如果 ChatGPT 的横空出世让世界第一次意识到 AI 的“语言天赋”,那么这两年来的 Agentic RL(智能体强化学习),正在让 AI 学会第二件事——行动。
可以这么理解:传统的大语言模型更像是一支拥有海量词汇的笔。它写得快,输出也漂亮,但所有事情都得你手把手告诉它怎么写,往哪个方向构思。而 Agentic RL 要做的,是把这支笔装上一个“大脑”。它能自己感知你的需求,拆解任务,主动调用搜索引擎和代码工具,发现中间某一步走错了还能停下来反思、调整策略,最后交付一个完整的成果。
从“文本生成器”到“自主智能体”,这看似只是训练方法的迭代升级,但实际上意味着 AI 的能力维度被彻底打开了。从 DeepSeek-R1 的推理能力,到 GLM-5.2 的长程任务优化,再到字节跳动 Forge 框架百万级的样本吞吐量,Agentic RL 早已不再只是实验室里的理论模型,而是实打实地进入了工业级工程实践。
那么,这场范式转变的技术内核到底是什么?这篇文章就从工程实践的角度,带你拆解一下 Agentic RL 的全貌。
1、一个根本性的认知:RLHF 不是 Agentic RL
要真正搞懂 Agentic RL,得先把它和我们更熟悉的 RLHF(基于人类反馈的强化学习)区分清楚。这两者之间的本质差别,远比大多数人想象的要大。
很长一段时间里,RLHF 和它的简化版 DPO 都是 LLM 后训练的主要方法。它们可以统一归到“基于偏好的强化微调”这个类别里。这类方法的优化目标非常明确:给定一个提示,模型的输出越符合人类的单次偏好,得分就越高。
这种模式是典型的“单轮静态决策”问题,对应的是一个极其简化的马尔可夫决策过程(MDP):从用户的 Prompt 出发,执行一次动作,生成一条回答,拿到奖励,然后游戏结束。
而 Agentic RL 的野心完全不同。它把 LLM 看作是嵌入在动态环境里的自主决策体,通过“部分可观测马尔可夫决策过程”(POMDP)来建模。模型要在复杂的任务环境里持续感知环境、循环决策、使用工具、阅读反馈,而且得学会自我修正。奖励不再是到终点才给,而是在整个行为过程中都有分布——每一步都可能成为学习对象。
两者核心差异可以用下面这张表看得更清楚:
| 对比维度 | 传统 PBRFT(RLHF/DPO) | Agentic RL |
|---|---|---|
| 状态空间 | 单一提示 {s₀},任务立即结束 | 动态状态流 sₜ ∈ S_agent,任务时长远大于 1 |
| 动作空间 | 纯文本序列 | 文本 ∪ 工具调用 ∪ API 请求 |
| 状态转移 | 确定性终止 | 动态转移函数 P(sₜ₊₁ | sₜ, aₜ) |
| 奖励结构 | 单一标量 r(a) | 步骤级密集奖励 + 稀疏终局奖励 |
| 优化目标 | E[r(a)] | E[Σ γᵗ R(sₜ, aₜ)] |
这张表揭示了一个非常关键的问题:信用分配(Credit Assignment)。在多轮交互中,你如何判断哪些中间步骤真正对最终结果起到了贡献?数学题解到一半,哪个推理步骤是有效的?在多个工具调用中,哪个 API 的返回值真正推动了任务?这些问题在 RLHF 里根本不存在,但在 Agentic RL 中却成了最核心的挑战。
2. 八大工程原则:构建 Agentic RL 系统的完整蓝图
为了方便理解,我们把 Agentic RL 按系统架构设计→训练信号设计→算法优化技巧→训练策略来归类梳理。
2.1 第一层:系统架构设计
原则一:模块化设计(Modular Design)——像搭积木一样构建 Agent 系统
Agentic RL 训练系统的工程架构,核心思想是解耦。一套标准的异步训练流水线通常包含四个阶段:用较高的温度参数采样生成响应;异步汇聚多个处理器的结果;执行 Actor 训练,将模型响应与真实标签对比来计算奖励;计算优势值;如果所有优势都为零,则提前终止。
在架构范式上,业界主要采用两种设计:一是并行架构(Parallel),智能体同时与多个环境实例交互,状态和动作的流转通过统一的训练引擎进行批量更新,效率最高;二是序列架构(Sequential),交互按顺序执行,更适用于需要严格状态依赖的任务。
把策略模型(Policy)、环境交互(Environment)、奖励计算(Reward)和训练更新(Training)彼此分离的模块化理念,正是当前主流框架的设计哲学。
