脑肿瘤诊断面临的一大挑战是肿瘤大小和位置的多样性。经验丰富的神经外科医生需要反复比对、精准分析MRI扫描片,才能出具可靠报告。然而,许多发展中国家熟练医生匮乏,系统化的肿瘤知识库也不完善,导致诊断过程耗时且繁琐。技术手段能否突破这一困境?基于向量数据库的智能图像搜索正给出令人振奋的答案。
简单来说,KDB.AI的语义搜索功能能像人脑一样理解图像间的语义关联——即使查询内容与数据库样本不完全吻合,也能快速从海量脑部扫描数据中调出最相似的影像。这种能力不仅能显著提升诊断效率,还能辅助医生更精准地锁定病情。下面,我们逐步拆解技术流程:如何将图像数据存入向量数据库,如何通过预训练神经网络生成向量嵌入,以及如何利用KDB.AI的向量数据库产品实现嵌入空间上的相似检索。
本教程涵盖以下关键步骤:加载图像数据、创建图像向量嵌入、将嵌入存入KDB.AI、查询数据库表、搜索与目标图像相似的图像,以及最后的清理工作——删除数据库和表格。首先解决数据获取问题。
### 注意:以下代码块仅用于在Colab等环境中下载数据
### 该单元从GitHub仓库下载图像数据
import requests
import os
from PIL import Image
import io
!mkdir -p ./data/meningioma_tumor
!mkdir -p ./data/glioma_tumor
!mkdir -p ./data/no_tumor
!mkdir -p ./data/pituitary_tumor
def get_github_repo_contents(repo_owner, repo_name, branch, folder_path):
# 构建API地址
api_url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/contents/{folder_path}?ref={branch}"
# 发送请求并处理响应
contents = requests.get(api_url).json()
# 若本地目录不存在则创建
fPath = f"./data/{folder_path.split('/')[-1]}"
for item in contents:
# 递归处理子文件夹
if item['type'] == 'dir':
get_github_repo_contents(repo_owner, repo_name, branch, f"{folder_path}/{item['name']}")
# 下载并保存文件
elif item['type'] == 'file':
file_url = f"https://raw.githubusercontent.com/{repo_owner}/{repo_name}/{branch}{folder_path}/{item['name']}"
print(file_url)
r = requests.get(file_url, timeout=4.0)
r.raise_for_status()
with Image.open(io.BytesIO(r.content)) as im:
im.sa ve(f"{fPath}/{item['name']}")
# 开始下载
get_github_repo_contents(
repo_owner='KxSystems',
repo_name='kdbai-samples',
branch='main',
folder_path='/image_search/data'
)

本示例使用的数据集来自Kaggle的脑肿瘤分类数据集,包含大量MRI脑部扫描图像,按是否存在肿瘤及类型分为四类:神经胶质瘤、脑膜瘤、垂体瘤和无肿瘤。原始数据集中有Training和Testing两个文件夹,各自按类别组织图像。作为预处理,我们将所有图像统一缩放到(224,224,3)尺寸(高度、宽度均为224像素,RGB三通道),并将文件名重命名为“类别_唯一ID”的形式。
