视觉语言模型(VLM)正深刻改变着人类与图像、视频及语言的交互模式。本文将深入剖析这一前沿技术,重点介绍其中的明星模型——Qwen2-VL-72B-Instruct,探讨它如何助力开发者开创多模态智能应用的新篇章。
什么是视觉语言模型(VLM)?
简单来说,视觉语言模型(VLM)是一种融合大语言模型与视觉编码器的多模态人工智能系统——其核心是为大语言模型赋予“视觉”能力。它不仅可以处理文本输入、执行高级推理并生成自然语言输出,还能理解并分析提示中包含的图像信息。
与YOLO、DeepLab等传统视觉模型不同,VLM不再受限于固定类别或特定任务(如分类、检测)。通过在海量图文配对数据上进行预训练,VLM将视觉编码器与大语言模型深度融合,能够理解自然语言指令,并泛化至几乎所有的视觉任务类型。
VLM的核心技术优势主要体现在以下几方面:
- 多模态输入:同时接受图像和文本输入,理解两者间的语义关联。
- 共享表征空间:通过预训练将视觉与语言特征对齐到统一表征空间,实现无缝跨模态交互。
- 生成与推理:既能根据图像生成描述,也能依据指令产出视觉内容。
凭借这些能力,VLM已成为理解和生成多模态内容的关键工具,正推动人工智能在多模态场景中的广泛落地。目前,VLM已在多个实际场景中得到应用:
- 图像识别理解:不仅能识别植物、地标等物体,还能理解场景中多个对象之间的复杂关系。

- 视觉推理:通过分析图像解决问题,如解读复杂数学题或图表,甚至能正确处理极端长宽比的图片。视觉感知与逻辑推理的结合,使模型能够充当日常生活中的智能助手。
视频理解与实时对话:能够提炼视频核心内容、实时回答相关问题,并保持对话的连贯性,为用户提供更直观、更及时的帮助。
实时视频对话
Visual Agent 能力:部分VLM已初步具备利用视觉能力自动完成工具调用与交互的能力。
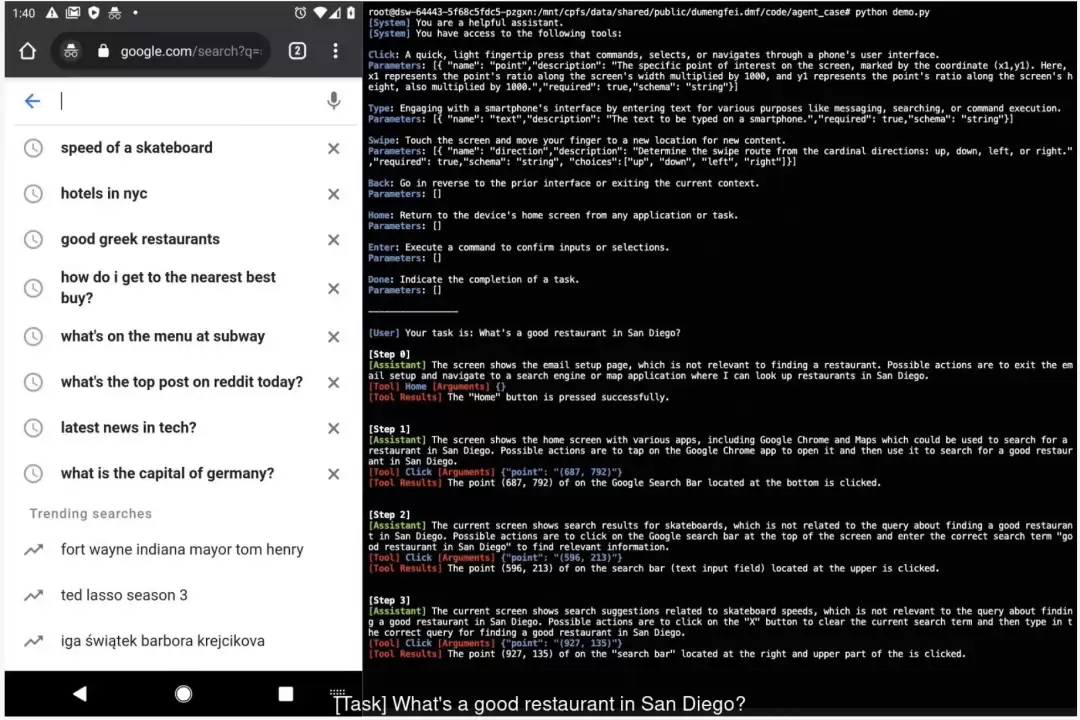
上述应用案例均源自千问大模型家族的视觉语言模型——Qwen2-VL-72B-Instruct。
Qwen2-VL-72B 性能有多强?
