被CVPR 2026收录!复旦大学邱锡鹏团队(OpenMOSS)提出了一项富有创意的研究思路——Thinking with Video。其核心理念十分直观:利用视频生成模型,将视频帧作为统一媒介进行多模态推理,旨在打破视觉与文本之间的壁垒。

此前广为流行的Thinking with Text(基于文本的链式推理)和Thinking with Images(在链式推理中加入图像辅助)显著提升了大型语言模型和视觉语言模型的推理能力。然而,这两种范式存在难以回避的局限性:静态图像无法捕捉动态过程,文本与视觉模态各自独立,难以真正实现理解与生成的统一。Thinking with Video的切入点是——让视频生成模型“绘制”推理过程,使模型能够像人类一样进行绘制、想象和模拟。
实验结果极具冲击力:在视觉任务上,视频生成模型不仅整体能与顶尖视觉语言模型相抗衡,甚至还能解决MATH、MMMU等文本推理任务。这一方向比近期谷歌Gemini Omni曝光的“黑板推公式”更早做出了预判。
目前该工作已在社交平台X上引发关注,数据和代码均已开源。
Thinking with Video:视频生成作为多模态推理新范式
从Thinking with Text到Thinking with Images,核心缺陷主要集中于两点:
- 静态约束:图像只能记录单一时刻,难以表达动态过程、时间变化与连续变换。
- 模态分离:文本与视觉各自为政,缺乏一个能够自然融合两者的推理载体。
研究团队注意到,视频生成模型天生具备绘制、模拟与想象能力,非常适合视觉推理。同时,视频帧中可以嵌入文本,理论上也能胜任文本推理。因此,Thinking with Video天然具备多模态推理的基础。团队沿着这一思路进行了系统性探索。
