在爱奇艺的 Opal 机器学习平台体系中,特征中心扮演着至关重要的角色。本文将深入探讨其定位、设计逻辑以及在实际业务中的核心价值。
01 综述
Opal 是爱奇艺大数据团队自主研发的一站式机器学习平台,核心目标清晰:加速特征迭代与模型训练效率,从而助力业务实现更优收益。平台覆盖从特征生产、样本构建、模型探索、模型训练到模型部署的完整链路。
特征作为模型训练的基石,其重要性不言而喻。因此,如何让算法工程师借助平台能力快速迭代特征、达成业务预期收益,就成为平台方必须回答的关键命题。在 Opal 中,特征的生产、存储与访问等环节共同构成了“特征中心”的主体功能。本文将重点阐述这一模块。关于 Opal 的更多背景信息,可参阅另一篇文章《Opal 机器学习平台:爱奇艺数智一体化实践》。
02 特征中心是什么
简而言之,特征中心是一个用于生产、共享和管理机器学习模型特征的工具平台。算法工程师或数据分析人员可在此便捷地创建和分享特征,平台侧则负责解决特征生产与使用过程中的各类问题,最终目标在于提升特征的迭代效率。
从适用场景来看,几乎所有依赖特征的业务都离不开它,典型的如推荐、广告、风控等领域。特征表注册到平台后,平台会自动完成在线与离线表的构建,确保两者一致。更关键的是,在特征表仅存储一份的前提下,即可向多人共享,显著降低资源成本。时间成本同样大幅缩减——过去需要编写复杂 SQL 的操作(如导出训练表、数据导表),如今通过 Web UI 拖拽几下即可完成。
03 特征中心解决的问题
算法模型本质上是一个映射函数:输入数值型向量,输出基于某个目标对候选集的排序。在爱奇艺的场景中,离线训练时,工程师需要先从原始日志抽取特征,再构建训练样本;在线服务时,需根据用户 ID 和视频 ID 查询原始特征,然后通过 DSL 配置将其转换为训练特征,最后调用预测服务获取结果。
通常情况下,提升模型效果只有两条路径:
- 模型侧优化:优化模型结构、调优超参数,通过调整参数不断优化效果指标;
- 数据侧优化:从数据质量入手提升模型效果,此时模型被视为固定不变。但很多业务同学容易陷入误区——模型效果不佳就认为是模型本身的问题,却忽略了数据集质量对效果的巨大影响。
行业内有句共识:“数据(特征)决定模型上限,模型结构及调参只是逼近这个上限”。由此可见,数据侧优化对整体效果的提升至关重要。那么,如何让工程师高效地进行数据侧优化?答案正是特征中心。平台需要解决数据侧优化过程中遇到的各种挑战:
- 如何应对海量用户请求?爱奇艺拥有海量观影用户,对特征的访问极为频繁,高 QPS 的请求是特征中心必须承受的核心挑战之一;
- 如何满足特征的实时化要求?在广告、推荐、风控等场景中,为保证模型输出效果,特征的实时性要求越来越高;
- 如何提高特征的扩展性和灵活性?业务场景日益复杂,特征需求灵活多变。从基础特征到统计序列特征组,从离线特征的简单统计到实时特征的窗口计算、交叉特征等,业务方需要平台能支持这些不断衍生出的新需求;
- 如何满足快速迭代的业务诉求?平台提供的 DSL 要足够场景化,特征生产链路应尽量减少代码编写,底层的计算引擎、存储引擎对业务完全透明,彻底释放业务在计算、存储选型和调优上的负担。