字节跳动的 HybridFlow(开源项目名:verl)就是这一思路的典型代表。它提出了一套分层 API,把 RL 训练中复杂的计算和数据依赖解耦并封装起来,支持经典对齐、推理增强、智能体工具调用等多种场景的框架。核心技术亮点是 3D-HybridEngine——在训练和生成阶段对 Actor 模型进行高效的重新分片,实现零内存冗余,大幅降低通信开销。实验结果表明,HybridFlow 在运行各种 RL 训练任务时,相比现有最优基线,能够带来 1.53 倍到 20.57 倍的吞吐量提升。这篇论文已经被 EuroSys 2025 收录。
类似的架构理念也体现在 MiniMax 的 Forge 框架上——它原生支持数十万 Agent 脚手架和环境交互、支持 200K 上下文长度,实现了每天百万级样本吞吐;还有复旦大学和字节跳动联合开源的 AgentGym-RL,也采用了模块化解耦的统一 RL 框架,支持 27 种以上的多样化任务评测。
2.2 第二层:训练信号设计
原则二:轨迹结构(Trajectory Structure)——Agentic RL 的核心数据单元
如果 RLHF 处理的是“提示-回答”这样的单点数据,那么 Agentic RL 处理的则是 Trajectory——一个完整的闭环循环:用户提出问题→智能体执行动作并调用工具→环境返回反馈→智能体基于反馈做出下一步决策。
这种轨迹结构有三个关键特征:多步序贯决策,单条轨迹包含多个时间步的状态转移,每一步都可能涉及工具调用或环境交互;部分可观测性,智能体无法获取环境的完整状态,只能基于当前观察做决策;稀疏延迟奖励,最终奖励往往在轨迹末端才给出,中间步骤只有过程反馈。
举个具体的例子:用户请求“分析 GitHub 仓库的代码质量”,智能体需要依次调用 GitHub API 获取仓库信息(权重 +0.1),读取主要代码文件(权重 +0.1),分析代码质量(权重 +0.2),生成分析报告(权重 +0.6),总奖励是各步累积的 1.0。这种分步奖励机制使得如何在长链条中准确判断每一步的价值,成为 Agentic RL 的核心技术挑战。
原则三:智能体掩码(Agent Mask)——让 RL 和 SFT 协同工作
单纯的 RL 训练容易导致“奖励黑客”或“策略坍塌”——模型学到一种看似高分、实则偏离正常行为分布的“捷径”。解决方案是把强化学习和监督微调以加权方式融合起来。核心公式可以简洁地表示成:
ECHO = RL + α·SFT
这里的 α 控制着 SFT 损失在整个目标函数中的贡献比例。这就好比教一个人学新技能:既要有探索和实践(RL),也要时不时对照标准范本来巩固基础(SFT)。在实际操作中,α 通常会在训练过程中动态调整——初期设高一些,保证基线能力;后期再降下来,释放探索空间。
原则四:过程奖励(Process Rewards)——奖励设计的两难抉择
在 Agentic RL 中,奖励函数的设计直接决定了模型的学习方向。目前主流的方案有两类:结果奖励(ORM)只对最终结果打分,实现起来比较简单,适合答案明确可验证的任务(比如数学、代码);过程奖励(PRM)对中间每一步逐一评估,能提供密集信号,更适合长链路推理任务(比如多步规划)。
PRM 最大的优势在于缓解稀疏奖励问题——在多轮 Agent 任务里,如果只在轨迹结束时给一个二元反馈(成功或失败),模型很难判断哪些中间步骤真正起到了作用。但 PRM 的训练成本也确实更高,需要高质量的过程标注数据。最近的研究方向包括用蒙特卡洛采样来估计过程奖励,或者引入生成式 PRM 来替代判别式 PRM。
2.3 第三层:算法优化技巧
原则五:优势归一化(Advantage Normalization)——让训练信号更公平
在传统的 PPO 算法中,优势函数是基于全局批次计算的。但在 Agentic RL 场景下,这种方法会带来一个严重问题:不同任务的难度差异可能非常大。简单任务的 Advantage 信号很容易被困难任务的数值给“淹没”掉。
ERPO(Environment-level Relative Policy Optimization)算法提出的解决思路是在同一环境内部进行组内归一化。对来自环境 i 的第 j 个样本,其标准化优势值的计算公式为:
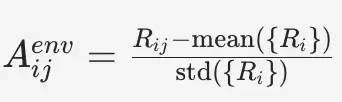
这里统计计算的范围是环境维度,而不是全局批次维度。这就意味着,每一条轨迹的优势值反映的是它在同一难度任务组内的相对表现,而不是和所有难度级别的任务去横向比较。这种“分层比较”的思路,让训练信号变得更加公平和稳定。
