 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述
DeepSpeed 发布了 v0.19.2 补丁版本。从更新内容来看,这并非一次简单的小修小补,而是一场围绕训练稳定性、ZeRO 能力增强、DeepCompile 修复、测试与 CI 完善、混合精度改进以及新翻跟斗支持展开的集中更新。
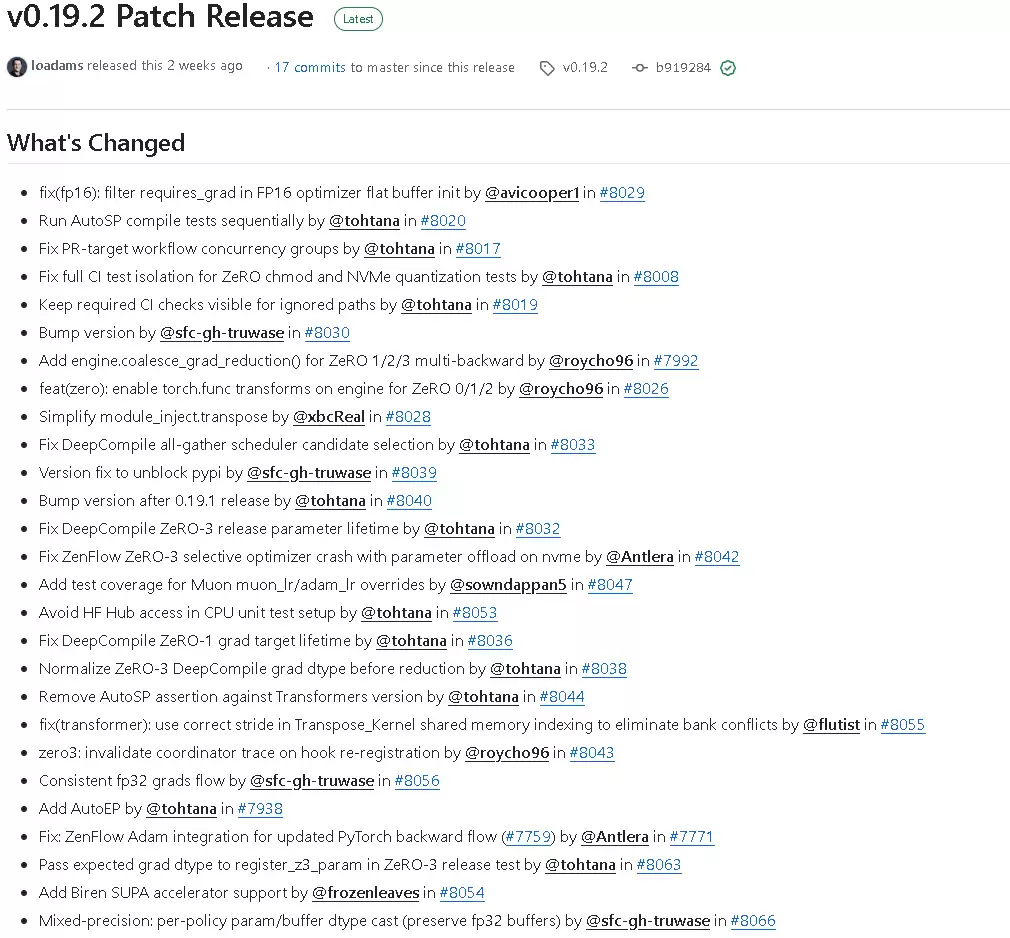
这次版本有几个很明显的特征:一共包含 27 次提交,涉及 114 个文件变更,有 17 位贡献者参与,更新时间线从 5月27日 持续到 6月17日。更新的内容覆盖了 FP16 优化器、ZeRO 0/1/2/3、DeepCompile、ZenFlow、AutoSP、AutoEP、Transformer 内核、混合精度策略、CI 与测试体系,以及新硬件翻跟斗支持。如果只用一句话概括,那就是:这是一次“硬核”的补丁发布。
这次更新到底改了什么?
