最近读到TRAE.ai分享的《字节跳动技术副总裁洪定坤:AI Coding 的实践与探索》,里面有不少值得反复琢磨的观点。
最吸引人的是一组数字:过去一年,字节跳动AI代码贡献率增长了6倍多,AI Coding的tokens消耗增长了5倍,AI代码合入率增长超过2倍。而TRAE团队自己,过去半年超过90%的代码由AI写出,人均需求吞吐率提升到1.6倍。
这组数据很有意思。如果只看表面,“AI写代码很快”这点毋庸置疑。90%的代码由AI生成,理论上效率应该提升好几倍。但实际情况呢?人均需求吞吐只提升了大约60%。
这不是说AI Coding不行。恰恰相反,这说明AI Coding已经用得足够深,开始碰到真实软件工程里的那笔总账了。
AI确实能以惊人的速度生成代码——尤其是在原型、小工具、新页面这类近乎空白画布的场景里。但企业研发从来不是空白画布。大多数时候,我们不是从零生成一个Demo,而是在已有系统、已有权限、已有组件、已有历史逻辑和已有技术债的丛林里,小心翼翼地修改一点点东西。
所以这组数字真正揭示的,不是“AI写代码到底快不快”,而是一个更关键的问题:当代码生成变得越来越便宜,软件工程里真正昂贵的东西到底是什么?

90%的代码,不等于10倍的交付效率
过去一年,很多人聊AI Coding,最容易盯着的都是直观指标:AI代码贡献率、采纳率、生成代码量、补全次数、使用人数。这些指标有价值,但也容易制造一种错觉——只要AI写的代码越来越多,研发效率就会同比例提升。
真实情况远没有这么简单。
代码贡献率只能说明“代码是谁写的”,不能说明“需求是不是更快交付了”。生成代码量只能说明“产出了多少代码”,不能说明“这些代码是不是正确、可维护、可上线、可回归”。
一个需求从想法到上线,中间经历的环节远比写代码多:需求理解、方案对齐、上下文补齐、架构约束、组件复用、接口联调、权限处理、测试验证、Code Review、灰度发布、线上观测、历史功能回归。AI可以让其中某一段变快,但不会自动让整个系统变快。
这也是为什么“90% AI代码”和“60%吞吐提升”并不矛盾。前者是局部生产速度,后者才更接近系统吞吐。软件工程真正难的地方,往往藏在这两者之间。
当AI Coding进入真实组织,账就不能只算“代码生成速度”了。要算的是:从需求提出,到功能上线,到线上稳定运行,到后续还能维护,整个链路有没有真的变快。这才是AI Coding从个人体验进入软件工程之后,必须面对的问题。
Vibe Coding的爽感,来自局部变快
Vibe Coding很容易让人兴奋。你有一个想法,和AI聊几轮,它就能生成页面、逻辑、接口调用,甚至帮你跑起来。以前需要几天才能看到的东西,现在可能几十分钟就能摸到一个版本。
