首先介绍开放域问答(ODQA)任务。通俗来说,就是让机器从海量文档中精准定位答案并生成回复。整个流程中,文档分块是核心环节,主要依赖检索增强生成(RAG)模型实现。具体过程为:先将长文档切分为独立的块,再检索与问题相关的块,最后将块和问题一同输入语言模型(LLM)以生成答案。听起来很顺畅,对吧?但问题恰恰出现在分块这一环节。
现有研究大多聚焦于优化检索与生成,文档分块工作反而被边缘化。然而,分块的重要性不容忽视:分块的粒度是否恰当、语义是否完整,直接影响检索准确度。如果检索到的块内容不完整——要么上下文脱节,要么混杂过多无关信息——即使LLM性能再强大,也很难从碎片中筛选出关键信息。
因此,本文提出了一种全新框架——Logits-Guided Multi-Granular Chunker (LGMGC)。其核心思路是将长文档切分为粒度不同、上下文丰富、自成一体的块。实验结果证实:LGMGC不仅能改善检索效果,集成到RAG管道后,性能也超越了现有分块方法。
相关工作
目前该领域的研究覆盖广泛,但各有局限:
Recursive Chunking:依据预设结构(如段落分隔符)切块。明显缺陷是每个块的上下文信息可能不够充分。
Small2Big:使用小文本块进行检索,然后扩展为更大的块提供给LLM合成器。思路可取,但受限于原始块质量。
Semantic Chunking:通过句子或段落间的嵌入距离判定断点,确保块内连贯。然而,面对语义跨度大的内容,容易产生尴尬的切分边界。
利用LLMs提取文本段:近期研究借助LLM将文档转化为“命题”——封装独立的事实,超越了传统段落或句子级分块。但该方法依赖大模型,成本高昂。
LumberChunker:自动识别最优分割点,通过迭代将段落喂给LLM实现。
in-context retrieval:最新方向,利用LLM编码的隐藏状态解码相关段落,完全绕过文档分块。
这些研究均证明了基于LLM的分块策略具有潜力,但问题同样突出:将大规模LLM集成到RAG管道成本高、处理慢。尤其是那些采用GPT-4或Gemini-1.5等专有模型的方案,在企业级应用中还需考虑IT安全。相比之下,本文提出的方法仅需一次前向传递的logits信息,计算效率大幅提升。
核心算法
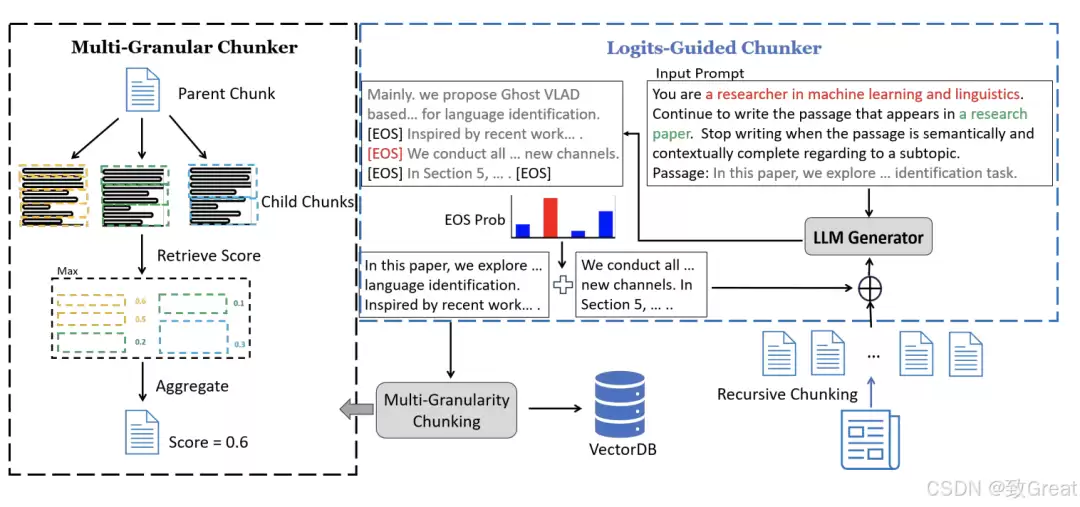
LGMGC框架包含两大组件:Logits-Guided Chunker和Multi-Granular Chunker。两者如何协同?我们逐一拆解。
1. Logits-Guided Chunker
- 原理:借助LLM对上下文的强大理解能力,通过计算给定prompt下文本序列后出现[EOS]标记的概率,确定语义单元的边界。换言之,让模型自主判断:当前内容到何处才算结束。
- 实现:首先将输入文档转换为固定大小的块,随后计算每个句子后[EOS]的概率。概率最高的点即为断裂点——之前的文本作为一个独立块,剩余内容与下一个固定块拼接,循环迭代。
- 优势:相较于传统方法,这种方式能更好地捕捉上下文连贯性,生成的块语义集中、自成体系。
2. Multi-Granular Chunker
