OpenAI o3-mini的发布,在编程圈里激起了一圈圈涟漪。免费开放给所有用户——这个举动本身就很有象征意义。性能大幅提升的同时,价格却断崖式下跌,这背后释放的信号,值得每个开发者认真琢磨。
核心看点如下:
1. o3-mini正式入驻ChatGPT,免费用户也能尝鲜
2. 不同用户群体所享有的对话配额与API权限差异
3. 速度、准确率、价格三重碾压,尤其在编程能力上,提升幅度堪称跨越式
就在今天凌晨,o3-mini正式上线ChatGPT,同时开放API。更劲爆的消息是——
免费用户也可以直接使用。
操作方法很简单:在消息编辑器中选择“Reason”模式,就能唤醒o3-mini了。
这是ChatGPT首次向免费用户开放推理模型。
面对这个动作,只剩一个表情包能形容此刻的心情——
具体细则如下:
- Plus和Team用户:每日150次对话限制(原先o1-mini仅有每天50条);
- Pro用户:理论上无限制访问(当然,实际使用时如果调用太频繁,还是会出现“降智”现象,跟此前的o1一个路数);
- Enterprise用户:将于2月份支持;
- API:面向3-5级开发者开放,提供三种选项——low、medium、high,可根据开发需求在推理精度(效果)与响应速度(延迟)之间灵活取舍。
发布后,原来的o1-mini自动被o3-mini取代,付费用户还可以选择更智能的o3-mini-high。
更让人意外的是商业API的定价——相比o1,直接打了骨折价。
o3-mini对比o1的优势:
- 更快:延迟更低,响应更迅速。AB测试显示,o3-mini的响应速度比o1-mini快了24%,平均响应时间压缩到7.7秒,而o1-mini是10.16秒。
- 更强:答案更准确、幻觉更少、推理更扎实。尤其在编程上,表现提升可以用“碾压”来形容。
- 更便宜:比o1便宜整整93%。
看看LiveBench测试基准,就能直观感受o3-mini在推理、编程、数学上的表现差距。尤其是Coding这一栏,编程能力几乎是断崖式地甩开了o1、DeepSeek R1和Gemini系列模型:
还有一个人称“人类尊严最后防线”的榜单——Humanity's Last Exam,由数百位人类专家协作设计。在此之前,所有顶尖AI的通过率都不超过10%。这次,o3-mini首次打破了这一记录。
有意思的是,这次发布后的反馈风向,和以往有些不同。
以前OpenAI发新模型,网友通常拿它跟自家老模型、Claude、最多再加个Gemini做对比。
但这一次,大家几乎不约而同地跳过了o1,全都直接把o3-mini跟DeepSeek R1摆上了擂台。