这个变化非常大。它让很多原本停留在文档里的东西,快速变成可交互、可体验、可讨论的版本。产品不只是写PRD,设计不只是画静态图,研发也不只是等需求排期。很多想法可以更早被做成动态原型,让大家围绕真实体验讨论,而不是围绕一段文字猜测。
但Vibe Coding也最容易制造一种局部快感。因为你看到的是“代码很快出现了”,但还没看到这些代码进入真实系统时要付出的成本。
能跑,不等于能交付。一个Demo能跑起来,和一个功能进入企业生产系统,是两件完全不同的事。前者关注的是功能大概对不对,后者还要关注它有没有破坏已有逻辑、有没有复用团队组件、有没有进入权限体系、有没有处理异常、有没有性能问题、有没有兼容历史数据、有没有可回归的验证路径。
洪定坤分享里提到一个实验:同一个真实业务需求,用不同Coding模型和Agent框架组合跑了多次,结果在“功能基本正确”上表现不错,但一旦看UI易用性、交互可行性、可靠性、可维护性、性能、兼容性,分数就明显下降。这很真实。AI现在已经很会把“功能写出来”,但真实工程的要求不是“功能大概写出来”。真实工程的要求是:这个功能要在一个复杂系统里长期运行,而且不能把旁边的东西撞坏。
原型驱动开发,真正改变的是共识形成方式
洪定坤分享里还有一个点,我觉得很重要:原型驱动开发。
过去很多研发协作,是从文档开始的。产品写PRD,设计出图,研发再读文档、看设计稿、写技术方案。问题是,文档和静态设计稿很容易让大家“看起来达成一致”,但真正做出来之后,才发现理解并不一样。
AI Coding让这件事发生了变化。因为原型的成本大幅下降了。一个想法不一定先停留在文档里,也可以很快变成一个能点、能看、能跑的动态版本。产品、设计、研发可以围绕这个动态原型讨论,而不是围绕几段文字和几张静态图猜测彼此的意思。
这件事的价值很大。它不是简单提高了写代码速度,而是改变了产品共识的形成方式。很多分歧过去要到开发后期甚至联调阶段才暴露,现在可以在原型阶段提前暴露。很多需求过去需要在PRD里写得很细,现在可以通过一个可交互版本更快被体验和修正。
所以,原型驱动开发并不是“少写点文档”这么简单。它真正改变的是:产品意图可以更早变成一个可体验对象。
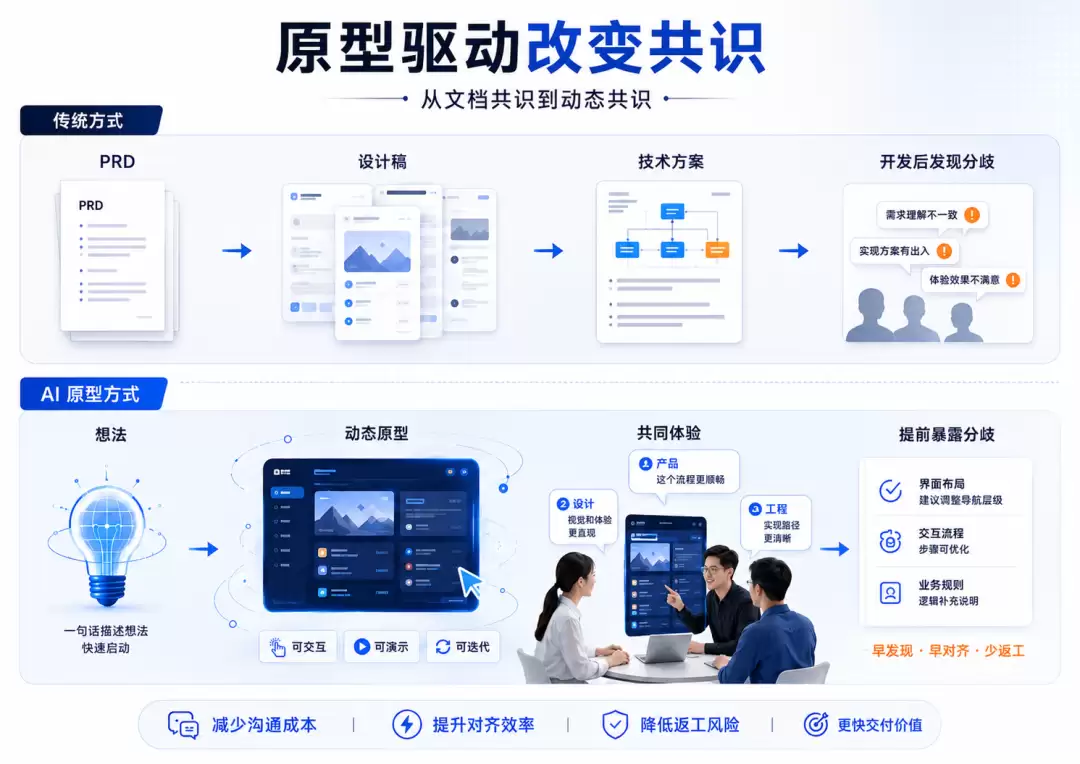
但原型还不是终点。在新增场景里,原型可以帮助团队快速形成共识;可一旦进入企业真实研发,问题还会继续往下走:这个原型如何放回已有系统?如何复用团队组件?如何进入权限、接口、埋点、灰度、发布和回归流程?如何从一个“能看的版本”变成一个“能上线、能维护、能追踪的交付项”?
