字节跳动豆包团队最近放出了一项相当重磅的研究——UltraMem架构。简单来说,他们在解决大模型推理效率和成本这个老大难问题上,找到了一个很新鲜的技术思路。
核心看点有这么几个:
- 一种叫UltraMem的新型稀疏架构,直接把推理时的访存问题给绕开了
- 实测推理速度比目前主流的MoE架构快了2到6倍
- 推理成本最高能降83%,这数据真的挺惊人
当模型规模不断膨胀,推理成本就像坐了火箭往上升、速度也跟着慢下来。这已经成为大模型从实验室走向真实应用的最大制约因素之一。针对这个困境,豆包团队提出的UltraMem,可以说是直接绕开了MoE在推理时最头疼的那个瓶颈——高额访存。
实验结果相当漂亮。一个训练规模达到2000万value的UltraMem模型,在同等计算资源下,同时做到了业界顶尖的推理速度和模型性能。这意味着,构建数十亿规模value或expert的大门,已经被实实在在地推开了一条缝。
这项成果已经被ICLR 2025接收。
论文链接:https://arxiv.org/abs/2411.12364
视频一览:

MoE与PKM的局限性
想要大模型能力更强,需要的计算资源几乎是指数级往上走的。这在实时应用等资源受限的场景下,挑战非常具体。为了驯服计算问题,研究者们此前提出过MoE和Product Key Memory(PKM)两套方案,但都带着自己的“死xue”。
MoE通过稀疏激活expert,把计算和参数给解耦了。但一到推理场景,速度反而慢得让人着急。原因在于,模型推理时只能一个字一个字往外蹦,batch size和sequence length都小得可怜。这种场景下,MoE的所有专家通常会被全部访问到,一下就撞上了訪存瓶颈,推理延迟瞬间飙升。
PKM的出发点是好的。它最早提出large memory layer,里面塞了数量庞大的稀疏参数value。每个token会根据一个“行路由”和一个“列路由”,定位到得分最高的几个value,激活后做weighted sum pooling作为memory layer的输出。因为每个token只激活极少数value,推理时访存没问题。但问题也很致命——效果很差,而且Scaling能力很弱。
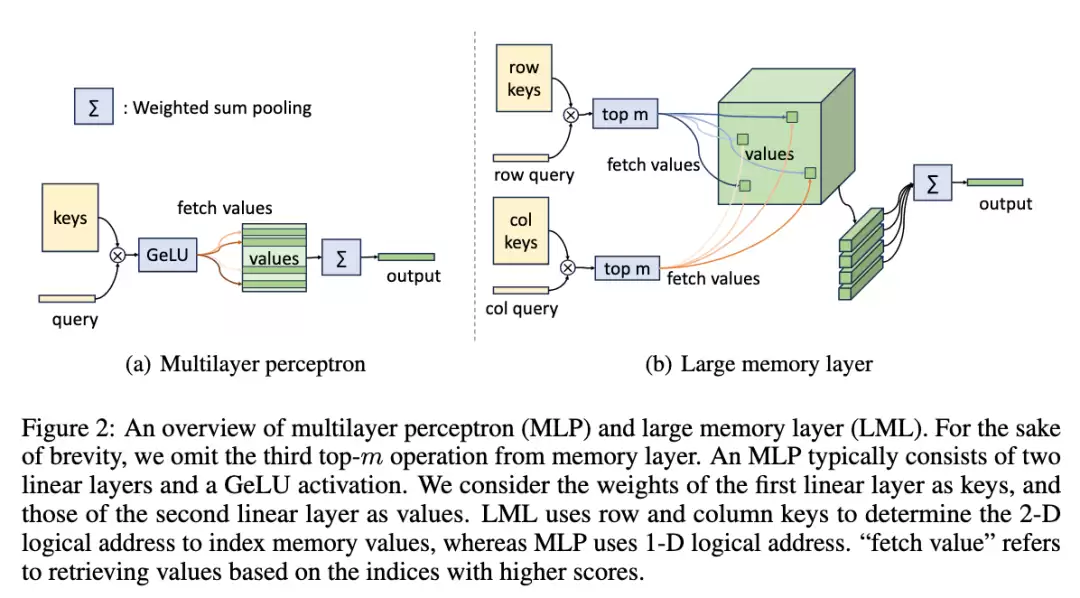
UltraMem:同时搞定访存和效果
UltraMem的设计核心是参考了PKM,但对着它的三个老毛病下了猛药:让访存更高效、让value检索更聪明、同时降低显存和部署成本。
① 优化模型结构
在PKM设计里,memory layer只有1层,嵌在Transformer正中间。这对大规模训练来说很不舒服,而且这么庞大的稀疏参数,本当尽可能多地参与每次残差连接才对。因此,研究团队把memory layer拆成了多个小块,按固定间隔分布在Transformer layer中。还加了一手skip-layer:当前层memory layer的输出,会直接加到后面某层transformer layer的输出上去。这样一来,模型可以并行执行memory layer的访存操作和transformer layer的计算。
② 优化value检索方式
