今天圈内最炸裂的消息,莫过于 DeepSeek-R1 的正式发布。如果说 2024 年是大模型推理能力竞赛的元年,那 DeepSeek 这次交出的答卷,无疑是国内最接近 OpenAI o1 正式版水准的成果。先说几个关键信息点:完整开源模型权重、API 开放思维链输出、许可协议大调整,甚至在蒸馏小模型上直接对标了 o1-mini。
这次发布的核心不只是技术指标的对比,更是一次对开源生态的诚意释放。以往模型开源往往留一手,但 DeepSeek 把 660B 参数的 R1 和 R1-Zero 全部放出,且遵循 MIT License。这个动作意味着什么?意味着你不仅可以直接商用,还可以基于 R1 的输出蒸馏训练自己的模型。在行业普遍收索开源范围的当下,这种开放姿态相当稀缺。
性能对齐 OpenAI o1 正式版
DeepSeek-R1 的后训练策略很有意思。他们在仅有极少标注数据的情况下,大规模引入强化学习,把模型的推理能力推到了新高度。数学、代码、自然语言推理这些硬核任务上,实测结果与 OpenAI o1 正式版不相上下。这也从侧面印证了强化学习在推理链条生成中的巨大潜力——不是单纯堆数据量,而是优化推理路径本身。
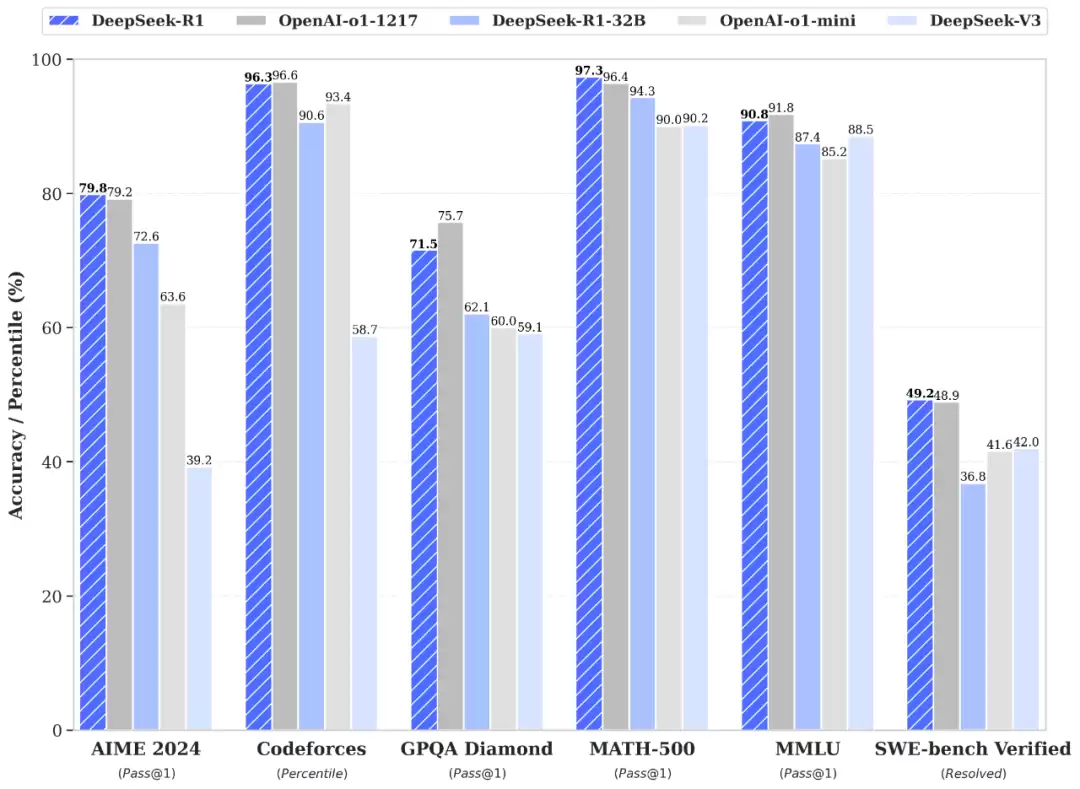
更厚道的是,R1 的完整训练技术细节全部公开。技术社区可以直接参考这份论文,尝试复现或改进。这种透明度对于推动行业进步至关重要——毕竟闭门造车永远比不上众人拾柴。
蒸馏小模型超越 OpenAI o1-mini