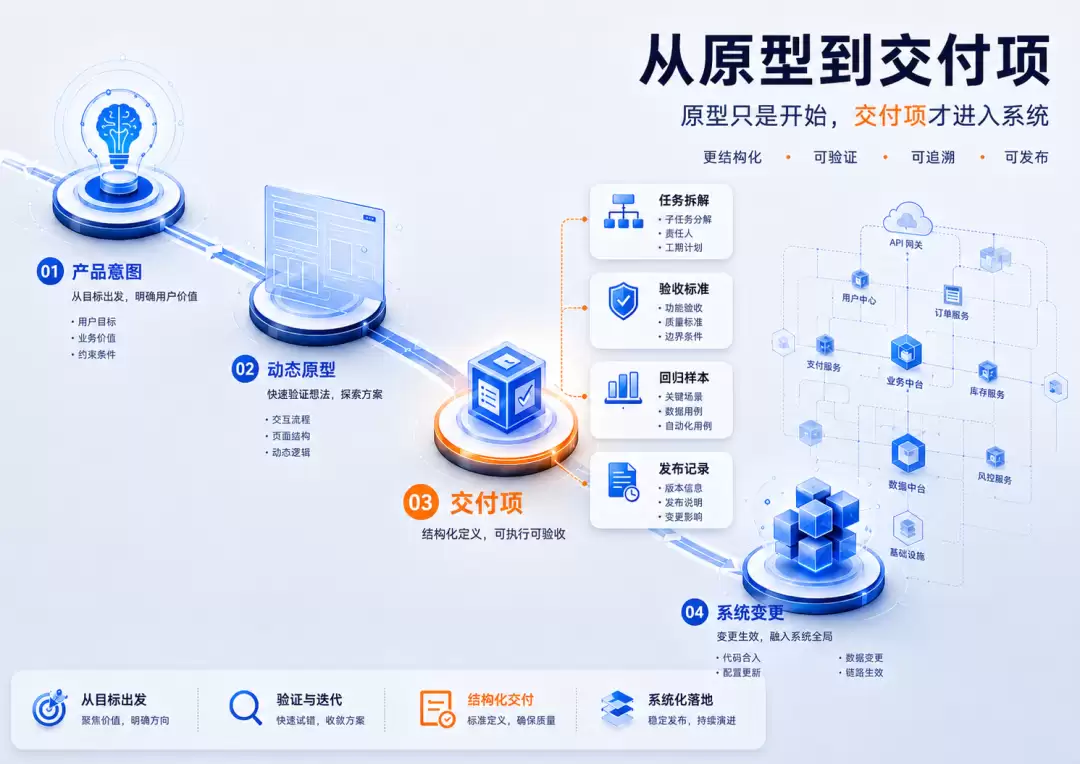
这也是为什么原型驱动还需要再往前走一步。未来真正重要的,不只是从想法生成原型,而是从产品意图进入交付现场。这个产品意图可能来自一个新想法,也可能来自一个线上反馈、一个已有页面、一次业务流程调整,或者一个指标异常。原型解决的是“大家是否看见了同一个东西”,而交付现场要解决的是:“这个东西如何安全地变成系统的一部分”。
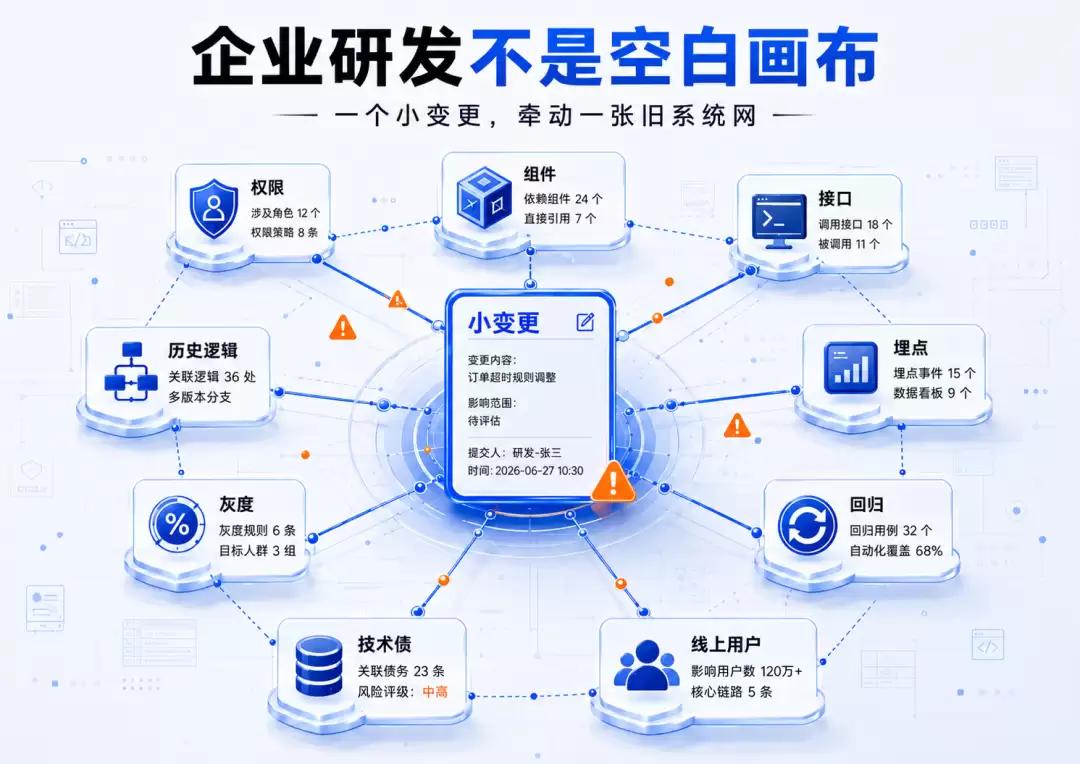
企业研发不是空白画布
很多AI Coding的演示之所以好看,是因为它面对的是空白画布。新建一个Todo应用,新建一个后台页面,新建一个小工具,新建一个落地页,AI的表现通常很惊艳。因为上下文少,历史负担轻,验证路径短,代码从零生成即可。
但企业内部研发的主战场,往往不是空白画布。更多时候,我们面对的是一个已经跑了很多年的系统:里面有历史业务逻辑,有权限体系,有组件规范,有接口约定,有灰度策略,有埋点口径,有不敢轻易动的老代码,也有没人完全说得清的技术债。
这时候,需求不是“帮我生成一个页面”,而是:在这个已有页面里加一个入口,在这个已有流程里改一个判断,在这个已有权限体系下增加一个角色,在这个已有组件体系里补一个交互,在这个已有接口约束下调整一段逻辑,在不影响历史用户的情况下灰度上线。
这类需求的难点,不是从0到1写出代码,而是在1到N的系统里安全地改一点点。AI最会写新代码,但企业最难的是改旧系统。不是AI不能做存量变更,而是存量变更需要更多前置信息和后置验证:上下文、边界、约束、历史逻辑、回归路径。
代码生成只是开始。真正困难的是把这段代码放回系统。不是AI突然变弱了,而是软件工程的复杂度回来了。
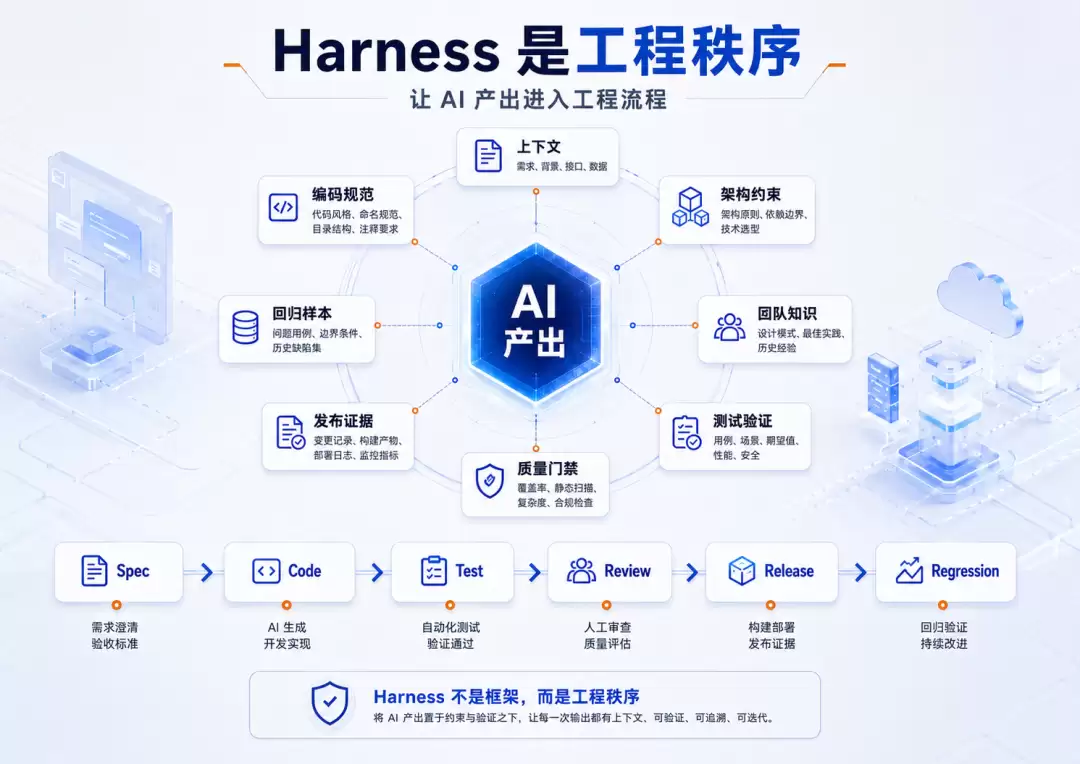
Harness不是时髦词,而是让AI产出进入工程秩序
