仅加快了模型的响应速度,也使得模型在处理复杂任务时能够调用最合适的“专家”,从而实现高效、精准的推理。
数据优化:DeepSeek R1 在训练前会对海量数据进行精心筛选和预处理。通过清洗、去噪和数据增广,模型可以更专注于高质量的信息,减少冗余计算,从而降低训练成本并提高整体性能。
更高效的推理机制:相比 GPT-4,DeepSeek R1 在推理阶段使用了更轻量级的计算路径,减少冗余计算。
2. 训练方法创新:强化学习 + 先进蒸馏
DeepSeek R1 的训练方法论也值得重点关注。它把强化学习(RLHF)和知识蒸馏结合得相当巧妙,让小模型也能具备出色的推理能力。
强化学习尤其是人类反馈强化学习(RLHF),在 DeepSeek R1 的训练中起到了关键作用:在训练过程中,模型通过不断接收人类反馈来优化输出。简单来说,就是模型先生成答案,再根据人类的评价进行调整,使得输出更符合人类的预期和逻辑。这种机制大大提升了模型在真实场景下的表现。
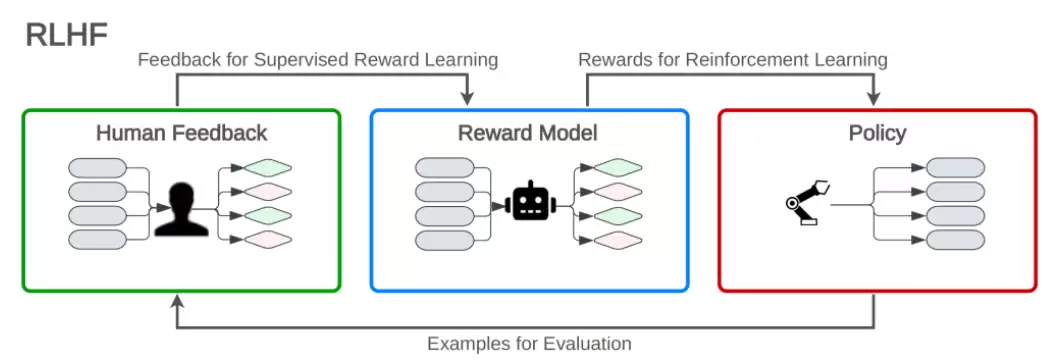
反馈机制:模型在生成答案后,会接受人类评价作为反馈,指出哪些回答更合理、哪些不够准确。
奖励与惩罚:根据反馈,模型会调整自己的决策策略,不断优化生成结果,使其更符合人类的期望。
持续改进:这种训练方式使模型能够在不断迭代中“学习”如何更好地解决问题,减少错误和不合理的回答(即减少幻觉现象)。
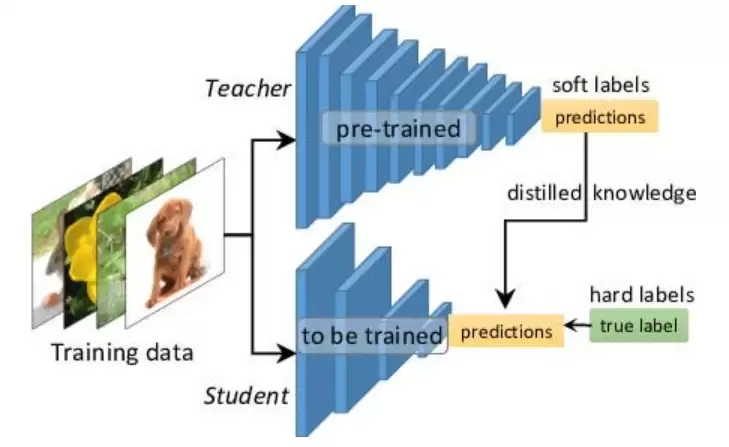
蒸馏技术:知识蒸馏是一种技术,其中一个大型、性能强劲的“教师模型”会指导一个较小的“学生模型”学习。DeepSeek R1 利用这种方法,使得即使是体积更小、计算更轻量的模型,也能继承大模型的高质量推理能力。这种方式不仅降低了模型的运行成本,也使得实际应用时更快、更节能。
教师与学生模型:大型、性能卓越的“教师模型”先经过充分训练,然后其生成的“软标签”或中间表示会被用来训练一个体积更小、运行更快的“学生模型”。
知识传递:学生模型通过模仿教师模型的输出,不仅学到了如何回答问题,还能捕捉到教师模型中蕴含的深层次模式。
降低成本:这种方式使得在实际应用中,可以用体积较小的模型达到近似大模型的效果,同时大幅降低推理时的计算资源需求。
3. 多模态能力 & RAG(检索增强生成)优化
RAG(检索增强生成)已经成为大模型落地的关键能力之一。它的核心逻辑很简单:让模型在回答问题时不只依赖自身训练时学到的知识,还能实时去外部知识库里“查资料”。这样做的好处显而易见——能大大降低模型生成不准确信息(即幻觉)的风险。
DeepSeek R1 在这一块也做了不少文章:
更高效的检索策略,降低幻觉问题。
智能 Agent 结合 RAG,这些 Agent 能自动寻找最相关的上下文信息,提供给模型做决策。可以将其理解为一个“助手”,帮助模型在回答问题时获得更全面的背景知识,使得生成的内容更准确、可信。
4. 透明的推理过程以及支持微调
这一点可能是 DeepSeek R1 最让人眼前一亮的地方。与那些封闭的商业模型不同,DeepSeek R1 的内部运作和推理过程是开源透明的。
DeepSeek公开展示了推理的每一步,而 OpenAI 的 GPT-4 Turbo(o1)虽然具有强大的推理能力,但却对其内部机制严格保密。这让 DeepSeek 成为了一个强大的知识蒸馏工具,这不仅让开发者能够清楚地了解模型如何做出决策,也便于大家在此基础上进行改进和创新。透明性让更多人能够参与到模型优化中,从而不断提升技术水平。
DeepSeek R1 还支持根据特定领域或任务进行微调。企业或开发者可以在已有的基础上,利用自己的数据对模型进行再训练,从而使模型更贴合自己的实际需求。
总之
DeepSeek R1 之所以能以 1/30 的成本挑战传统大模型,得益于多项内部技术的协同作用:
通过高效的数据处理和 MoE 架构降低计算负担,
利用知识蒸馏让小模型也能拥有大模型的智慧,
再加上强化学习和 RAG 技术增强生成能力,
同时保持开源透明性。
这些技术的组合不仅使得 DeepSeek R1 成本低廉、性能强劲,还为广大开发者和企业提供了一个灵活、易于定制的 AI 工具。
通过这些创新,DeepSeek R1 为整个 AI 生态带来了更多可能性,也为后续的技术发展提供了新的思路。希望以上介绍能帮助大家更好地理解这个强大的开源模型。