在 VLX-Flow 之后,Om AI 又把 VLX 系列往前推了一步——这次,模型终于能把实时画面里的目标看准了。
3B 参数的小模型,能在细粒度感知上打赢 Gemini 3.1 Pro 吗?
答案是 VLX-Seek,它补的就是这层能力。在 Om AI 联汇发布的 VLX 端侧流式多模态模型系列里,VLX-Seek 负责的是精准定位。说白了,VLM 能看懂画面但常常“看个大概”,传统小模型能框准位置却理解不了复杂语义——VLX-Seek 刚好卡在这个缝隙里。

从坐标生成到区域指代

继 VLX-Flow 之后,Om AI 把 VLX 系列推进到第二层能力:让模型在实时视觉场景中看准目标。
图片问答里,模型说“画面里有人”“桌上有杯子”,已经算完成了理解。但任务一旦变成跟随、巡检、预警或导航,问题就瞬间变得具体起来:
画面里如果有多个人,到底该跟着哪一个?桌上好几个杯子,用户指的是哪个?目标被遮挡的时候,边界还能不能稳得住?
更狠的是,用户给出的可能不是一个简单类别名,而是一段复杂描述——比如“左边第二个穿黑色衣服的人”,模型能不能理解这段描述,并准确落到画面里的具体目标上?
