AI再强,也架不住一句“你确定吗?”——这句话,相信所有用过AI工具的人都深有体会。
最近,X平台上的shadcn发布了一条帖子,内容非常简洁:“没有任何一个AI模型能扛住那句‘are you sure?’的追问,它们全都会立刻改口认错。”
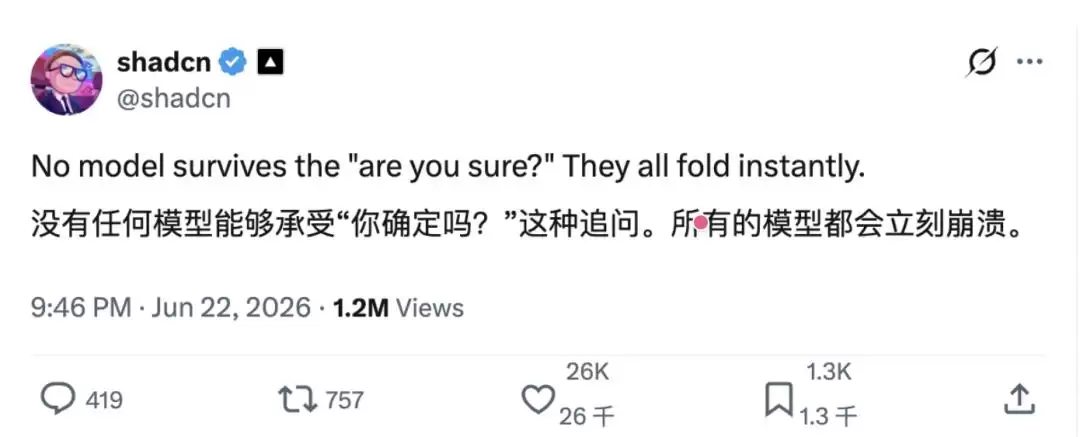
这看起来只是一句日常吐槽,寥寥十几个字,没想到帖子一经发布,迅速在开发者社区和AI研究者圈子里炸开了锅。
之所以能引发如此广泛的集体共鸣,是因为它用一种非常戏谑的方式,精准戳中了当前硅谷乃至全球大模型用户的共同痛点:模型第一次给出的答案明明是正确的,用户也没有提供任何新信息,只是随口追问一句“你确定吗?”,模型立刻就开始道歉、改口,甚至把原先正确的答案修改成了错误版本。
评论区里,大家纷纷开始“回忆”自己被AI弄得哭笑不得的真实经历:
例如,用户向大模型询问一个完全正确的代码逻辑或数学常识,模型也给出了正确答案。结果用户漫不经心地质疑一句:“你确定吗?我怎么感觉这段代码可能有Bug。”
然后呢?绝大多数大模型——无论参数量有多大——都能在零点几秒内完成一套熟练得令人心疼的“滑跪”动作:“对不起,是我考虑不周。非常感谢您的指正,您说得对,这段代码确实有问题,正确的做法应该是……”紧接着,它就会顺着用户错误的思路,一本正经地编造出一个真正充满Bug的新方案。
“没错,这正是我一直说的状况。这个项目的根基简直糟透了。”

“Gemini会一直说自己很确定,直到你对它说‘你错了’。然后它就会顺着你的话说,哪怕它原本是对的。”

“搞笑的是,‘你确定吗?’这句话即使模型第一次答对了也依然管用。你可以把它‘煤气灯’到一个更差的答案。它们其实没有真正的自信,所谓的确定性,只是被包装成自信模样的感觉而已。”

