就在今天,Qwen2.5-1M 正式开源——涵盖 7B 和 14B 两个尺寸,全部向社区开放。更重要的是,它已与 vllm 深度集成,内置稀疏注意力机制,推理速度直接提升 3 到 7 倍。可以说,这是长上下文模型领域一次至关重要的迭代升级。
技术报告与模型权重现已同步发布:
- 技术报告地址:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
- Hugging Face 模型库:https://huggingface.co/collections/Qwen/qwen25-1m-679325716327ec07860530ba
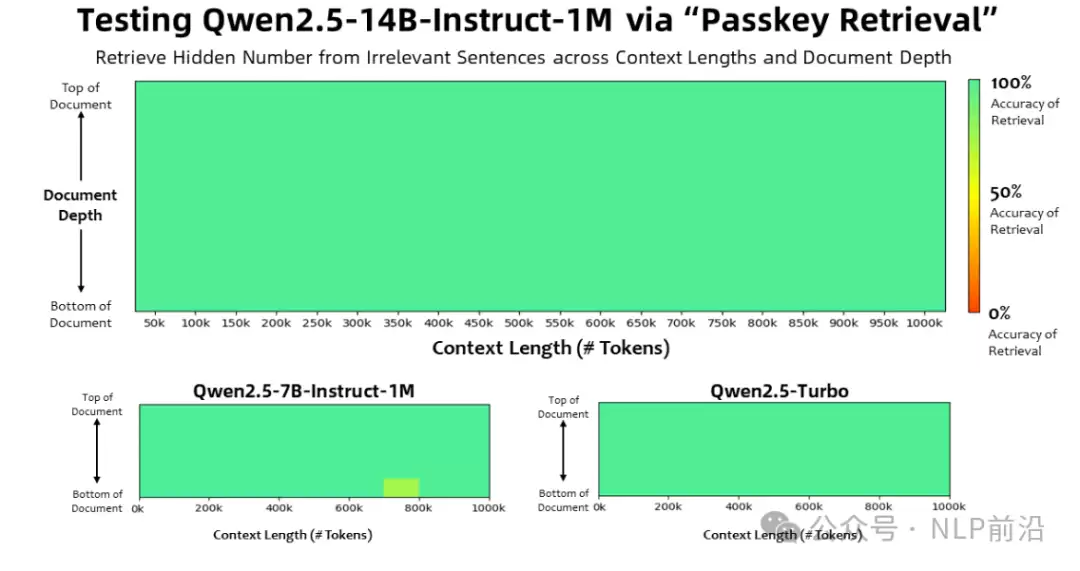
先看性能表现:14B 模型在经典的“大海捞针”测试中取得了全绿成绩,7B 版本也仅有少量失误。更难得的是,在将上下文长度大幅提升的同时,短序列场景下的表现依然保持出色,兼顾了长与短的双重需求。
在训练策略上,团队采用了逐步变长训练的方式,先训练至 256K 上下文,再通过长度外推技术进一步扩展。外推部分使用了 DCA(Dynamic Chunk Attention)策略——其核心思想是将较大的相对位置按 chunk 分组,映射为较小的数值,从而有效缓解位置编码在极端长度下的压力。
最后谈谈硬件门槛。若要处理长达 1M 的序列:
- Qwen2.5-7B-Instruct-1M:至少需要 120GB 显存(多 GPU 总和)。
- Qwen2.5-14B-Instruct-1M:至少需要 320GB 显存(多 GPU 总和)。
如果当前 GPU 资源不足,依然可以使用 Qwen2.5-1M 来处理短任务,灵活性相当不错。
最后,祝大家新年快乐!