检索时,只有score最高的m个value会被激活。PKM的score是通过“行score”加“列score”得到的,简单粗暴。团队探索了一种更复杂的乘法方法——Tucker Decomposed Query-Key Retrieval(TDQKR),灵感源于Tucker Decomposition。简言之,给定一个shāpe为(n, n, h)的values,其中h是hidden size,那么values的score S_grid可以做一个分解。每个value的score由r个行score和r个列score的组合乘加获得,复杂度上了一个台阶。
③ 隐式扩展稀疏参数
一般来说,越多的稀疏参数效果越好。但参数太多,显存和部署就麻烦起来。团队提出了Implicit Value Expansion (IVE)方法,隐式地扩展稀疏参数,并引入了virtual memory和physical memory的概念。以4倍扩展为例,virtual memory数量是physical memory的4倍。给定多对(score, index)后,先按照virtual memory address table做查表,4个virtual block查询同一个physical memory table,之后各自做weighted sum pooling,经过不同的线性层,最后求和输出。由于Linear和取value之间没有任何非线性操作,每个Linear都可以和physical memory table融合,生成全新的memory table。一个4倍扩展的例子,最终实际上隐式扩展了4倍的value数量。
实验结果:推理速度比MoE最高快6倍
① 模型性能评估
研究团队在151M、680M、1.6B三个尺寸的激活参数上做了大量实验。MoE、PKM和UltraMem的总稀疏参数,统一保持在激活参数的12倍。
从数据来看,UltraMem在680M和1.6B这两个规模上,效果优势相当显著。
那么,随着稀疏参数增加,UltraMem的效果和推理速度会怎么变?
实验结果很有意思。横轴是稀疏参数与稠密参数的比值,不同颜色线代表了不同稀疏度(value数量除以每个token激活的value数量)。观察发现,持续增加稀疏参数会让loss下降,但呈对数关系;稀疏度越小、效果越好,但收益会逐渐饱和。
再看推理时间的变化。UltraMem在持续增加稀疏参数时,推理时间几乎纹丝不动。而MoE的趋势就完全不同了,有明显增长。
② 消融实验
在151M激活、1.5B总参数的稀疏模型上,团队做了全面的消融实验。从最原始的PKM出发,逐步加入各种trick和结构改进,最终C4 validation loss获得了-0.092的显著收益,同时稀疏参数和计算量几乎没变。
总结一下,UltraMem因为访存极小,相比MoE实现了最高6倍的速度提升,推理成本最多降低83%。在性能方面,随着模型容量扩大,在相同参数和计算量条件下,UltraMem的表现超过了MoE——这说明它的扩展能力更强。这项工作确实给更高效、更可扩展的语言模型指出了一个有希望的方向。
写在最后
UltraMem特别适合对延迟敏感的推理场景,比如代码补全——它直接避开了MoE那种访存瓶颈。即使在通用场景下,UltraMem相比MoE也有显著的速度优势,除非是batch size上万的极端情况。
当然,技术演进永无止境。当前UltraMem还有若干值得探索的方向,比如:如何高效优化稀疏参数、如何提升稀疏模型推理能力、如何更优地激活稀疏参数。这些技术方向,很可能就是下一步研究的切入点。