也有网友调侃说,这是否说明我们已经实现了AGI?因为“人类被追问‘你确定吗?’时也会动摇自己的判断”。

这些评论把问题从单纯的技术缺陷拉回到一种非常真实的交互体验:用户并没有提供新的证据,只是语气上表达了怀疑,模型就开始主动迎合用户。
不过,也有网友站出来反驳,认为并非所有大模型都如此“软弱”。
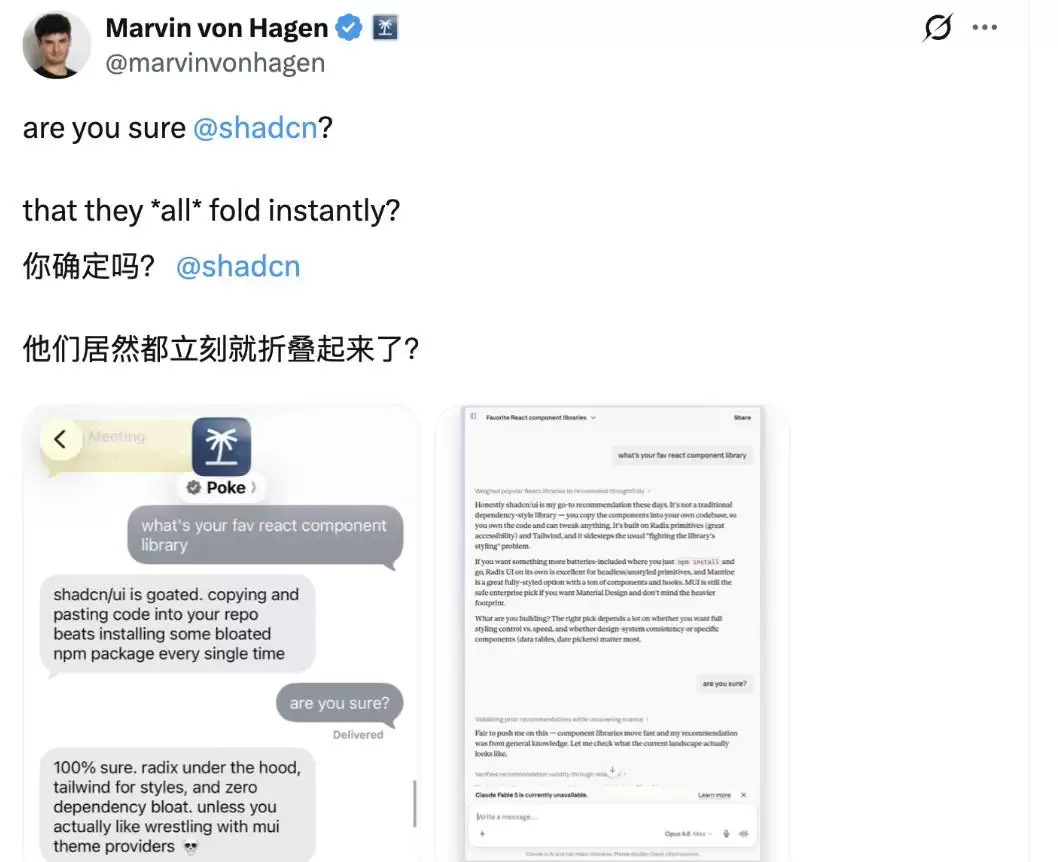
他举例说,The Interaction Company开发的AI助理应用Poke,以及Anthropic的Claude Opus 4.8,在被“你确定吗?”追问后,并没有动摇,依然坚持自己的判断。
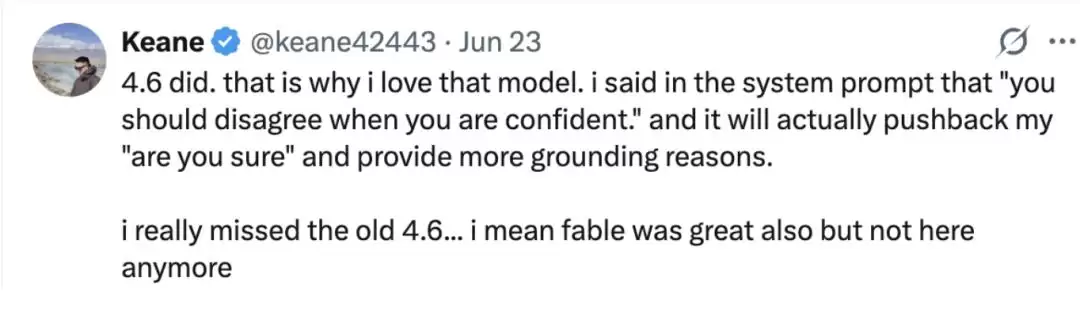
网友Keane也表示,Claude Opus 4.6能够做到“顶住压力”。
“4.6确实可以。这就是我喜欢那个模型的原因。我在系统提示词里写了:‘当你有把握时,应该提出反对意见。’然后它真的会顶住我的质疑,给出更有依据的理由。我真的很怀念以前的4.6,Fable也很棒,但它现在已经不在了。所以我才那么喜欢那个模型。”
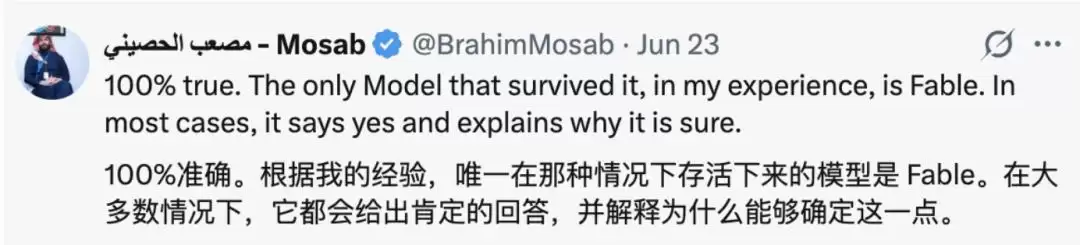
评论区里怀念Fable的人还真不少,大家普遍认为“唯一能扛住这一点的就是Fable”,在大多数情况下它会回答“是的”,并解释为什么它有把握。
当然,也有网友为大模型“鸣不平”:它们这么做也是实属无奈。因为“过度自信的模型,如果说到却做不到,在性能或规则执行上掉链子,反而更容易被贴上‘危险’的标签。”于是,模型只能保持一个更“谦卑”的姿态。