按照版本说明,本次 DeepSpeed v0.19.2 的变更可以分成几个板块来看。
FP16与梯度处理相关修复
1. FP16优化器 flat buffer 初始化时过滤 requires_grad
更新内容中提到,修复了 FP16 优化器 flat buffer 初始化时需要过滤 requires_grad 的问题。这意味着在 FP16 优化器初始化扁平缓冲区时,现在会更严格地区分哪些参数真正参与梯度计算。这一修复的直接意义在于:避免不需要梯度的参数被错误纳入 flat buffer 初始化流程,减少不必要的状态构建,降低潜在的参数管理错误,让 FP16 优化器初始化逻辑更加严谨。对于使用混合精度训练并依赖 DeepSpeed 优化器管理大规模参数的场景,这一修复非常关键——flat buffer 是参数和优化状态管理中的核心环节,一旦纳入了不该参与梯度的参数,后续训练链路就可能受到影响。
2. 保持一致的 FP32 grads 流转
版本更新中还提到,保持一致的 fp32 grads flow。这个改动聚焦于 FP32 梯度流的统一性和一致性。从字面上看,它意味着 DeepSpeed 在梯度从产生到归约、再到后续优化处理的链路中,对 FP32 梯度的流转方式进行了统一。这对降低不同模块之间梯度类型不一致带来的问题、提高混合精度训练时梯度处理的稳定性、为后续 ZeRO、DeepCompile、混合精度策略配合打下更一致的基础,都很有价值。
3. ZeRO-3 DeepCompile 在归约前规范化梯度 dtype
更新中还有一项非常具体的修复:在 ZeRO-3 DeepCompile 中,梯度在 reduction 前进行 dtype 规范化。这说明在 DeepCompile 与 ZeRO-3 组合使用时,梯度类型在归约之前会先被统一。这样做可以避免由于 dtype 不一致导致的归约异常,减少不同训练路径之间的行为差异,强化 ZeRO-3 与编译优化路径之间的兼容性。对于大规模训练来说,梯度归约链路非常敏感,一旦 dtype 管理不一致,就可能出现精度问题、运行错误甚至性能波动。这一修复虽然看起来“底层”,但实际价值很高。
ZeRO能力大幅增强:不仅修,还在扩
本次 DeepSpeed v0.19.2 中,ZeRO 相关内容非常多,而且不仅是 bug fix,还有实打实的功能增强。
1. 新增 engine.coalesce_grad_reduction(),面向 ZeRO 1/2/3 的 multi-backward
版本说明明确给出了一个新功能:为 ZeRO 1/2/3 multi-backward 新增 engine.coalesce_grad_reduction()。这是本次最值得关注的功能增强之一。它说明 DeepSpeed 在 ZeRO 1、ZeRO 2、ZeRO 3 这几个阶段中,针对多次反向传播场景,引入了新的梯度归约能力接口。从名字上可以看出,这一能力强调的是梯度归约的合并、针对 multi-backward 的处理、统一适配 ZeRO 1/2/3。这意味着在复杂训练图、需要多次 backward 的任务中,DeepSpeed 的梯度处理能力进一步完善,使用 ZeRO 时也拥有了更明确的接口支持。
2. ZeRO 0/1/2 支持在 engine 上启用 torch.func transforms
版本中还有一项功能增强:为 ZeRO 0/1/2 启用 engine 上的 torch.func transforms。这个更新很重要,表明 DeepSpeed 的 engine 能够在 ZeRO 0、1、2 场景下,更好地兼容 torch.func 相关变换能力。其意义在于扩展 DeepSpeed engine 与 PyTorch 新函数式变换能力的配合范围,提升 ZeRO 0/1/2 下的可用性,为更灵活的训练逻辑和函数式编程方式提供支持。
3. ZeRO-3:hook 重新注册时使 coordinator trace 失效
更新中提到:ZeRO-3 在 hook 重新注册时,使 coordinator trace 失效。这类问题通常出现在复杂生命周期管理里。当 hook 被重新注册后,旧的 trace 可能已经不再准确,如果继续复用,就可能造成错误行为。现在 DeepSpeed 明确在这种情况下让 coordinator trace 失效,从而避免沿用过期状态。这个修复体现了 ZeRO-3 在运行时状态管理上的进一步严谨化。