洪定坤在分享里也提到了Harness。现在很多人讲Harness,容易把它理解成Agent框架、工具调用、自动执行环境。这些都重要,但如果放到企业真实研发里,Harness更像是一套工程秩序。
当AI开始源源不断地产出代码,这些代码如何进入已有研发流程?AI应该知道哪些地方不能改,它应该知道哪些组件必须复用,它应该知道这个页面背后的权限规则,它应该知道哪些历史功能不能被破坏,它应该补上必要的测试和验证,它应该留下足够的执行记录和验证证据,它的产出也应该经过统一的评审、发布和回归流程。
如果这些问题没有答案,AI写得越快,系统风险也会积累得越快。所以Harness不只是让Agent会调用工具,也不是让AI自动跑几条命令。它包括上下文工程、架构约束、团队知识、编码规范、测试用例、浏览器验证、回归样本、质量门禁、发布证据。
说得简单一点:AI Coding到了企业里,拼的不是谁能生成更多代码,而是谁能把AI产出纳入一个可控的工程流程。
这也是为什么AI Coding用得越深,软件工程反而越重要。过去很多隐性的工程经验,现在需要被显性化:哪些是约束,哪些是红线,哪些是历史包袱,哪些是可复用能力,哪些是上线前必须验证的证据。以前这些事情大量存在于工程师的经验里、团队的默契里、Code Review的追问里、测试同学的检查里、上线前的checklist里。AI进来以后,这些隐性经验不可能凭空消失。它们要么被系统化沉淀下来,要么就在一次次生成代码之后,变成新的返工成本和质量风险。
AI Coding真正的分水岭,是从个人技巧变成组织能力
洪定坤分享里还有一个判断,值得单独拎出来:AI不应该只停留在Coding环节,而要进入更完整的软件研发流程。比如,AI可以根据功能需求和当前上下文编写Spec,可以通过Browser Use自动打开浏览器验证功能正确性,可以在发现问题后继续修复,也可以在确认功能正确后提交代码、推进发布。
这件事表面上看,是AI能做的步骤更多了。但更深一层的变化是:AI Coding正在从少数高手的个人技巧,变成组织可以复用的工程流程。