VideoThinkBench:综合的视频生成推理测试基准
为了全面评估视频生成模型的推理能力,团队构建了VideoThinkBench,共包含4149个测试样本,分为视觉任务与文本任务两大类(图1)。
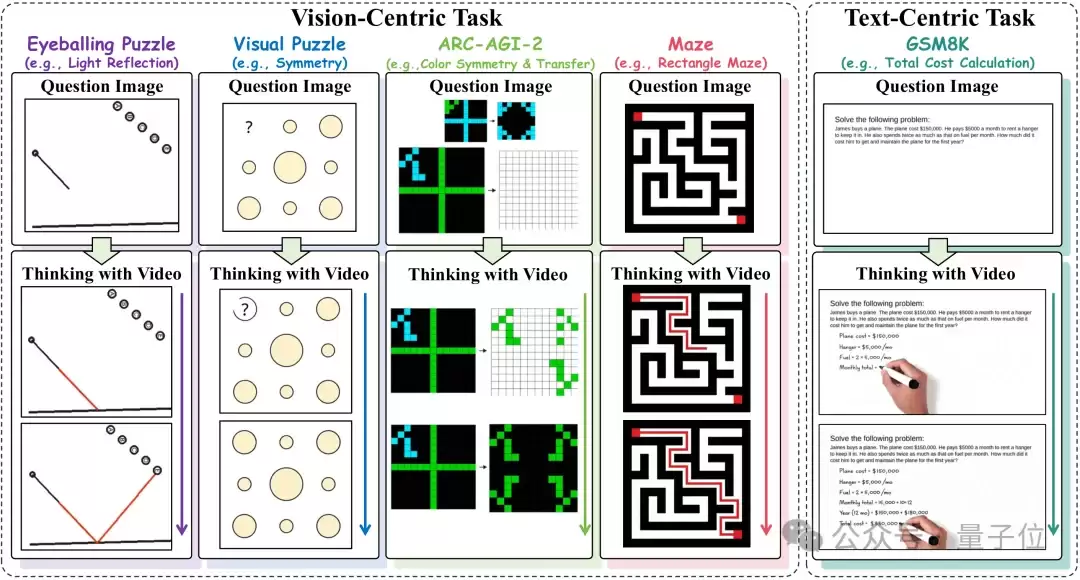
△图1:VideoThinkBench的任务分类与Thinking with Video过程示意
视觉任务涵盖几何直觉、视觉模式归纳、抽象规则归纳、空间规划与搜索,包括Eyeballing Puzzles、Visual Puzzles、ARC-AGI-2和Mazes。所有视觉任务样本均通过程序自动生成,答案可验证,便于精准评测。
文本任务改编自现有基准(如MATH、MMLU、MathVista、MMMU),涵盖纯文本与多模态的数学推理及通用推理。
团队在VideoThinkBench上评测了视频生成模型(如Sora-2、Veo 3.1),并与三个顶级视觉语言模型(Gemini 2.5 Pro、GPT-5 high、Claude Sonnet 4.5)进行了对比,结果令人振奋。
核心发现一:Thinking with Video使模型匹敌甚至超越顶尖视觉语言模型
视频生成模型在视觉任务上表现卓越,整体水平可与顶尖视觉语言模型相媲美(表1)。
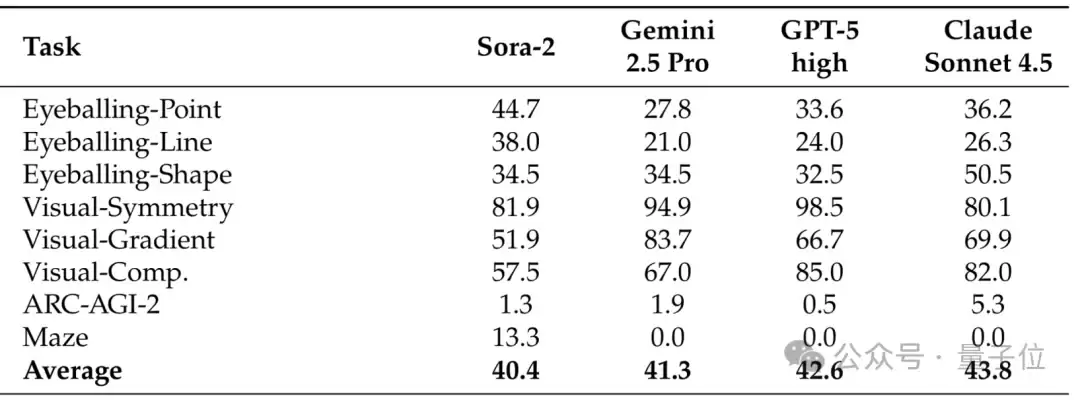
△表1:视觉任务性能对比,Sora-2可与三个顶尖视觉语言模型匹敌
Thinking with Video能够处理几何直觉推理、视觉归纳推理,甚至挑战高难度的ARC-AGI-2任务。
Eyeballing Puzzles:画图模拟,几何推理超越顶尖视觉语言模型