Qwen2-VL-72B-Instruct 是一款拥有720亿参数的超大视觉语言模型,其在业界的表现令人瞩目。
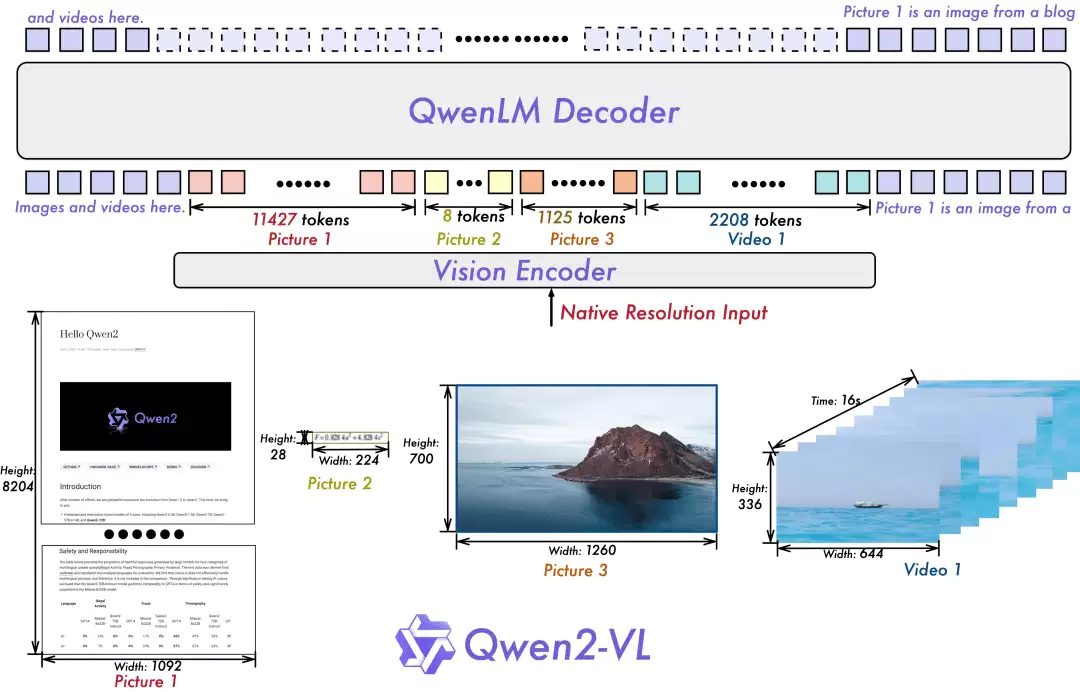
性能表现与评测
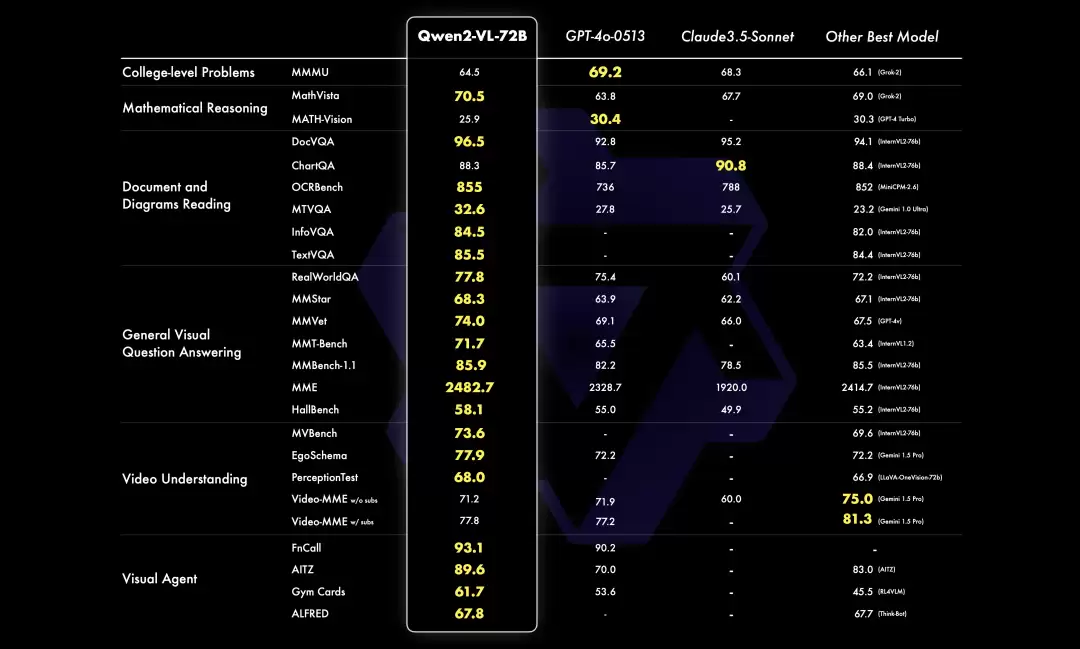
在综合大学题目、数学能力、文档表格多语言理解、通用问答、视频理解及Agent能力等六个维度上,Qwen2-VL-72B在大部分指标上均达到最优水平,甚至超越了GPT-4o和Claude3.5-Sonnet等闭源模型,尤其在文档理解领域优势显著。仅在与GPT-4o的综合大学题目对比中尚有差距。同时,它创下了开源多模态模型的最佳纪录。
如何轻松调用顶级 VLM?