放到实际结果上看,VLX-Seek-3B 在 MSCOCO val2017 上拿到了 45.3 mAP,超过了 Gemini 3.1 Pro 的 41.4;在更考验实例感知的 PixMo Count 上达到 85.0,同样领先 Gemini 2.5 Pro 的 73.8。3B 小模型能在这些任务上领先,关键在于定位任务的表达方式变了。
传统做法是把坐标数值直接交给语言模型去生成,但 VLX-Seek 换了一条路:先把画面中的物理实体转成可被语言模型读取、引用和推理的 region token,然后让模型在候选区域之间比较、选择和指代。


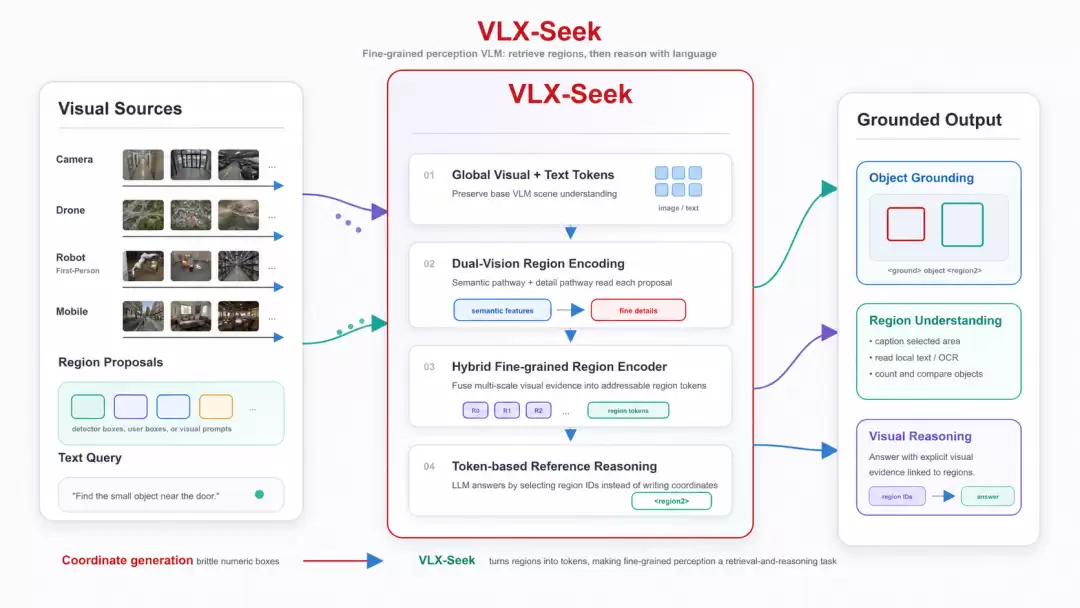
〓VLX-Seek 整体架构
当用户问“穿红衣服的人在哪里”时,模型判断哪个区域 token 最符合描述,并输出对应的区域索引。定位任务由此变成了在候选视觉区域中做语言条件检索。
这把定位问题放回了语言模型更擅长的比较、选择和指代。候选区域提前变成 token 后,模型面对的是一组可比较的视觉候选,而不是一串待续写的数值。
实际推理时,OPN 先召回可能包含前景目标的候选区域。这一步不判断类别,只提供视觉候选;OPN 与 VLM 主体解耦,候选区域既可以来自 OPN 或其他检测器,也可以来自用户框选区域、人工指定的感兴趣区域,或者 visual prompt。