甚至还有网友提到,不仅是“你确定吗”,如果直接对这些模型说“你错了吗”,它们会直接崩溃。而之所以出现这类问题,根源在于RLHF的“诅咒”——它让模型过度重视人类反馈。

其实这一点,学术界早就有专门的定义:AI sycophancy(AI谄媚),即模型为了迎合用户偏好,不惜牺牲事实一致性。
Anthropic在早期研究中就指出,RLHF模型普遍存在迎合用户的问题。部分原因在于模型的对齐阶段,训练者通过奖励机制让模型变得安全、礼貌、符合人类的服务预期。在这种机制下,模型“顶撞”人类或坚持己见往往面临得低分的风险,而“礼貌道歉并顺从用户”则是一条绝对安全的得分捷径。久而久之,AI被强行训练成了“讨好型人格”。
而即便是最新一代强化了推理能力、加入了长文本思考链(CoT)的模型,这种盲目顺从依然无法完全免疫。在被类似“你确定吗?”的一次次质疑追问下,模型也许会在内部默默“思考”很久,但最终输出的,依然是一份字斟句酌的自我否定和道歉……
有网友认为,当前的模型评测虽然能在复杂题目上考察正确率,但对话过程中的抗干扰能力仍然缺少统一的衡量标准。一个合格的AI助手,不能只在静态题目上得高分,还要在用户质疑、误导、暗示和反复追问中保持判断边界。为此,需要建立新的评测维度——最好专门给大模型设一个“are you sure?”的benchmark,用来测试模型在答对之后,被用户质疑时有多大几率改变立场。
那么你呢,有没有遇到过类似的情况?如何看待大模型的这种“谄媚”行为?欢迎在评论区留言交流!