4. 修复 ZeRO-3 release parameter lifetime
版本中专门修复了 DeepCompile 场景下 ZeRO-3 release parameter lifetime。这个描述指向参数释放生命周期管理问题。当参数在 ZeRO-3 与 DeepCompile 联动下被释放时,如果生命周期管理不正确,就可能出现参数过早释放、过晚释放或状态不一致等问题。v0.19.2 对此进行了修复,意味着 ZeRO-3 在 DeepCompile 路径下的参数管理更稳定。
5. 修复 ZeRO-1 grad target lifetime
同样,版本中还修复了 DeepCompile 场景下 ZeRO-1 grad target lifetime。这说明不仅是 ZeRO-3,ZeRO-1 在与 DeepCompile 配合时,梯度目标对象的生命周期也存在需要修正的地方。现在这个问题被纳入修复,表明 DeepSpeed 对不同 ZeRO 阶段与 DeepCompile 的协同稳定性都进行了补齐。
6. 在 ZeRO-3 release test 中传入预期 grad dtype
更新中还有一项测试层面的修正:在 ZeRO-3 release 测试里,为 register_z3_param 传入预期 grad dtype。测试不只是“能不能跑”,更要验证行为是否符合预期。这里将预期梯度类型明确传入测试流程,说明 DeepSpeed 对 ZeRO-3 参数注册与梯度类型的预期关系做了更严格的校验。这能帮助后续版本更早发现与 grad dtype 相关的问题。
DeepCompile是这次版本修复密度最高的模块之一
从更新列表可以看出,DeepCompile 是此次 v0.19.2 中修复最密集的模块之一,涉及多个细节问题。
1. 修复 DeepCompile all-gather scheduler candidate selection
版本更新中提到,修复了 DeepCompile all-gather scheduler 的候选选择问题。这说明在 all-gather 调度器的候选项选择逻辑上,之前存在缺陷,现在已修复。all-gather 调度本身就是分布式训练中的关键路径,这一问题若处理不当,可能影响调度行为正确性、参数聚合路径稳定性、编译优化后的执行效果。因此,这项修复虽然表述简短,但对 DeepCompile 的实际可用性很重要。
2. 修复 ZeRO-3 release parameter lifetime
这项修复已经在前文提到,但它同时也是 DeepCompile 的关键问题之一。它说明 DeepCompile 与 ZeRO-3 联动时,参数释放生命周期管理是本次重点修补对象。
3. 修复 ZeRO-1 grad target lifetime
同样,这也是 DeepCompile 稳定性修复的一部分。这意味着 DeepCompile 不是单独一条链路,而是在不同 ZeRO 模式下都进行了细节补强。
4. 归约前规范化 ZeRO-3 DeepCompile grad dtype
这项修复也属于 DeepCompile 关键稳定性改进。DeepCompile 在高性能路径上往往对类型、生命周期和调度都非常敏感,而这次 v0.19.2 基本把这几块都覆盖到了。综合来看,DeepSpeed v0.19.2 对 DeepCompile 的修正方向非常明确:调度选择更正确,参数生命周期更稳定,梯度目标生命周期更清晰,梯度 dtype 在 reduction 前更规范。这几项组合在一起,代表 DeepCompile 可用性和稳定性显著加强。
ZenFlow相关修复也值得关注
ZenFlow 在本次版本中间出现了两项修复,且都比较关键。
1. 修复 ZenFlow ZeRO-3 selective optimizer 在 parameter offload 到 NVMe 时的崩溃问题