早期用AI Coding,往往很依赖个人能力。有人很会写Prompt,很懂怎么给上下文,很知道如何拆任务,也知道生成代码后该怎么验证,所以他的效率提升会很明显。换一个人,可能同样的工具、同样的模型,结果就完全不同。这不是模型能力的问题,而是组织能力没有沉淀下来。
如果一个团队想真正用好AI Coding,就不能只期待每个工程师都变成Prompt高手。更重要的是,把那些反复有效的经验变成默认流程:需求如何转成Spec,上下文如何提供,任务如何拆解,代码如何验证,问题如何回滚,结果如何记录,经验如何复用。
这也是为什么Skill、规范、工作流、验证样本、质量门禁、发布记录这些东西会变得越来越重要。它们看起来不像“写代码”本身,却决定了AI Coding能不能从个人爽感变成组织生产力。一个工程师用AI写代码很快,这只是第一步。一个团队能把AI写出来的东西稳定纳入研发流程,才是真正的系统化AI Development。
人人都能写代码后,专业不会消失
洪定坤分享里还有一个很有意思的例子:产品同学用Vibe Coding把一个需求做出来了,页面能看,流程也能跑,但研发看完之后仍然说需要排期。这类场景以后会越来越多。
AI降低了代码生产门槛,产品、设计、运营、业务同学都可能把自己的想法做成一版能跑的东西。这不是坏事,反而是很大的变化。它会让想法更早被验证,让沟通更直接,让产品讨论不再只停留在文档和静态图上。
但代码生产门槛下降,不代表系统责任下降。这和“设计会不会消失”是类似的问题。AI可以让产品做出更像样的原型,让研发更容易还原UI,让设计资产更容易被代码消费。但这并不意味着设计专业消失了。不同场景下,设计的价值会变化:有些轻量场景可以由产品和AI快速完成,有些复杂场景仍然需要专业设计对体验、品牌、交互、信息层级负责。
软件工程也是一样。人人都能写代码,不等于人人都能对系统负责。产品可以更快验证想法,设计可以更靠近实现,运营可以更快搭建工具,研发也会从“唯一能写代码的人”,变成更关注系统结构、工程约束、质量验证和交付责任的人。