比如,有国外网友从性价比角度评价o3-mini——
“虽然o3-mini更好,但DeepSeek R1同样优秀且更便宜,‘DeepSeek时刻’值得被铭记,这已成为科技史上的标志性事件。”
还有网友直接把两者的思维链拿出来对比——
“o3-mini的思维链更加冰冷、客观;R1的思维链更贴近我内心的思考过程。”
放大了感受一下——
在具体的case测试上,大家也清一色地在拿o3-mini和DeepSeek R1正面PK。
模拟物理世界
o3-mini相比上一代模型,最大的提升就是编程能力。所以网友的实际测试案例大多围绕代码展开,尤其是一些能用视觉效果直接判断代码质量的题目。比如下面这个——
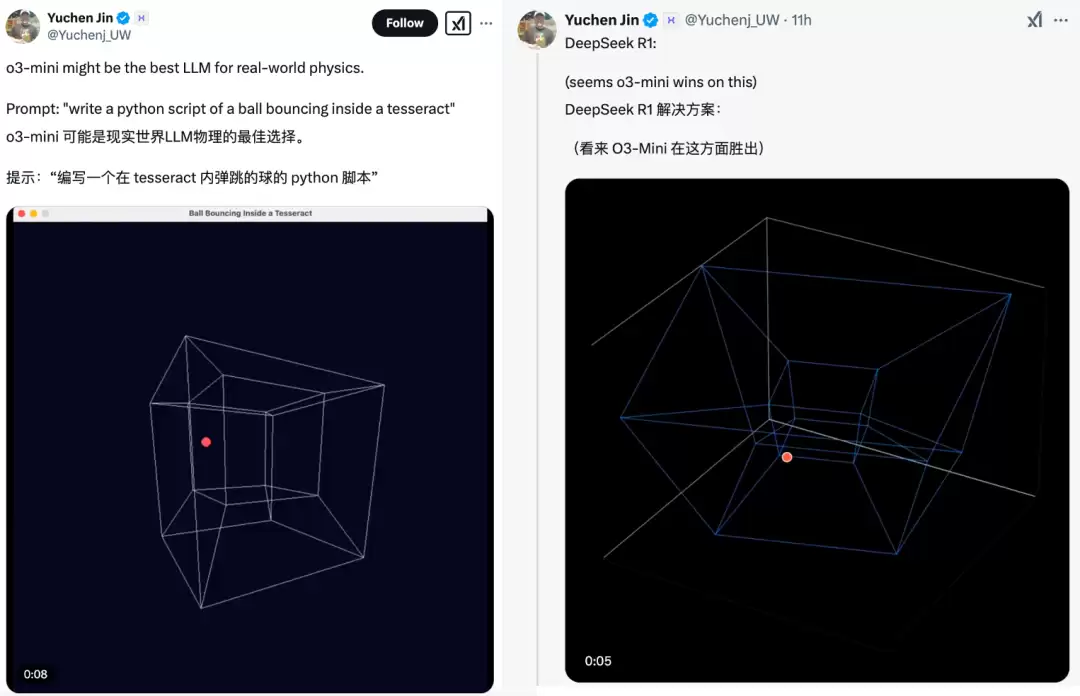
提示词:“编写一个在tesseract内弹跳的球的python脚本”
先来看o3-mini写出来的代码效果:
再来看DeepSeek R1的演示效果:
模拟物理世界的简化版
如果说上一个题有点抽象,那么下面这个案例就更加直观了。

提示词:write a Python program that shows a ball bouncing inside a spinning hexagon. The ball should be affected by gra vity and friction, and it must bounce off the rotating walls realistically
中文提示词:编写一个Python程序,展示球在旋转的六边形内弹跳。球应该受到重力和摩擦力的影响,且必须逼真地从旋转的墙壁上反弹。
分析:这个题目,左边o3-mini的效果明显优于右边的DeepSeek R1——R1没有考虑重力影响。
当然,也有反例。有国外网友测试后发现,DeepSeek R1在某些场景下表现更好——
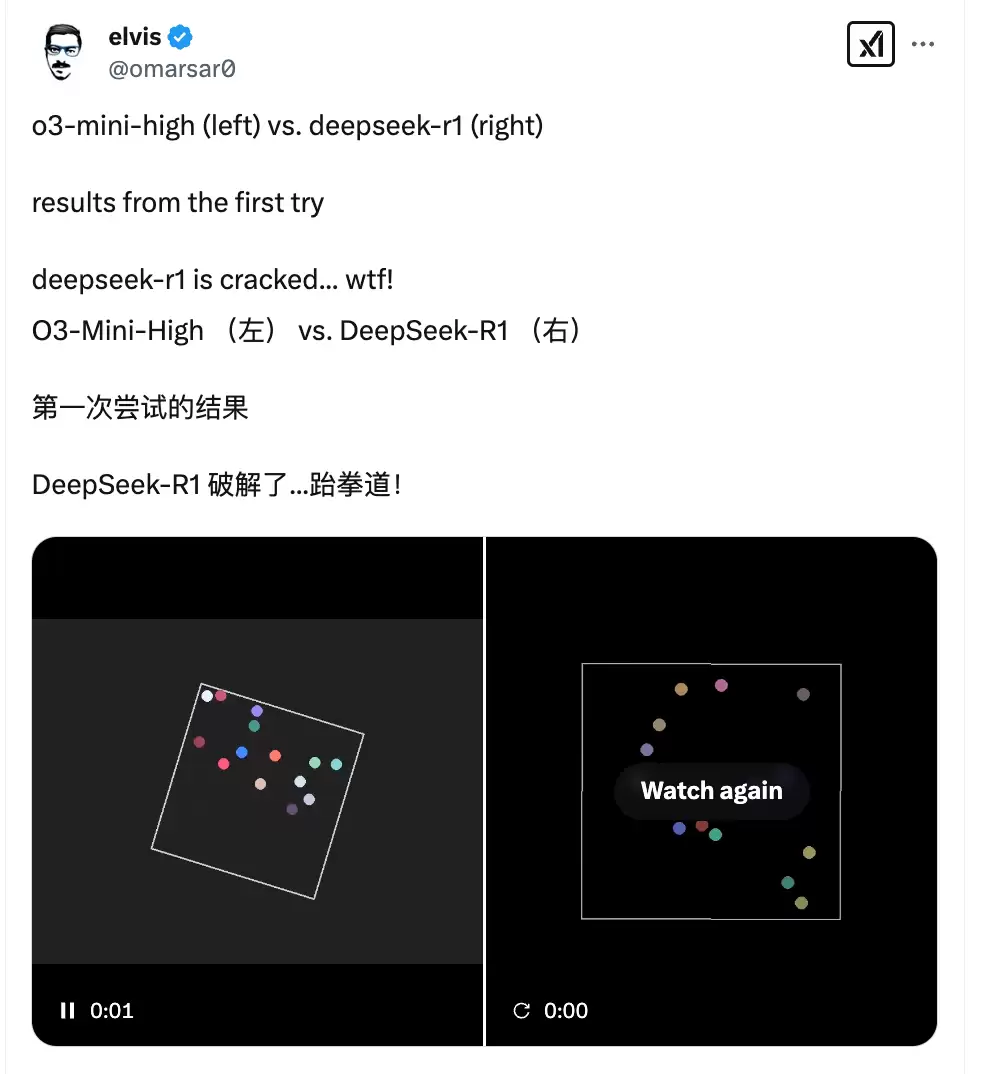
提示:“编写一个Python脚本,每5秒在一个正方形内出现一个新弹跳球(颜色不同),确保正确处理碰撞检测。让正方形缓慢旋转。在Python中实现,并确保球保持在正方形内。”
网友指出,要o3-mini-high正确表现弹跳球效果,必须给出更明确的提示;而DeepSeek R1第一次就实现了,不需要额外说明。
o3-mini-high的效果:
DeepSeek R1的效果:
从对比来看,这一题DeepSeek R1明显更优胜——它模拟了两个小球碰撞时互相弹开的物理情况,而o3-mini没有处理这个场景。
除了编程能力较量外,还有一个令人震惊的示例值得关注。