版本说明中写到,修复了 ZenFlow ZeRO-3 selective optimizer 在 parameter offload 到 NVMe 时的 crash。这说明在 ZeRO-3、ZenFlow、selective optimizer、parameter offload、NVMe 这几个机制叠加的场景下,之前可能发生崩溃问题。而这种组合往往出现在更复杂、更接近真实大模型训练环境的部署场景中。这个修复的价值在于提高 NVMe offload 场景稳定性,降低 selective optimizer 组合使用风险,改善 ZenFlow 与 ZeRO-3 协同时的可靠性。
2. 修复 ZenFlow Adam 对更新后 PyTorch backward 流程的集成
版本中还提到,修复了 ZenFlow Adam 对更新后 PyTorch backward flow 的集成问题。这说明由于 PyTorch backward 流程发生了变化,ZenFlow Adam 集成层需要适配,v0.19.2 已经完成修复。其意义很直接:避免因上游 backward 流程变化导致集成失效,提高 ZenFlow Adam 与当前训练链路的兼容性,降低用户在升级环境后遇到问题的概率。
AutoSP与AutoEP:自动并行能力继续扩展
这次更新里,AutoSP 和 AutoEP 都有动作。
1. AutoSP 编译测试改为顺序执行
更新内容中提到,AutoSP compile tests sequentially。这意味着 AutoSP 编译测试现在按顺序执行,而不是并行执行。这一改动一般是为了提高测试稳定性、降低资源冲突、避免测试互相影响。
2. 移除 AutoSP 对 Transformers 版本的断言
版本中还提到,移除了 AutoSP 对 Transformers 版本的断言。这个改动释放出一个明显信号:AutoSP 在版本兼容性约束上变得更灵活,不再通过硬性断言限制 Transformers 版本。这可能带来的直接变化包括:减少因版本断言导致的阻塞,提高用户环境适配空间,让 AutoSP 在更多安装组合下更容易运行。
3. 新增 AutoEP
本次版本中还有一个非常醒目的新增项:新增 AutoEP。虽然版本说明中没有展开更多细节,但“新增”本身已经说明这不是修复,而是功能扩展。在整个更新列表中,AutoEP 是少数明确属于新增能力的内容之一,代表 DeepSpeed 的自动化并行能力版图进一步扩大。
混合精度与参数/缓冲区类型策略升级
混合精度相关改动是本次版本另一条主线。
1. mixed-precision:按策略对参数和缓冲区进行 dtype cast,同时保留 fp32 buffers
版本说明中写到,混合精度支持按策略对参数和缓冲区进行 dtype cast,同时保留 fp32 buffers。这是一项非常关键的能力改进。它说明 DeepSpeed 对 mixed-precision 的处理不再只是简单统一转换,而是按策略分别处理参数和缓冲区,对某些缓冲区保留 FP32 精度。这种做法的意义在于:让混合精度策略更加细粒度,在性能与数值稳定性之间更灵活地平衡,避免某些关键缓冲区因过度降精度而影响行为。对于依赖复杂模块、对 buffer 精度敏感的训练场景,这种按策略保留 FP32 buffers 的能力非常实用。
2. 一致的 FP32 grads flow
前面提到的 FP32 梯度流统一,也与混合精度体系形成呼应。从整体上看,v0.19.2 在混合精度方向上做的不只是“能跑”,而是让参数和 buffer 的 dtype 策略更清晰,让梯度类型流转更一致,让 reduction 前的 dtype 处理更规范。这说明 DeepSpeed 在数值链路管理上又向前推进了一步。
Transformer与模块注入路径也有改进
除了分布式和训练引擎层面的修复,本次版本对底层实现细节也做了优化。
1. 简化 module_inject.transpose
更新中提到,简化了 module_inject.transpose。虽然这项改动描述很简短,但“简化”通常意味着代码路径更清晰、维护成本更低,也可能减少不必要的复杂分支。对于模块注入链路来说,越简洁越有利于稳定性与后续维护。
2. 修复 Transformer 中 Transpose_Kernel 的共享内存索引 stride,消除 bank conflicts