门槛下降的是代码生产,不是专业责任。未来的协作不是“谁写出来谁上线”,而是更多角色都可以参与到代码生产和产品验证中,但所有产出都要进入统一的架构、规范、验证和交付流程。专业不会消失,只是专业的位置会变化。有些事情会融合进产品,有些事情会融合进研发,有些事情会被工具自动化。但越是进入真实系统,越需要有人对边界、质量和长期后果负责。

代码变便宜了,变更责任变贵了
这也是我看到洪定坤这篇分享时最有共鸣的地方。如果只停留在“AI能不能写代码”,这件事已经没有太多悬念了。AI会写,而且会越来越会写。它会写业务代码,会改Bug,会补测试,会生成页面,会调用工具,也会在Agent框架里执行越来越复杂的任务。
但软件研发真正难的地方,恰恰不只是写出代码。真正的问题是:AI写完之后,组织如何确认它做对了?如何确认它没有破坏历史系统?如何确认它符合团队架构和工程规范?如何让产品、设计、研发围绕同一个交付对象协作?如何把一次成功的AI Coding经验沉淀成下一次可复用的流程,而不是永远依赖某个高手临场发挥?
这些问题,才是AI Coding进入真实软件工程后的主战场。过去,代码生产本身很贵,所以工程师的大量价值体现在“把代码写出来”。现在,AI正在让代码生产变便宜。可一旦代码变便宜,另一些东西就会变得更贵:上下文、约束、验证、回归、协作、发布责任,以及对系统长期可维护性的判断。
这也意味着,未来的软件研发工作台不应该只围绕“写代码”展开,也不应该只从PRD或原型开始。它还应该能从产品现场开始:一次用户反馈、一个线上问题、一段历史流程、一个指标异常,都可能被组织成可拆解、可执行、可验证、可追踪的交付项。原型让团队更早看见同一个东西,交付项让团队真正围绕同一个变更推进。
所以,90%的代码由AI写出之后,软件工程没有结束,反而真正开始。企业最终需要的不是更多代码,而是一次次可控的系统变更。代码可以由AI写,但系统要有人负责。