这个设计与 GRPO(Group Relative Policy Optimization)的核心思想是一脉相承的——GRPO 会对同一个 Prompt 生成的多个响应,计算组内的均值和标准差来进行归一化,这样一来,就不需要独立的价值网络了。
原则六:可扩展的生成采样(Scalable Rollouts)——工程效率的分水岭
Agent 训练里有一个独特的挑战:生成阶段(Rollout)和训练节点的负载极不平衡。生成阶段需要大量的推理资源,而训练阶段则需要大量的计算资源。业界目前主要有两种架构来应对:一种是分离式架构,把生成和训练在物理上分离开,让它们各自独占 GPU 资源。这样做的好处是两边可以独立扩展,但缺点也很明显——GPU 利用率可能不高,生成阶段会出现等待 I/O 的空闲期。另一种是共置架构,让生成和训练共享同一个 GPU 集群,通过异步调度来实现资源复用。这样能提高硬件利用率,但需要在内存管理和权重同步上做额外的工程优化。
在工程实践层面,字节跳动的 Laminar 框架和 TBA(Trajectory Balance with Asynchrony)等方案代表了最新的进展,它们通过异步解耦,解决了长尾分布生成导致的 GPU 利用率问题。
原则七:稳定性与探索(Stability & Exploration)——打破“回声陷阱”
多轮 Agentic RL 训练面临一个独特的困境,被称作“回声陷阱”(Echo Trap):智能体过度拟合局部奖励推理模式,具体表现是奖励方差崩溃、策略熵下降,还有梯度尖峰。
为了缓解这个问题,学界提出了多种策略,统称为 StarPO-S(稳定变体),主要包括:基于方差的轨迹过滤——在训练前先把低质量的轨迹筛掉;评估器基线化——通过加入基线来减少方差;解耦裁剪——把不同组件的裁剪范围分开处理。
在探索层面,Agentic RL 需要在“利用已知有效策略”和“探索未知行为空间”之间找到一个微妙的平衡。跟单轮任务不同,智能体任务的探索空间不止是不同措辞,还包括不同的任务分解方式、工具调用顺序、记忆读写策略和停止条件选择。
2.4 第四层:训练策略
原则八:任务课程(Task Curriculum)——像教学生一样教 Agent
渐进式缩放交互框架的设计理念源于课程学习(Curriculum Learning):从简单任务入手,逐步提升难度,让智能体在已有能力的基础上,渐进式地学习更复杂的技能。
典型的课程设计包含三个层次:较短的视野 h₁,用来训练基础技能任务,交互步数有限,成功概率比较高,目的是建立基线能力;中等视野 h₂,进一步探索任务,增加交互复杂度;较长的视野 h₃,解决复杂任务,需要长程规划和多步推理。
这个设计和字节跳动 Seed 团队提出的 ScalingInter-RL 方法相呼应——通过分阶段增加交互轮次,在训练早期侧重“利用”以求稳定,后期转向“探索”以求突破。
3. 关键算法:PPO 与 GRPO 的战场
Agentic RL 的算法选择,很大程度上决定了训练效率和最终效果。
3.1 PPO:经典但昂贵的“全功能选手”
PPO(Proximal Policy Optimization)是 OpenAI 提出的经典算法,核心机制是通过裁剪目标函数来限制每次策略更新的幅度,防止模型因为单次更新过大而“跑偏”。
PPO 需要同时维护四个模型:策略模型(Policy)——正在训练的核心模型;参考模型(Reference)——用于 KL 散度约束,防止模型偏离原有分布太远;奖励模型(Reward Model)——给模型生成的回答打分;价值模型(Critic)——预测当前状态下未来能获得多少累计奖励,用来计算优势函数。
PPO 的主要优势在于通用性非常强,可以处理各种复杂的任务场景,而且支持 token 级别的优势估计,能很好地适配长短不一的子轨迹。但它的显存开销也很大——Critic 模型跟策略模型一样大,仅仅是用来估计优势函数,却占用了训练显存的 40%-50% 甚至更多。
3.2 GRPO:DeepSeek 带来的“省显存革命”
