RAG“一周出Demo,半年难上线”的根源:问题分级才是关键
许多接触过RAG的产品经理和工程师都曾感叹:“搭建一个RAG演示系统只需一周时间,但要将其打磨到能稳定上线投产,半年都不一定够用。”这句话精准点中了当前RAG在企业落地中最现实的痛点。
RAG的架构看似简洁明了,市面上也出现了不少优化全流程的方法。然而,无论在企业内部部署还是面向C端用户,人们最直观的感受往往是:RAG似乎只能应对那些比较浅显的直接提问。全球知名的企业知识库独角兽Hebbia曾做过一项实验,结果显示RAG实际上仅能解决企业内部大约16%的问题。那么,剩下的84%究竟卡在了哪里?
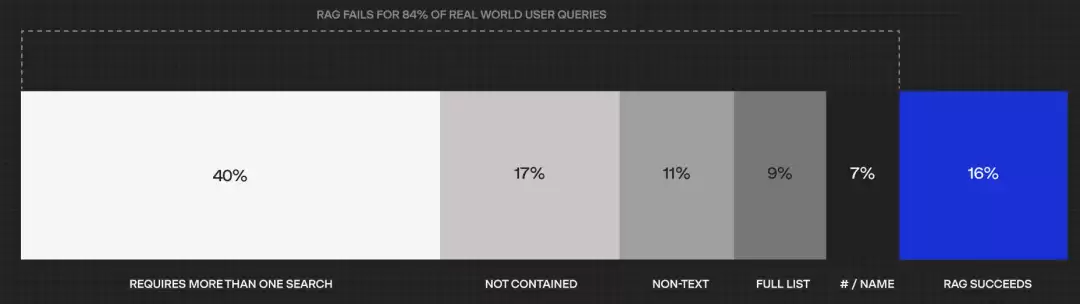
答案就在于对问题层级的划分。任何用户的检索请求,都可以归为四个层次:显性事实查询、隐性事实查询、可解释性推理查询和隐性推理查询。问题的复杂程度和求解难度依次递增。
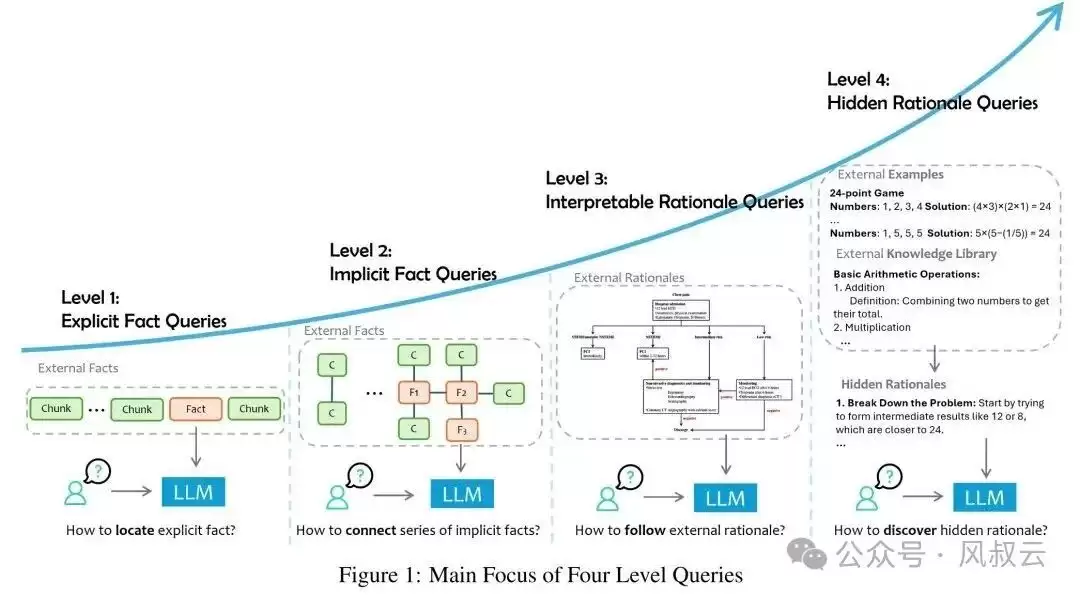
上图清晰列出了每类问题所面临的挑战以及相应的解决思路。不难看出,只有显性事实查询和部分隐性事实查询,可以通过RAG、迭代式RAG或图RAG来解决。而一旦触及可解释性推理和隐性推理这两个层次,传统RAG就显得力不从心,必须依靠更复杂、更有针对性的方案。在企业实际应用中,业务部门真正关心且有价值的问题,绝大多数恰恰集中在Level 3和Level 4。这就很好地解释了为什么“RAG一周出Demo,半年上不了线”会成为一种普遍现象。
接下来,我们逐一拆解这四类问题的特点与应对策略。
显性事实查询
显性事实查询是最基础的一类,指的是那些在数据源中明摆着的事实,不需要任何额外推理。比如“2016年奥运会在哪里举办的?”“某传感器的品牌和工作温度是多少?”“门店A上个月的营业额是多少?”这类查询就像查字典一样,直接从给定数据中提取明确信息即可。因此,它非常适合用RAG来处理。
当然,要想做到准确高效,对RAG系统的优化必不可少。这里简要回顾几个关键环节:
索引构建方面,可以从以下几个方向入手:
块优化:通过滑动窗口、增加元数据、从小到大等策略,让内容块的大小和结构更合理。
多级索引:创建两层索引,一层是文档摘要,另一层是文档块。先通过摘要过滤出相关文档,再在小组内精确搜索。
知识图谱:提取实体及其关系,构建全局信息优势,提升检索精度。
预检索阶段,也有不少技巧:
多查询:借助提示工程,把原始Query扩展成多个相似的Query,并行检索。
子查询:将复杂问题拆解成多个子问题,逐一处理后汇总。
查询转换:把用户的自然语言查询转换成另一种形式,再检索。
查询构建:将自然语言转为机器能理解的语言,比如text2SQL、text2Cypher。
检索器选择上,主要有两类:
稀疏检索器:统计方法生成稀疏向量,处理大数据集时效率高。
密集检索器:利用预训练语言模型生成密集向量,语义表示更强,但计算成本也更高。
此外,还可以通过检索器微调,基于领域数据精细调整模型。
检索后处理同样重要:
重排序:用专门的排序模型重新计算上下文的相关性得分。
压缩:剔除无关内容,突出关键信息,减少冗余干扰。
隐性事实查询
隐性事实没那么直接,需要一点推理和逻辑判断。并且推导它所需的信息可能分散在多个段落或数据表里,需要跨文档或跨表检索。比如“查询过去一个月营收增长率最高的门店”,就得先拿到所有门店两个月的营收,计算增长率,再排序。