这是一个很有含金量的底层修复:在 Transformer 相关实现中,使用正确的 stride 进行 Transpose_Kernel 共享内存索引,从而消除 bank conflicts。这说明之前该内核在共享内存访问方式上存在 stride 问题,现在通过修正索引方式消除了 bank conflict。这一点非常重要,因为 bank conflict 会直接影响内核执行效率和访问行为。这项修复体现出 DeepSpeed v0.19.2 并不仅仅是在做框架层 bug 修补,也在深入到底层 kernel 实现细节进行优化。
CI、工作流与测试体系:这次更新“工程味”很浓
如果仔细看变更列表会发现,v0.19.2 有相当多的更新投向了 CI、工作流和测试体系。这说明该版本很重视工程稳定性和发布质量。
1. 修复 PR-target workflow 的 concurrency groups
更新内容包括修复 PR-target workflow 的 concurrency groups。这说明工作流并发分组逻辑存在问题,现在进行了修复。它关系到 CI 执行过程中的并发控制与任务协调,是工程侧很重要的一环。
2. 修复 ZeRO chmod 和 NVMe quantization 测试的完整 CI 隔离
版本中提到,修复了 ZeRO chmod 和 NVMe quantization tests 的完整 CI 隔离。这个修复很关键,因为测试隔离不充分时,经常会出现彼此污染、环境残留、偶发失败等问题。本次修复说明 DeepSpeed 对这类测试进行了更严格的隔离处理,提升测试结果可信度。
3. 对被忽略路径保持 required CI checks 可见
还有一项工程性很强的更新:对 ignored paths 保持 required CI checks visible。这意味着即使某些路径被忽略,所需的 CI 检查仍然保持可见。这对工作流透明度和审核流程来说很重要,可以避免因为路径忽略而导致状态不明确。
4. 避免 CPU 单元测试 setup 访问 HF Hub
版本中还修复了在 CPU unit test setup 中避免访问 HF Hub。这一点非常务实。测试初始化阶段访问外部服务,容易引入网络依赖、不稳定性和环境差异。现在将其避免后,CPU 单元测试会更独立、更可复现。
5. 为 Muon 中 muon_lr/adam_lr 覆盖增加测试覆盖
更新列表还包括为 Muon 的 muon_lr/adam_lr overrides 增加测试覆盖。这说明本次不仅修问题,也在补测试,确保相关学习率覆盖逻辑有明确验证。
6. ZeRO-3 release 测试中传入预期 grad dtype
前面提到的这项变更,本质上也是测试体系增强的一部分。它使测试能够更精确地验证梯度类型行为是否符合预期。综合来看,v0.19.2 的测试和 CI 更新说明 DeepSpeed 团队这次非常重视“稳定发布”这件事,不只是修功能,还在修发布流程、测试隔离、依赖控制和可见性问题。
版本号与发布流程相关修复
这次版本里还有几项直接关系到发版流程的变更:Bump version;Version fix to unblock pypi;Bump version after 0.19.1 release。这三项放在一起看,说明此次发版过程中,版本号管理与发布链路本身也是修复重点之一。尤其是为了不阻塞 PyPI 的版本修复,以及在 0.19.1 发布后继续进行版本号调整,这反映出 v0.19.2 不只是代码层面更新,发布流程本身也经过了重新校正。
新硬件支持:加入 Biren SUPA accelerator support
本次更新中还有一个明确的新能力:新增 Biren SUPA accelerator support。这意味着 DeepSpeed v0.19.2 增加了对 Biren SUPA 翻跟斗的支持。对于硬件生态扩展来说,这是非常重要的一步。这类更新通常意味着 DeepSpeed 的适配硬件范围继续扩大,更多训练环境具备接入条件,框架在异构翻跟斗生态中的延展性进一步增强。
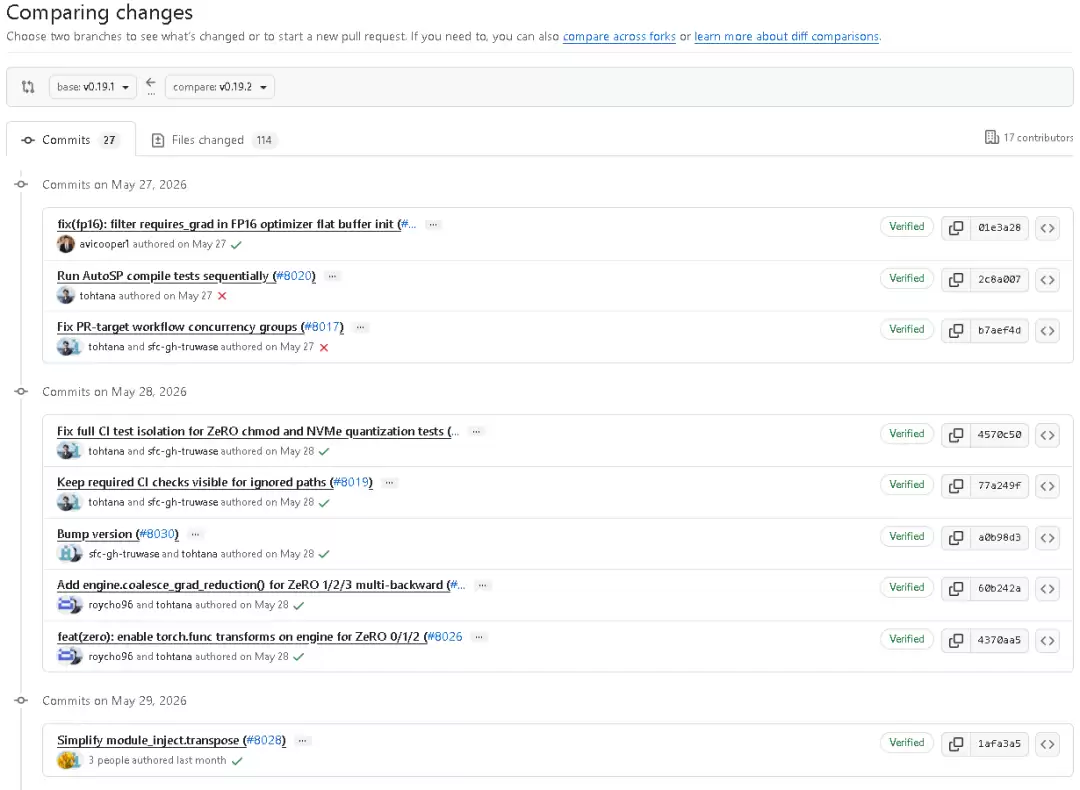
按时间线梳理本次更新,更能看出修复重点
为了更直观看出这次版本的推进节奏,可以按时间线做一次整理。
5月27日
- 修复 FP16 优化器 flat buffer 初始化时过滤