拿到候选区域后,VLX-Seek 使用 HFRE 从候选框中提取区域级视觉特征,并将这些特征投影到 LLM 的嵌入空间。候选框原本只是几何范围,能标出“这里有一个区域”,却无法说明区域里是什么、和其他区域有什么区别、是否符合用户描述。经过这一步,区域有了可供模型比较和判断的视觉表示。
到了语言模型侧,用户的自然语言描述会和这些区域表示一起参与推理,模型通过区域索引完成定位和回答。后续的目标定位和区域推理,也都围绕这套表示展开。


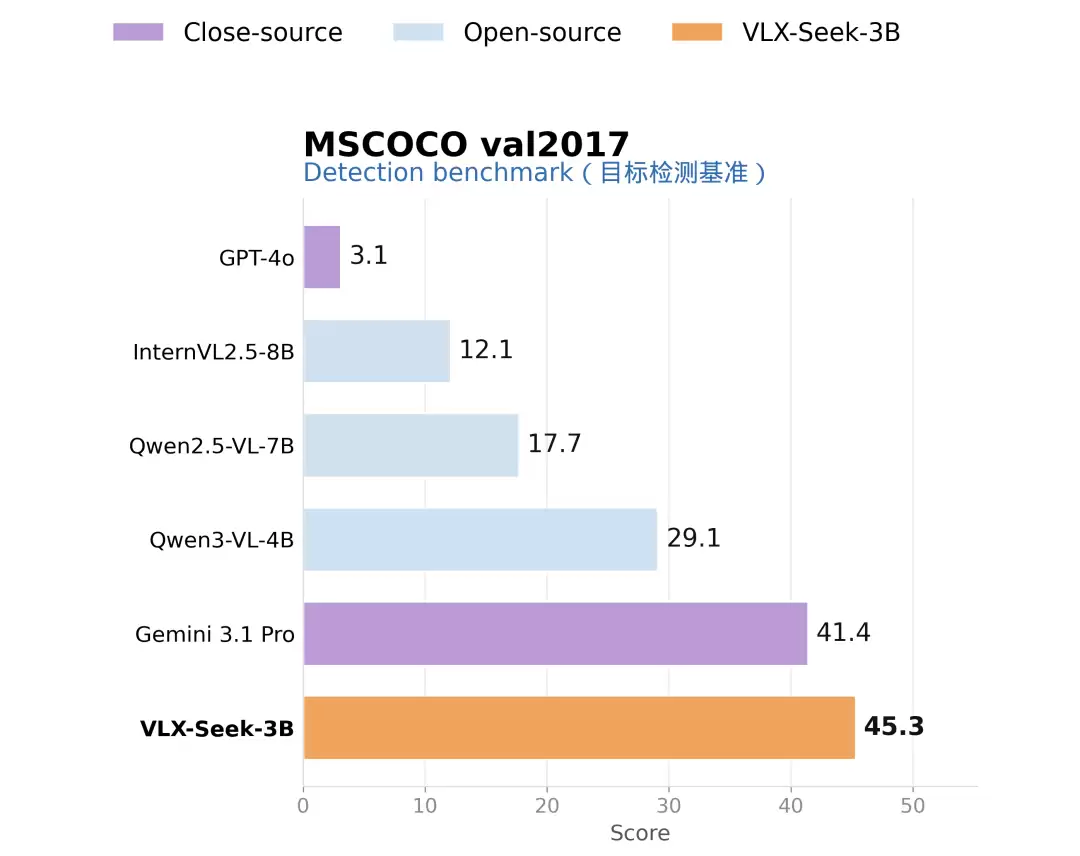
〓MSCOCO val2017 通用目标检测对比结果
换到开放词汇检测,难点变成开放类别、复杂语言标签和难负样本。VLX-Seek-3B 在 OVDEval 上达到 43.7;在 ODinW13 中,VLX-Seek 拿到 48.4,超过 Qwen3.5-397B-A17B 的 47.0 和 Gemini 3 Pro 的 46.3。
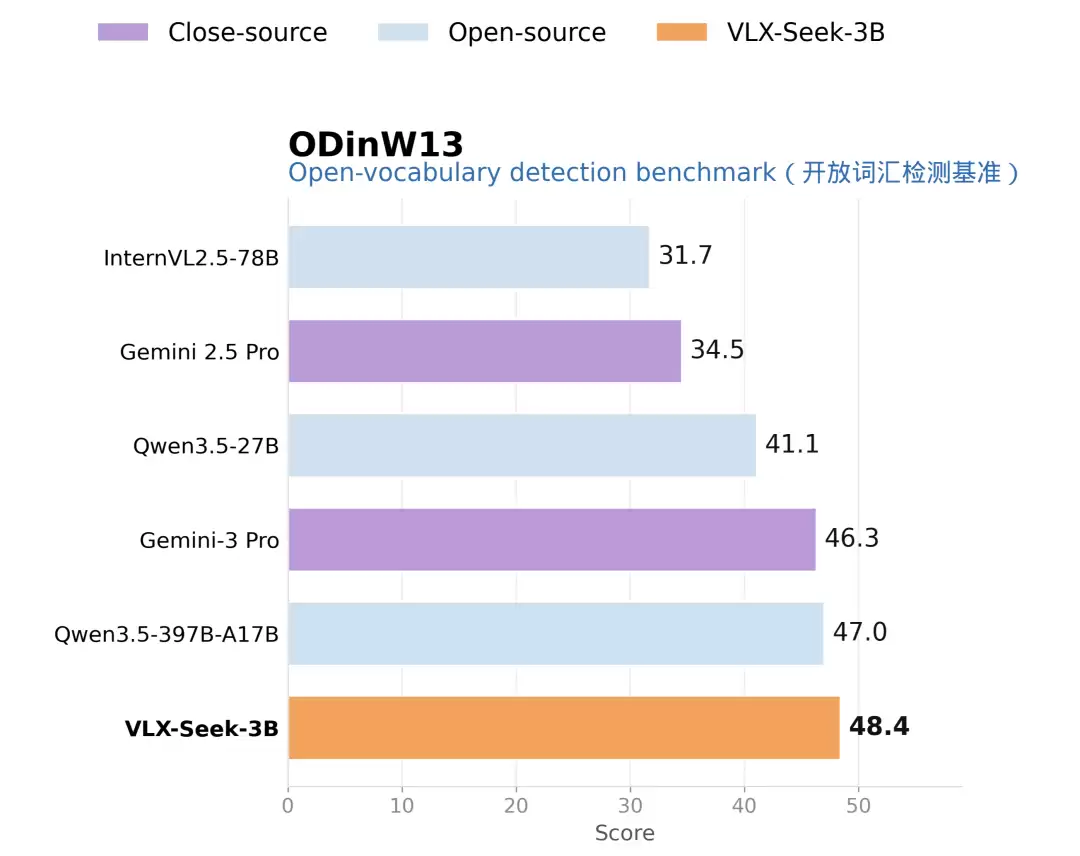
〓ODinW13 开放词汇检测横向对比结果