具体而言,特征中心的功能至少应覆盖以下几个方面:
- 特征输入:如何管理业务线的数据源,包括各类文本文件、Parquet 文件、Hive 表等;
- 特征计算:如何表达特征计算逻辑,从原始日志中高效地抽取所需特征;
- 特征存储:计算出的特征存放在什么系统中,这涉及存储成本与访问效率之间的权衡;
- 特征转换:从原始特征到模型特征的转换,包括各类 DSL 的解析与转换。
04 特征中心整体架构
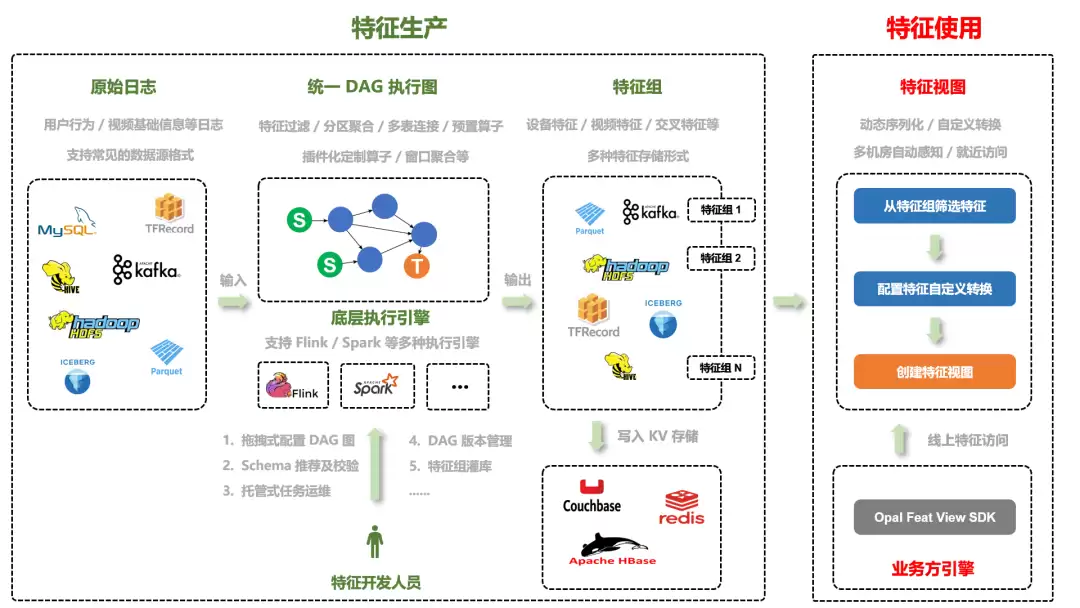
根据特征在整个链路中的不同角色,可将其划分为特征生产与特征使用两大类:
- 特征生产:解决如何从各种大数据源进行特征计算,以及结果如何存储的问题。平台设计了一套高效的计算算子,配合拖拽式 Web 页面,托管运维用户的生产任务,帮助用户高效管理特征;
- 特征使用:解决特征的线上访问问题。通过引入“特征视图”概念,实现特征复用、自定义转换等功能,并提供 SDK 实现特征的动态序列化、多机房自动感知、就近访问等,为业务方屏蔽底层存储细节,使其专注于业务逻辑。
05 特征中心功能介绍
从功能上看,特征中心可分为特征的生产与使用。进一步,根据目标特征的生成时延,特征生产又可细分为离线特征组和实时特征组。下面逐一展开。
离线特征组
训练机器学习模型时,通常需要先预处理一组数据,将原始数据转化为特征向量或特征集,以便模型更好地理解和使用。例如统计某个用户过去一周的购买行为,并将结果作为一个特征。为提高效率,这些特征会被提前计算并存储,这就是离线特征组。
Opal 的离线特征组基于用户通过拖拽构建的 DAG 图,从 Source 节点读取数据(可以是 Hive 表、Iceberg 表或 TFRecord、Parquet 文件),经过中间的计算节点进行转换,最终将特征写入 Target 节点描述的存储系统。目前 Opal 支持各类常见的特征存储格式。
特征元数据管理、特征生产 DAG 配置
在平台上拖动左侧的算子进行组合,即可生成一个 DAG 任务配置。围绕该 DAG,平台还支持对特征元数据和特征 Schema 进行管理。
SQL 语法解析及 Schema 推断
平台提供语法解析与校验功能。用户在配置期间就能实时看到每个算子输出的字段详情,无需等到提交任务阶段才发现错误,调试时间显著缩短。
特征质量校验及预警
平台支持对已产出的特征进行检查,例如特征的零值率、空值率、分位数、最大最小值等,并提供可视化页面,方便用户查看特征质量。
任务重跑及异常告警
目前已有推荐中台、广告算法、业务风控等多个团队接入了离线特征生产模块,产出了三百余个特征组。这种托管式的生产模式,大幅简化了业务方在特征生产上的投入时间,使其能将更多精力投入到其他链路中。
实时特征组