除了 660B 的大模型,DeepSeek 还利用 R1 的输出蒸馏了 6 个小模型。其中 32B 和 70B 的版本在多项能力上直接对标 o1-mini。要知道,o1-mini 本身就是针对轻量级推理优化的模型,而 DeepSeek 借助蒸馏技术,让小模型也获得了不弱的推理能力。这对于资源有限的开发者和中小企业来说,无疑是个好消息——不需要昂贵的硬件也能跑出接近顶尖的效果。
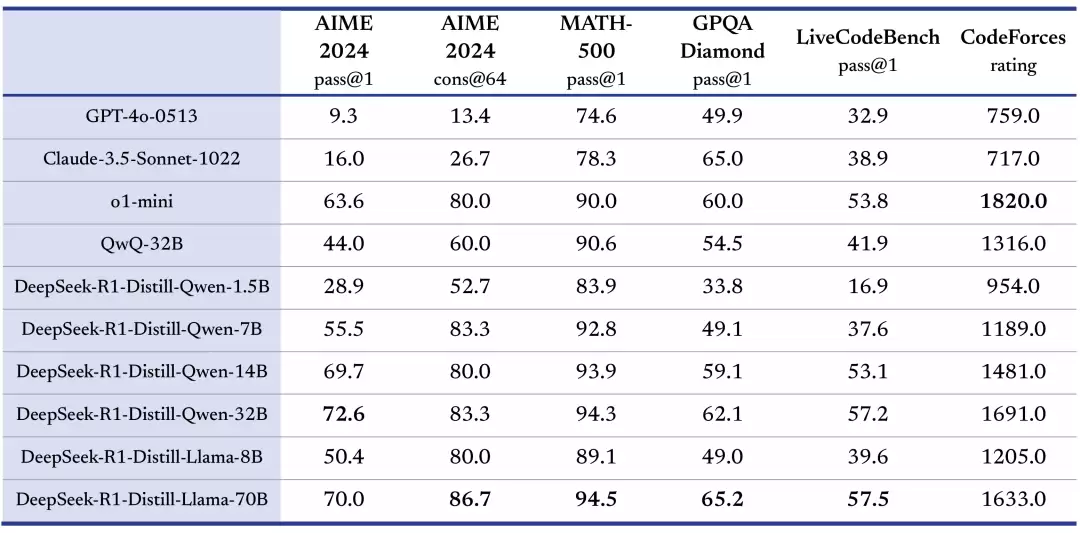
开放的许可证和用户协议
这一发布措施在开源社区中的反响最为积极。他们果断放弃了之前自定义的 DeepSeek License,统一改用 MIT。实践已经证明,非标准的开源许可反而增加了开发者的理解成本和合规风险。标准化的 MIT 意味着:完全开源、不限制商用、无需申请,任何人都可以放心使用。
更值得关注的是用户协议的调整。明确允许用户利用模型输出进行“模型蒸馏”,从而训练其他模型。这一条直接回应了社区长期以来的需求——此前很多开源模型协议上含糊其辞,导致蒸馏行为处于灰色地带。现在书面化、清晰化,对于生态建设是实质性利好。
App 与网页端
用户体验层面的调整也很直接。登录官网或官方 App,打开“深度思考”模式,即可调用最新版 R1。对于日常用户来说,不需要理解技术细节,只要一个按钮就能体验顶尖推理能力。
API 及定价
定价方面同样务实:每百万输入 tokens 缓存命中仅 1 元,未命中 4 元;每百万输出 tokens 16 元。对比同期同类模型的定价,这个价格在大模型推理领域相当有竞争力,尤其是缓存命中的价格几乎可以用“低廉”来形容。对于高频调用的商业场景,成本优势会非常突出。
总体来看,DeepSeek-R1 这次发布是“模型和协议双双放开”的操作,在国内大模型行业中确实罕见。性能对标、开源彻底、协议宽松,这三者的组合在行业里目前没有第二家。至于后续生态如何发展,蒸馏小模型能否真正普及,值得持续观察。