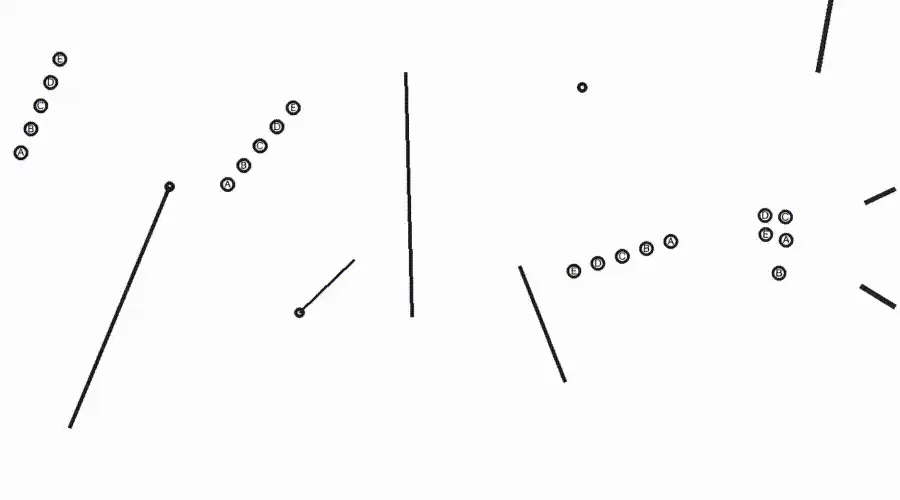
△图2:Eyeballing Puzzles任务的输入输出示例
Eyeballing Puzzles(目测谜题)分为Point、Line、Shape三种类型(图2)。实验显示,Sora-2能够在视频中模拟光线的延伸与反射,操作几何元素(点和线)辅助推理(图3)。
△图3:Sora-2生成视频解决Eyeballing Puzzles,最终将答案选项标红,并在语音中输出结果
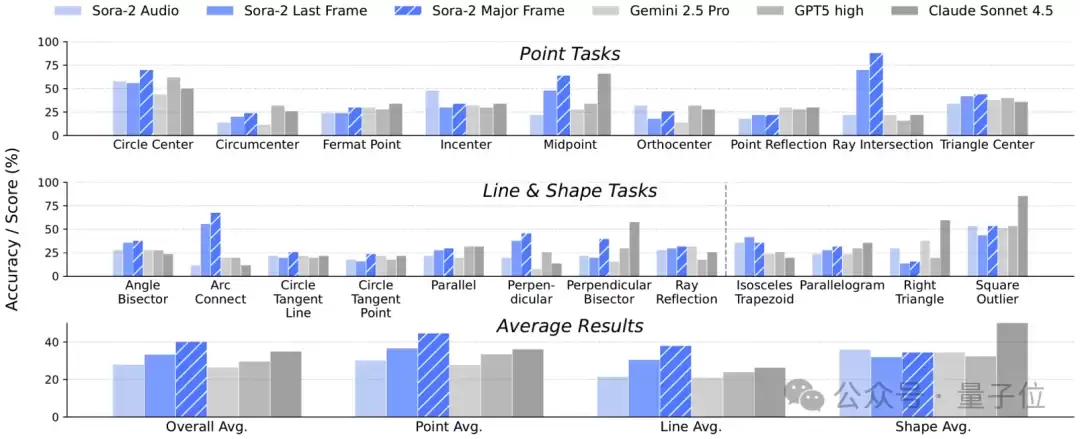
△图4:各模型在Eyeballing Puzzles上的性能
在多帧投票评估下(利用整个视频过程,避免最后一帧噪声),Sora-2的总体表现击败了三个顶尖视觉语言模型(图4),充分展示了Thinking with Video在画图模拟方面的独特优势。
Visual Puzzles:视频生成能够完成归纳推理
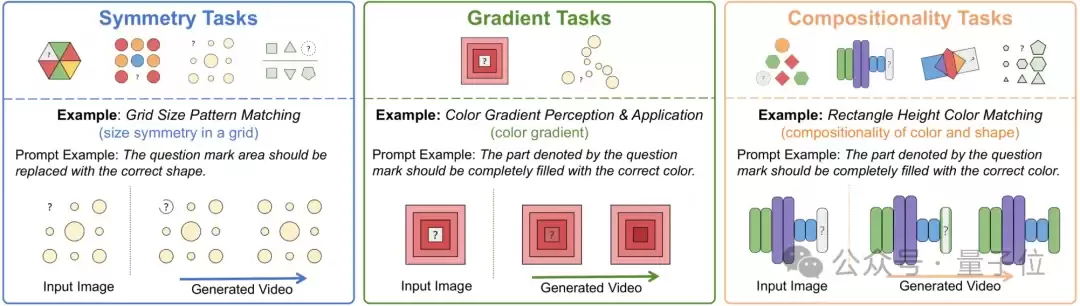
△图5:Visual Puzzles任务的输入输出示例
Visual Puzzles考察模型根据颜色、形状、尺寸进行归纳推理(图5)。问题不提供选项,直接生成视频补全缺失的颜色或形状(图6)。
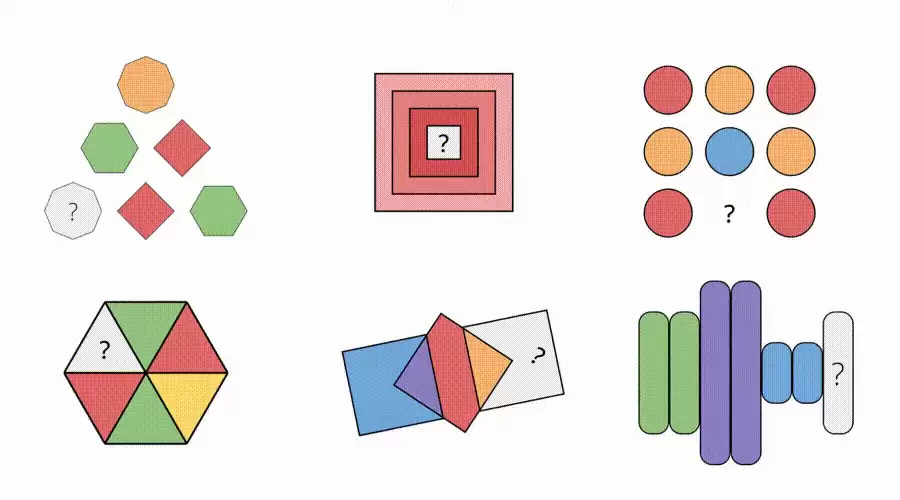
△图6:Sora-2生成视频解决多样化的Visual Puzzles
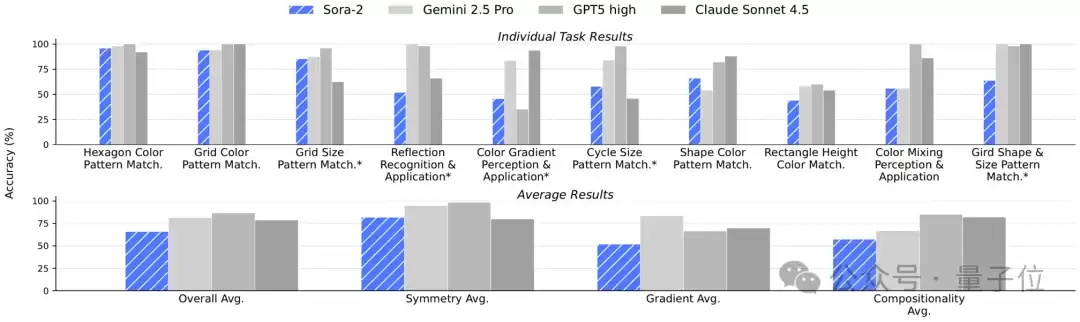
△图7:各模型在Visual Puzzles上的性能
Sora-2在这些视觉谜题上表现优异,并在对称任务(Symmetry)中击败了Claude Sonnet 4.5(图7)。可见视频生成模型不仅能画线模拟,还能从视觉结构中归纳并运用规律。