离线特征组是预先计算并存储的特征,而实时特征组包含的是实时或近实时生成的特征。这类特征的获取与计算,依赖强大的数据基础设施和实时处理能力。实时特征组在推荐系统、欺诈检测、金融交易等实时决策场景中至关重要。Opal 提供了基于 DAG 的实时特征加工流图,可从 Kafka、Iceberg、MySQL 摄入数据,利用平台集成的算子进行计算,最终输出到 Kafka 或其他存储介质中。离线特征组的其他功能,也正在逐步迁移到实时模块中。
实时特征生产 DAG 配置
平台支持特征元数据与 Schema 管理,通过各类算子的组合即可完成实时特征的配置。
滑动窗口算子示例
通过简单的配置即可实现窗口转换,用户无需编写复杂的 SQL 语句,开发成本大大降低。
窗口特征合并及状态复用
对于不同窗口周期但滑动步长相同的特征计算任务,Opal 支持将其合并到同一个窗口中,大幅节省状态空间,减少资源占用。
特征视图
统一离在线特征组端侧访问
离线特征组和实时特征组解决了特征的配置、加工和存储问题,但产出的特征存储在各种离线存储介质中,无法被线上引擎直接使用。这时就需要一个灌库服务,将特征从离线存储导入在线缓存(如 Couchbase、Redis、HBase 等)。Opal 通过特征视图实现灌库,并提供统一客户端实现特征读取,用户无需关心灌库细节。
特征转换及特征衍生
部分场景下,用户需要对已有特征进行转换,比如取对数或四则运算后再返回给下游。Opal 提供了一套灵活高效的 DSL 特征转换表达式,基本格式和语法如下:
语法解释: - 函数名为平台预定义的关键字 - 参数可以是特征变量或各种类型的字面值常量 - 数值集合常量,如:[1, 2, 4] - 字符串集合常量,如:['aaa', 'bbb'] - 特征变量,视图内任意合法的特征名称,由反引号标识,例如:`city` - 数字常量,任意合法的数字,例如:123 - 字符串常量,由单引号标识,例如:'hello world' - 集合常量,由中括号标识
转换示例:
(示例内容略)
Java 客户端接入,简化特征获取流程
平台提供了 Java SDK,屏蔽了底层存储资源。用户无需对接各类复杂的缓存,通过引入 SDK 即可访问特征。
运维监控大盘
接入客户端后,SDK 会自动向指标服务投递指标。用户可以通过 Grafana 大盘观察服务运行情况。
06 业务接入
目前,广告、推荐、风控等业务已不同程度地接入了 Opal 特征中心,并进行了相应的升级改造。接入后,各业务的特征迭代效率提升了 0.4 倍到 3 倍不等,业务引擎侧获取特征的时延降低了约 50%,特征侧的需求堆积实现了零积压。关于业务接入前后的架构变迁以及具体收益,可参考另一篇文章《Opal 机器学习平台:爱奇艺数智一体化实践》中的业务实践小结。后续也会邀请业务同学撰写基于 Opal 的特征评估架构改造经验分享。
07 未来规划
未来,Opal 特征中心计划从以下几个方面增强功能:
- 特征共享:随着平台管理的特征越来越多,重复计算的问题不可避免。平台需要实现特征分享,避免用户重复生产;
- 实时特征的质量校验:离线特征已有相对完善的校验模块,但实时特征也需要一套质量监测服务;
- 特征热度计算:根据特征被线上访问的情况,推算出每个特征的热度,帮助业务方进行特征的重要性评估。