先快速梳理一下核心逻辑。检索增强生成(RAG)近年来确实备受关注,它有效解决了一个现实问题:让大语言模型(LLM)在生成内容时,能够从外部知识库中查阅资料,再将检索到的信息反馈给模型,从而提升回答的可靠性,避免凭空编造。然而,随着实际应用的深入,问题也逐渐浮现——实时检索操作导致延迟上升;文档选择不当会使答案偏离方向;整个系统架构日趋复杂,效率与准确率都难以保障。
最近一篇题为《Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks》的论文提出了一个新范式:缓存增强生成(CAG)。这一思路与RAG截然不同——CAG不依赖运行时的实时检索,而是提前将知识“喂”给模型,将计算完成的缓存存储起来,当用户提问时直接调用这些缓存。这样一来,效率显著提升,为知识密集型任务开辟了一条更加轻量的新路径。
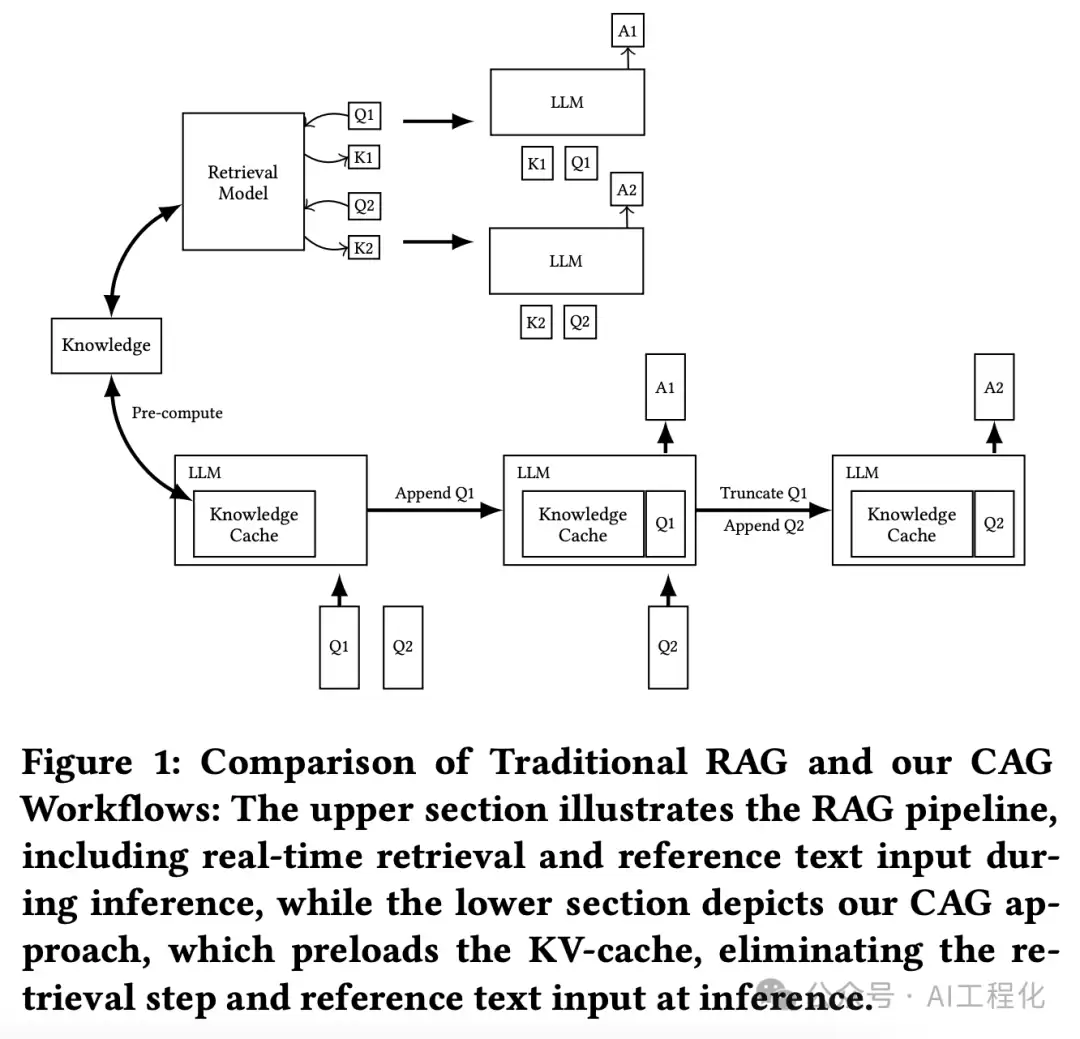
基本原理
CAG的核心理念可以概括为四个字:“提前准备”。它不需要在回答问题时临时查阅资料,而是事先将所有相关文档加载至LLM的上下文内存中,并预先计算好键值缓存(Key-Value Cache)。如此一来,当用户提问时,LLM可直接利用缓存中的已有知识,省去耗时检索的步骤。具体实施分为以下三步:
- 知识预加载——首先将目标领域内的所有文档进行整理和格式化,确保LLM能够理解。随后对这些文档进行编码,生成对应的键值缓存,并存储下来备用。
- 缓存上下文推理——用户提问时,直接将预加载的键值缓存与问题一并输入给LLM。模型无需再访问外部检索系统,仅凭缓存的上下文即可生成答案。
- 缓存高效管理——缓存并非一成不变,可根据需要定期更新或重置,以防止知识老化影响回答质量。
CAG的优势与不足
相较于传统RAG系统,缓存增强生成(CAG)在多个方面展现出明显吸引力:
- 速度显著提升——省去实时检索环节后,推理速度大幅加快。实测中,某些场景下CAG甚至比RAG快数十倍,这意味着用户无需长时间等待,体验得到明显改善。
- 准确性更高——由于所有相关知识均已提前加载,LLM能够从全局角度理解信息,避免因碎片化内容产生理解偏差。例如,在HotPotQA数据集上,CAG的BERT-Score达到0.7759,显著领先于RAG系统,表明其生成的回答更加精确且连贯。
- 架构更为简洁——CAG的系统结构相对简单,减少了大量复杂组件,维护更加省力,开发和运营成本也随之降低。
- 性能表现优异——在众多知识密集型任务中,CAG的表现不逊于RAG,甚至在某些维度上更胜一筹。尤其当任务需要深度理解上下文信息时,CAG的优势更加突出。例如在SQuAD数据集上,多个测试维度中CAG均超越了传统RAG系统。
当然,任何技术都有其适用边界。CAG的核心局限性在于,它要求将所有相关知识均加载到LLM的上下文窗口内。换言之,它更适合文档集合规模可控的场景。如果知识库庞大且频繁更新,则仍需依赖传统RAG系统来应对。
不过,随着模型上下文窗口的不断扩展,CAG的适用边界也在持续拓宽。未来或许会出现RAG与CAG混合的方案,各自发挥优势,以适应更复杂多样的应用场景。
小结
RAG的诞生是为了弥补LLM在能力上的不足;而CAG则是随着LLM自身能力的提升自然进化而来的产物。在特定条件下,通过预加载和预计算替代实时检索,能够大幅提升知识密集型任务的执行效率。这也反映了LLM应用开发的一项基本原则:凡是模型自身能够完成的工作,应尽量交由模型处理,充分发挥其内在能力。当然,也无需像论文标题那样极端——二者并非相互替代,而是针对不同场景的权衡选择。