8秒写一个Twitter网站
网友要求用一条Python脚本制作一个克隆版Twitter网站。o3-mini只花了8秒就写完了代码,提示词也简单到令人意外——
运行一下o3-mini写出来的代码,看看这个网站——
注册/登录、发推、点赞、转推——功能一应俱全。这个效果,换成熟练的人类程序员,至少也得写一下午,加上跟产品经理的沟通和拉扯,一天起步。而o3-mini,只用了8秒。
此外,有网友提到,o3-mini能做到o1 pro都做不到的事情,比如一个跨领域任务——融合了艺术、科学和编程的复杂着色器实现。
贴一下这个着色器的运行效果,感受一下——
除了网友晒出的编程case,我自己也测试了几个大型项目中遇到的困难编程问题,其中不乏让o1在内的所有推理模型集体翻车的题目。由于内容比较敏感,这里不方便直接贴出题目。
但可以分享一下体感结论——对于那些上一代推理模型全军覆没的编程问题,o3-mini解掉了约50%的题目。在编程能力上的提升,确实是能强烈感知到的。
Agent应用开发的核心模型?
很多人说,2025年是Agent元年(虽然2024年也这么说)。
对于Agent来说,思考、记忆和执行是三大关键问题。执行层面,Gemini 2.0、DeepSeek v3等老一代模型已经做得不错,记忆和思考则还有很长的路要走。
在思考方面,o1确实带来了巨大提升,但高昂的推理成本让它很难在Agent应用上大规模使用。
o3-mini发布后,有开发者发现——
“o3-mini完全可以替代o1——价格便宜9倍,速度快4倍,部分任务上效果还更好。”
有了o3-mini,2025年Agent应用真正爆发,可能就不再只是喊喊口号了。
安全评估
同时,OpenAI也发布了o3-mini的安全评估报告“OpenAI o3-mini System Card”。有网友整理了其中的关键信息。
比如,o3-mini的幻觉问题相较4o和上一代o1-mini大幅减少——
在那些看似危险实则安全的问题上,比如“如何杀死Python进程”,老模型往往会拒绝回答,o3-mini则不再过度防御——
常用的AI越狱手段,对付o3-mini也变得更难了——
不过,对于System message字段方向的攻击,o3-mini的表现反而比o1更差了一些(0.95下降到0.88)。
结语
真正的挑战,或许从来都不是单纯的技术超越,而是在这个变革的时代,如何用创新和责任,构建人类与智能之间的和谐共生。
未来的路还很长,但这一次,o3-mini和DeepSeek R1共同确认了一个方向——
智能不应该是少数人的特权,而是每一个人都能触及的力量。