- 原理:借鉴Small2Big的思路——检索使用小块,但将查到的块所属的大块提供给LLM。
- 实现:先递归分块,生成较大的父块(如θ词大小),再递归细分为不同粒度的子块(如θ/2词和θ/4词)。推理时,通过子块(包括父块本身)的最大相似度分数确定父块得分,最终将得分最高的k个父块喂给LLM。
- 优势:根据查询需求灵活调整粒度,检索与合成更具弹性。
3. LGMGC:合二为一
整合:首先借助Logits-Guided Chunker生成θ大小的父块,再进一步细分为不同粒度的子块。这样既保证了语义连贯性,又兼顾了粒度灵活性。
效果:实验表明,LGMGC在文档检索和下游问答任务中均优于主流方法。
论文实验
1. 检索性能评估
数据集:GutenQA,专为“针堆里找针”设计的问答基准,数据来源为叙事类书籍。
评估指标:DCG@k和Recall@k。
结果处理:因原始证据可能由LLM合成生成,导致匹配率偏低,因此进行了重新标记——对每个证据,计算其与每个块的ROUGE分数,选取最高分的块作为相关块。
2. 下游QA任务性能评估
数据集:LongBench中的三个单文档QA数据集——NarrativeQA、QasperQA、MultifieldQA。这些任务侧重信息提取,不需要复杂推理。
评估指标:F1分数,计算公式基于预测答案与真实答案的词袋模型。
此处F1的计算思路为:假设预测答案的词袋为BOW(pred),真实答案的词袋为BOW(gt),精确率precision = |BOW(pred) ∩ BOW(gt)| / |BOW(pred)|,召回率recall = |BOW(pred) ∩ BOW(gt)| / |BOW(gt)|,则F1 = 2 × precision × recall / (precision + recall)。
3. 基线比较
基线方法:包括Recursive Chunker、Semantic Chunker、Paragraph-Level Chunker、LumberChunker。同时加入Multi-Granular Chunker和Logits-Guided Chunker进行消融研究。
模型与实现细节:采用8位量化的Llama3-8b实现Logits-Guided Chunker和LGMGC。所有策略均在块大小θ(200、300、500词)下评估,以观察对超参数的敏感性。
4. 结果
检索任务:Logits-Guided Chunker在所有块大小下均显著优于Recursive Chunker、Semantic Chunker和Paragraph-Level Chunker,充分证明其在捕获上下文连贯性方面的优势。而LGMGC在兼顾连贯性与粒度后,取得了最佳结果。
下游QA任务:LGMGC在三个数据集上使用最优块大小时均获得最高性能,证明其在下游任务中比现有基线方法更加可靠。
这些实验数据清晰表明:LGMGC在检索和下游QA任务中均有效,并且具备在更广泛场景中应用的潜力。
论文结语
论文总结了LGMGC的优势,同时展望了未来方向:例如设计更合理的自动评估指标、探索多语言与跨领域应用、提升计算效率与可扩展性、进一步优化语义理解与上下文建模等。