这类问题的主要挑战在于:不同问题依赖的数据源和推理逻辑千差万别,大模型的泛化性很难保障。应对思路包括:
多跳检索和推理:
迭代式RAG:在检索前先制定计划,过程中根据结果不断调整。比如用ReAct框架,沿着“思考—行动—观察”的路径逼近答案。
自省式RAG:构建四个评分器(检索需求、检索相关性、生成相关性、回答质量),让模型自主决定何时检索、何时借助外部工具、何时输出答案。
利用图和树结构:
Raptor:根据向量递归地对文本块聚类,生成摘要,自下而上构建知识树。不同层级的摘要有助于回答不同层面的问题。
图RAG:将知识图谱与RAG结合,从图数据库中检索关联知识,而非传统的向量库。
自然语言转查询:
text2SQL:尤其适合多表查询场景,将自然语言问题直接转化为SQL语句。
可解释性推理查询
这类问题无法从显性或隐性事实中直接获取,需要综合多方数据进行复杂的推理、归纳和总结,并且推理过程必须可解释。ChatBI中的归因分析就是典型例子,比如“过去一个月,华南区域营收下滑5%的原因是什么?”
这个问题没法直接回答,但可以依据业务逻辑来推理。总营收 = 新客 × 转化率 × 客单价 + 老客 × 复购率 × 客单价。如果新客数、转化率、客单价都没变,只有老客复购率下滑了约10%,那么原因很可能出在服务质量或竞品竞争上。
可解释性推理面临两个主要挑战:一是多样化的提示词,不同问题需要不同的业务规则;二是有限的可解释性,提示词对模型的影响不透明,难以保证一致性。应对策略包括:
提示词工程优化:
优化提示词:把业务推理逻辑有效整合到大模型中,比较考验设计者的行业知识。
提示词微调:通过强化学习等技术,让模型在不同数据集上自动发现最佳提示词配置。
构建决策树或状态机:
将决策流程转换为状态机、决策树或伪代码,让模型按步骤执行。比如设备运维领域的故障树,就是一种有效的检测方案。
利用智能体工作流:
通过工作流约束模型的思考和行动步骤,保证输出的稳定性。缺点是灵活性不足,需要为每类问题专门设计。
隐性推理查询
这是最难的一类问题。它无法通过事先约定的规则或逻辑来判断,必须从外部数据中观察、分析,最终推理出结论。比如IT智能运维,没有现成的故障处理手册,只有历史事件和解决方案记录。大模型需要从这些数据中挖掘出最佳处理方案。
产线智能运维、智能量化交易等场景,都充满了这类问题。它的主要挑战是逻辑提炼极其困难,而且数据往往分散且不足。仅靠语义相似性远远不够,需要构建专门的小模型。解题思路有:
机器学习:通过传统方法从历史数据中总结潜在规则。
上下文学习:在提示中提供示例,引导模型推理,但模型能否掌握超出训练领域的推理能力是个问题。
模型微调:用大量业务数据微调模型,内化领域知识,但资源消耗巨大。
强化学习:通过奖励机制,鼓励模型产出最符合业务实际的推理逻辑和答案。
总结
本文的核心,是回应“RAG上手容易上线难”这个普遍困惑。我们将用户的问题划分成四类,并指明了每一类问题的应对方向。
显性事实查询和隐性事实查询,确实可以通过各种RAG优化方案来解决。但一旦遇到可解释性推理和隐性推理问题,单纯依赖RAG就会力不从心。这时,就需要引入提示词工程、决策树、智能体工作流、机器学习、模型微调、强化学习等一系列更进阶的方法。
这里每一个方法单独拿出来都足以写成一个系列。本文只是先画出一张路线图,后续有机会再结合实际案例做更详细的拆解。