GRPO(Group Relative Policy Optimization)是 DeepSeek 团队在 2024 年提出的 PPO 极简改进变体,最早用在 DeepSeek-Math 模型上。GRPO 的核心创新非常简洁:彻底扔掉独立的价值网络(Critic),改用“组内相对竞争”来估计优势。它的工作流程只有四步:第一,对同一个输入问题,让策略模型一次性生成多个回答(比如 32 个),组成一个群体;第二,直接打分,把这些回答送入奖励模型,给出每个回答的实际分数;第三,计算群体统计量,算出这组回答分数的均值和标准差;第四,相对归一化,把每个回答的分数和组内均值做比较,得到相对优势值。
这就好比让同一道题的几十个学生同时交卷,互相比较打分,不需要一个全知的阅卷老师。
GRPO 最大的优势是大幅降低了显存需求,在数学推理、代码生成这类有明确验证器的短任务中表现非常出色。但它在长程智能体任务中的短板也很明显——长短不一的子轨迹很难形成可比较的样本组,导致大量训练数据被白白浪费掉。
一个值得关注的最新动态发生在 2026 年 6 月:智谱发布并开源了 GLM-5.2 大模型。在长程强化学习阶段,智谱选择了放弃 GRPO,回归到基于价值网络的 PPO。核心原因在于:GLM-5.2 瞄准的是长程智能体任务(多轮工具调用、子任务拆解、跨轮反馈),执行阶段长短不一。GRPO 要求样本组内长度一致才能公平比较,这个前提在长程 Agent 场景下根本无法满足。智谱的解法是重新引入 Critic,采用 token 级优势值来适配长短不一的子阶段,并通过框架进行配套的工程优化,最终把后训练时间压缩到了大约两天。
这个技术转向释放了一个非常重要的信号:不存在普适的最优算法。算法选择必须和任务特性深度解耦——短程推理任务适合 GRPO,长程 Agent 任务则可能更需要 PPO 的灵活性。
4. 行业应用与工具链一瞥
Agentic RL 的应用版图已经迅速扩展到了多个关键领域:
| 应用领域 | 典型任务 | 代表工作 |
|---|---|---|
| 搜索与研究智能体 | Deep Research、多步检索 | Search-R1 |
| 代码智能体 | SWE-bench 代码修复 | KAT-Coder-V2、DeepSWE |
| 数学推理 | GSM8K、MATH | DeepSeek-R1、QwenLong-L1 |
| GUI 智能体 | 网页浏览、桌面操作 | CRAFT-GUI、OSWorld |
| 具身智能体 | 机器人控制、家居任务 | ALFWorld、SkillRL |
| 多智能体系统 | 协作规划、竞争博弈 | AgentConductor |
目前,Agentic RL 已经形成了比较成熟的工具链生态:verl(字节跳动的开源框架),支持 PPO、GRPO、REINFORCE 等多种算法,具备混合流编程抽象和异步执行引擎;Agent Lightning(微软),把 Agent 执行建模为 MDP,实现训练与执行的完全解耦,支持 Text-to-SQL、RAG、数学问答等多种任务;Forge(MiniMax),原生大规模 Agent RL 系统;OpenManus-RL(Ulab-UIUC / MetaGPT),集成了 verl 框架,专注于开源 Agentic RL 训练。
5. 挑战与展望
理论前景虽然广阔,但 Agentic RL 仍然面临着多个尚未完全解决的挑战。第一是训练不稳定性:多轮交互很容易引发梯度爆炸、奖励坍缩之类的“训练崩溃”现象。来自 UCLA 和威斯康星大学麦迪逊分校的 ARLArena 框架,尝试通过控制变量法来系统化地分析这些问题,把策略梯度解构成四个核心维度,就像化学实验一样,定位导致不稳定的“罪魁祸首”。第二是信用分配困难:独立研究者 Chenchen Zhang 在 2026 年 4 月发布的综述中,系统梳理了 2024 到 2026 年初的 47 种信用分配方法,得出的结论很有启发性:代表“推理 RL”的方法地图已经趋于成熟,而代表“Agentic RL”的那半边还几乎是一片空白。第三是系统效率瓶颈:在真实环境中进行 Rollout 的成本很高,异步训练框架还需要持续优化。第四是泛化能力验证:在特定环境中训练出来的智能体,到底能不能迁移到全新的场景,还需要更多实证研究来证明。
6. 小结
Agentic RL 不只是算法层面的改进,它代表了一种训练范式的根本性转变:从单轮静态问答转向多轮动态交互,从偏好对齐转向决策优化,从人工设计 Prompt 转向自主学习策略。随着 Forge、verl、AgentGym-RL 这些成熟框架的陆续出现,再加上 GLM-5.2、MiniMax M2.5 等产品的落地验证,Agentic RL 正在从学术研究稳步走向工业实践。