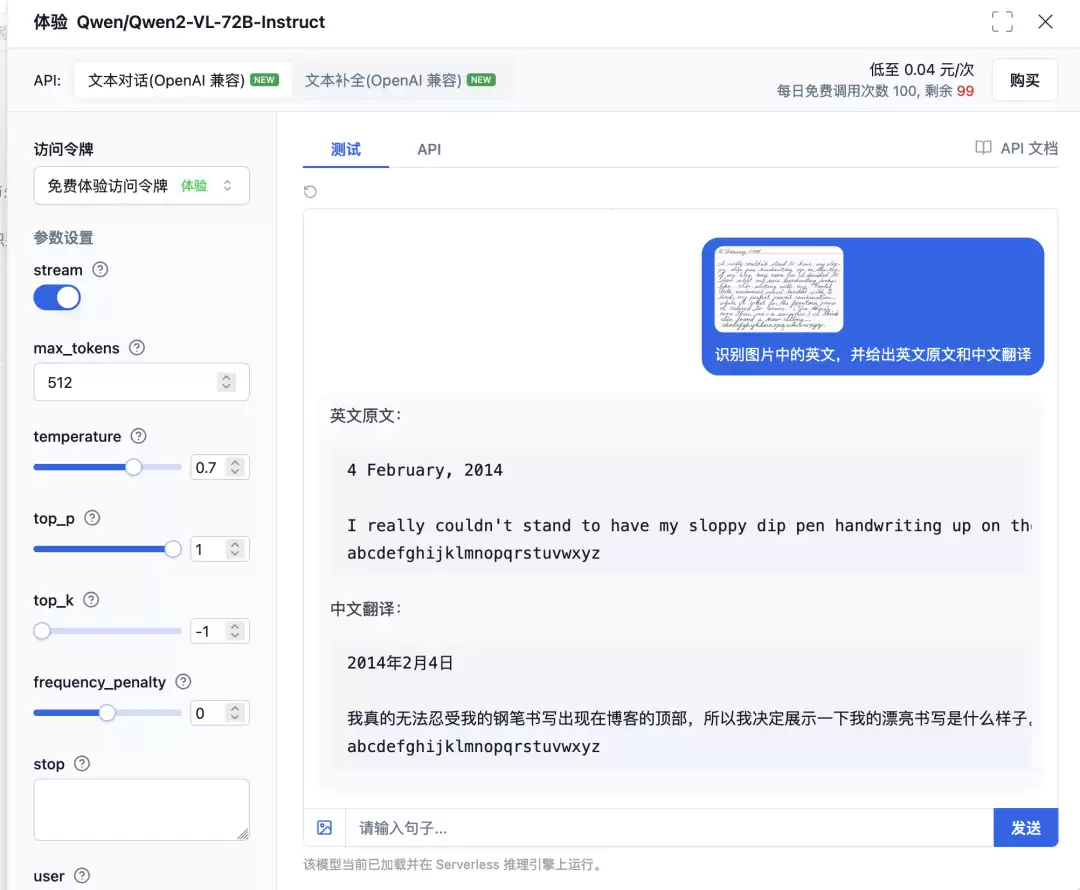
如此庞大的开源模型,本地部署并非易事——至少需要80GB以上的显存,还需配置各类框架、驱动与优化工具,加载和推理性能也是一大挑战。然而,Qwen2-VL-72B-Instruct现已集成Serverless API,开发者无需自建基础设施,即可通过API直接调用这个720亿参数的‘巨兽’。
通过 Serverless API 体验手写文本识别

<<< 左右滑动查看更多 >>>
视觉语言模型正为人工智能开启全新的想象空间,而Qwen2-VL-72B-Instruct的强大能力,无疑是开发者手中一把锋利的利器。