在后处理阶段,我们使用原始数据的Training文件夹训练ResNet模型——后续生成嵌入时使用的正是该模型。而Testing文件夹经过上述处理后重命名为data,直接用于本教程的搜索演示。注意,这些图像不在模型的训练集中,因此嵌入生成不会出现过拟合问题。
接下来,从Testing目录(即data文件夹)中提取所有子文件夹下的图像文件路径。这些路径将交给下一节的函数来生成嵌入。
def extract_file_paths_from_folder(parent_dir: str) -> dict:
image_paths = {}
for sub_folder in os.listdir(parent_dir):
sub_dir = os.path.join(parent_dir, sub_folder)
image_paths[sub_folder] = [
os.path.join(sub_dir, file) for file in os.listdir(sub_dir)
]
return image_paths
image_paths_map = extract_file_paths_from_folder("data")
借助image_dataset_from_directory()函数,可以快速将图像及其对应的类别标签加载为适合嵌入的格式。该函数会根据目录推断标签,并以分类模式输出。
dataset = image_dataset_from_directory(
"data",
labels="inferred",
label_mode="categorical",
shuffle=False,
seed=1,
image_size=(224, 224),
batch_size=1,
)
创建图像嵌入的关键是选用一个已经在脑肿瘤分类问题上训练过的神经网络。这里我们选用基于ResNet-50主干网络的模型。ResNet-50在ImageNet上预训练后,经过迁移学习,重新训练以适应MRI脑部扫描图像的分类任务。迁移学习的优势在于不必从零开始训练,而是借用ImageNet中学到的通用特征,再针对脑肿瘤数据进行微调,从而大幅缩短训练时间,并提升分类效果。
实际使用的模型可直接从KxSystems的仓库加载:
model = from_pretrained_keras("KxSystems/mri_resnet_model")
该模型包含四个层次:ResNet-50、Flatten层、两个Dense层。ResNet-50本身是一个庞大的多层结构,只是被封装成一个名称;Flatten层将ResNet-50的输出展平成2048维的特征向量;最后两个Dense层负责将特征向量映射到4类肿瘤分类结果。
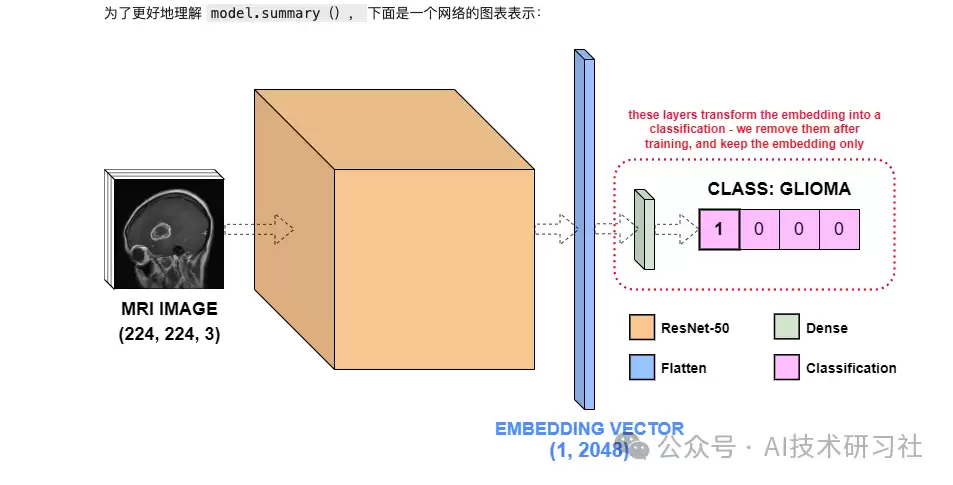
尽管Dense层对训练分类器至关重要,但我们的任务是获取图像嵌入,而非输出类别概率。因此,通过调用pop()移除模型最后两层,让模型直接输出2048维的ResNet-50特征向量——这就是我们所需的嵌入。
接下来,遍历数据集,用model.predict()为每张图像生成2048维嵌入,同时保存对应的类别标签。
# 创建空数组用于存储嵌入和标签 embeddings = np.empty([len(dataset), 2048]) labels = np.empty([len(dataset), 4])
# 对数据集中的每张图像,获取其嵌入和类别标签
for i, image in tqdm(enumerate(dataset), total=len(dataset)):
embeddings[i, :] = model.predict(image[0], verbose=0)
labels[i, :] = image[1]
嵌入创建完成后,需要存入向量数据库才能高效检索。
通过第二个测试图像查询,可以看到返回的相似大脑扫描与目标图像高度匹配,且都属于同一类别。这样的结果能为医生提供有力佐证,使诊断过程更加可靠。