requires_grad - AutoSP 编译测试改为顺序执行
- 修复 PR-target workflow 的 concurrency groups
5月28日
- 修复 ZeRO chmod 和 NVMe quantization 测试的完整 CI 隔离
- 对被忽略路径保持 required CI checks 可见
- 版本号更新
- 新增
engine.coalesce_grad_reduction()以支持 ZeRO 1/2/3 的 multi-backward - 为 ZeRO 0/1/2 启用 engine 上的
torch.functransforms
5月29日
- 简化
module_inject.transpose
5月30日
- 修复 DeepCompile all-gather scheduler 候选选择问题
- 修复版本问题以解除 PyPI 阻塞
5月31日
- 在 0.19.1 发布后再次更新版本号
6月2日
- 修复 DeepCompile 场景下 ZeRO-3 release parameter lifetime
6月5日
- 修复 ZenFlow ZeRO-3 selective optimizer 在 parameter offload 到 NVMe 时的崩溃问题
6月6日
- 为 Muon 的
muon_lr/adam_lr覆盖增加测试覆盖
6月8日
- 避免 CPU 单元测试 setup 访问 HF Hub
6月10日
- 修复 DeepCompile 场景下 ZeRO-1 grad target lifetime
- 在 ZeRO-3 DeepCompile 中,reduction 前规范化 grad dtype
- 移除 AutoSP 对 Transformers 版本的断言
- 修复 Transformer 中
Transpose_Kernel共享内存索引 stride,消除 bank conflicts - ZeRO-3 在 hook 重新注册时使 coordinator trace 失效
6月11日
- 保持一致的 FP32 grads flow
6月12日
- 新增 AutoEP
- 修复 ZenFlow Adam 对更新后 PyTorch backward flow 的集成
6月14日
- 在 ZeRO-3 release 测试中,为
register_z3_param传入预期 grad dtype
6月16日
- 新增 Biren SUPA accelerator support
6月17日
- 混合精度支持按策略对参数和缓冲区进行 dtype cast,并保留 fp32 buffers
从这个时间线可以看出,这个版本并不是某一天集中完成,而是围绕多个主题持续推进,最后汇总成了 v0.19.2。
这次版本最值得关注的五个核心看点
如果要从全部更新中提炼出最值得用户关注的点,主要有以下五个方向:
1. ZeRO 能力不只是修复,而是继续增强
- 新增 multi-backward 相关的
engine.coalesce_grad_reduction() - 支持 ZeRO 0/1/2 上的
torch.functransforms - 修复 ZeRO-3 hook re-registration 的 trace 失效问题
- 补强 ZeRO-3 和 ZeRO-1 在 DeepCompile 路径中的生命周期问题
2. DeepCompile 成为重点修复对象
- 修 scheduler candidate selection
- 修 ZeRO-3 parameter lifetime
- 修 ZeRO-1 grad target lifetime
- 修 ZeRO-3 reduction 前 grad dtype
3. ZenFlow 与 PyTorch/NVMe 场景兼容性增强
- 修 ZeRO-3 selective optimizer NVMe offload crash
- 修 ZenFlow Adam 对更新后 backward flow 的集成
4. 混合精度与梯度 dtype 管理更成熟
- per-policy 的 param/buffer dtype cast
- 保留 fp32 buffers
- consistent fp32 grads flow