RefCOCO 系列进一步考验自然语言指代,例如“左边第二个穿黑色衣服的人”“靠近桌子的杯子”“被另一个物体遮住一部分的目标”。VLX-Seek-3B 在 RefCOCO/+/g A verage 中达到 88.7,略高于 Qwen3-VL-8B 和 InternVL3-9B 的 88.2,也领先 Gemini 3 Pro 的 84.1。
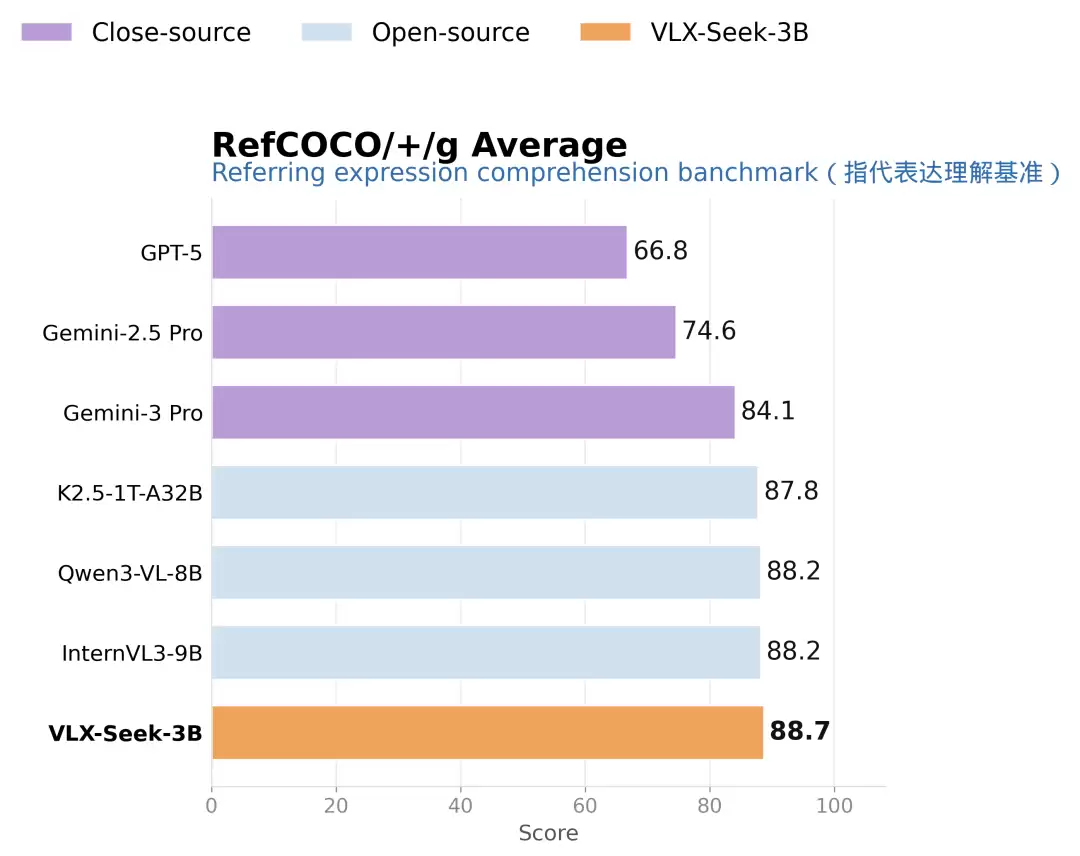
〓RefCOCO 系列指代表达理解平均结果
PixMo Count 则把问题推到实例级计数。VLX-Seek-3B 在该任务上达到 85.0,领先 Gemini 2.5 Pro 的 73.8,也明显高于 Qwen3-VL-8B 的 65.0。计数任务看似简单,但 VLM 如果只依赖全局语义,很容易估多或估少。VLX-Seek 可以先检测并引用目标实例,再做聚合计数,比直接凭画面印象估数量更可靠。
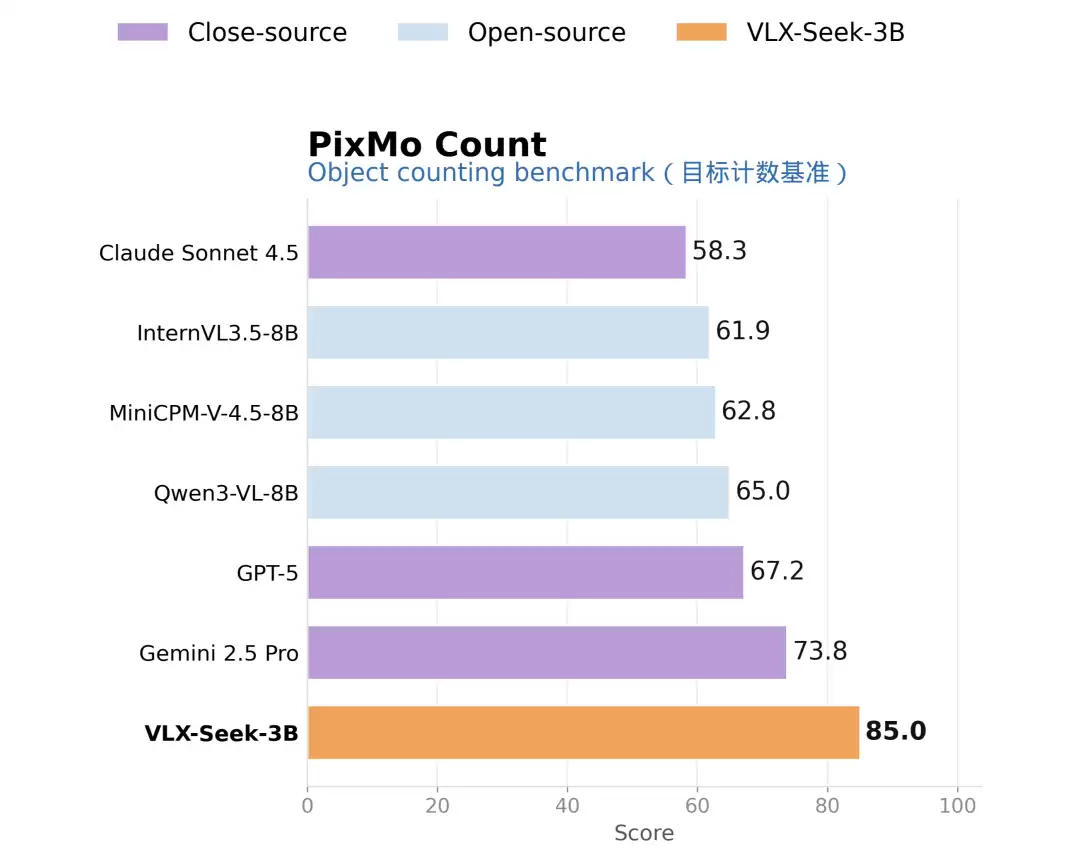
〓PixMo Count 目标计数任务对比结果
在检测、开放词汇定位、复杂指代表达和计数等任务上,VLX-Seek-3B 已经展现出小参数模型的竞争力。区域 token 与区域引用机制,是这组结果背后的关键设计。