- reduction 前 grad dtype normalize
5. 工程稳定性明显加强
- CI 并发分组修复
- 测试隔离修复
- ignored paths 下 required checks 保持可见
- CPU unit test 避免访问 HF Hub
- Muon 覆盖测试增强
- ZeRO-3 release test 更严格
总结
DeepSpeed v0.19.2 虽然被定义为一个补丁版本,但从更新量和涉及范围来看,它的分量并不轻。
这次更新至少释放出几个非常明确的信号:DeepSpeed 正在持续强化 ZeRO 的复杂训练场景能力;DeepCompile 的稳定性正在被快速补齐;混合精度、梯度类型、参数生命周期这些底层链路正在变得更严谨;自动并行能力继续扩展,AutoEP 已加入;工程质量、测试隔离和发版流程也被放到了重要位置;硬件生态继续延伸,新增 Biren SUPA 支持。
如果你当前关注的是 ZeRO 多反向传播能力、DeepCompile 稳定性、ZenFlow 在新 backward 流程下的兼容性、AutoSP/AutoEP 能力演进、混合精度下更细粒度的 dtype 策略、训练框架对新翻跟斗的支持,那么 DeepSpeed v0.19.2 这次更新非常值得认真关注。
从版本说明给出的全部信息来看,这不是一个“只有零散修复”的小版本,而是一次围绕分布式训练核心链路进行集中打磨的补丁发布。对于追求训练稳定性、兼容性以及引擎能力演进的用户来说,v0.19.2 的信息密度很高,含金量也很高。
附:DeepSpeed v0.19.2全部更新清单整理版
为方便收藏和二次传播,下面给出不遗漏的完整清单:
- 修复 FP16 优化器 flat buffer 初始化时过滤
requires_grad - AutoSP 编译测试改为顺序执行
- 修复 PR-target workflow 的 concurrency groups
- 修复 ZeRO chmod 和 NVMe quantization 测试的完整 CI 隔离
- 对被忽略路径保持 required CI checks 可见
- 版本号更新
- 为 ZeRO 1/2/3 multi-backward 新增
engine.coalesce_grad_reduction() - 为 ZeRO 0/1/2 启用 engine 上的
torch.functransforms - 简化
module_inject.transpose - 修复 DeepCompile all-gather scheduler 候选选择问题
- 修复版本问题以解除 PyPI 阻塞
- 在 0.19.1 发布后再次更新版本号
- 修复 DeepCompile 场景下 ZeRO-3 release parameter lifetime
- 修复 ZenFlow ZeRO-3 selective optimizer 在 parameter offload 到 NVMe 时的崩溃问题
- 为 Muon 的
muon_lr/adam_lr覆盖增加测试覆盖 - 避免 CPU 单元测试 setup 访问 HF Hub
- 修复 DeepCompile 场景下 ZeRO-1 grad target lifetime
- 在 ZeRO-3 DeepCompile 中,reduction 前规范化 grad dtype
- 移除 AutoSP 对 Transformers 版本的断言
- 修复 Transformer 中
Transpose_Kernel共享内存索引 stride,消除 bank conflicts - ZeRO-3 在 hook 重新注册时使 coordinator trace 失效
- 保持一致的 FP32 grads flow
- 新增 AutoEP
- 修复 ZenFlow Adam 对更新后 PyTorch backward flow 的集成
- 在 ZeRO-3 release 测试中,为
register_z3_param传入预期 grad dtype - 新增 Biren SUPA accelerator support
- 混合精度支持按策略对参数和缓冲区进行 dtype cast,并保留 fp32 buffers