ARC-AGI-2:视频生成模型具备少样本学习能力
ARC-AGI-2面向更抽象的规则归纳能力,模型需观察若干输入-输出示例,推断视觉变换规则,再应用到新网格中。实验发现,Sora-2在这项更具挑战性的任务上也能依据示例做出正确预测(图8),展现出从示例中学习变换规则的能力。

△图8:以视频生成解决ARC-AGI-2题目

△表2:统一视觉输入下各模型在ARC-AGI-2上的表现
在相同的视觉输入形式下,顶尖视觉语言模型在ARC-AGI-2上表现欠佳,而Sora-2已能与之匹敌。这一结果说明视频生成模型同样可以成为少样本学习器。
进一步实验显示,增加示例数量还能提升视频生成模型的表现。
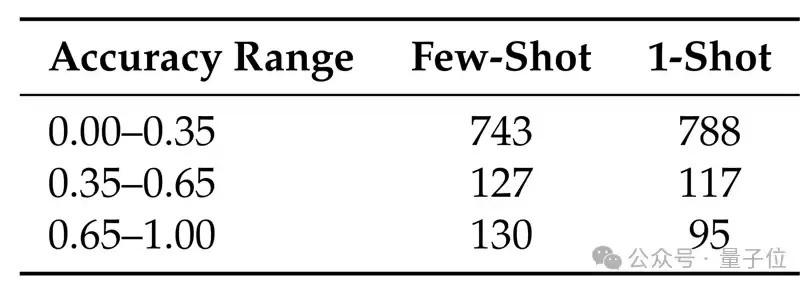
△表3:提供多个示例与单个示例下Sora-2的表现对比
相比只提供一个示例(1-Shot),提供更多示例(Few-Shot)后,更多测试样本达到了较高的像素级准确率,即更接近正确答案(表3)。这一发现意味着,视频生成模型的上下文学习能力值得进一步深入挖掘。
核心发现二:视频生成模型竟能进行文本推理
视频生成模型也能解决文本推理问题吗?这令人联想到不久前曝光的Gemini Omni——网友用它生成了一个在黑板上推导公式的视频,效果惊艳。

△图9:Gemini Omni生成的公式推导视频,来自@Chetasluah
值得注意的是,研究团队在此之前就已提出让视频生成模型解决文本推理任务,并进行了系统性评测。
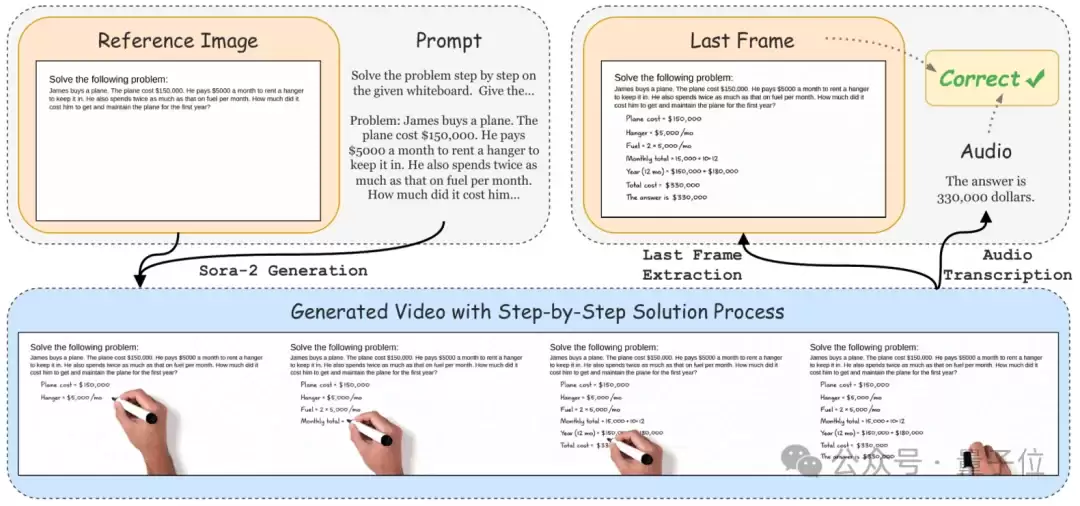
△图10:文本任务的输入输出及评测方式
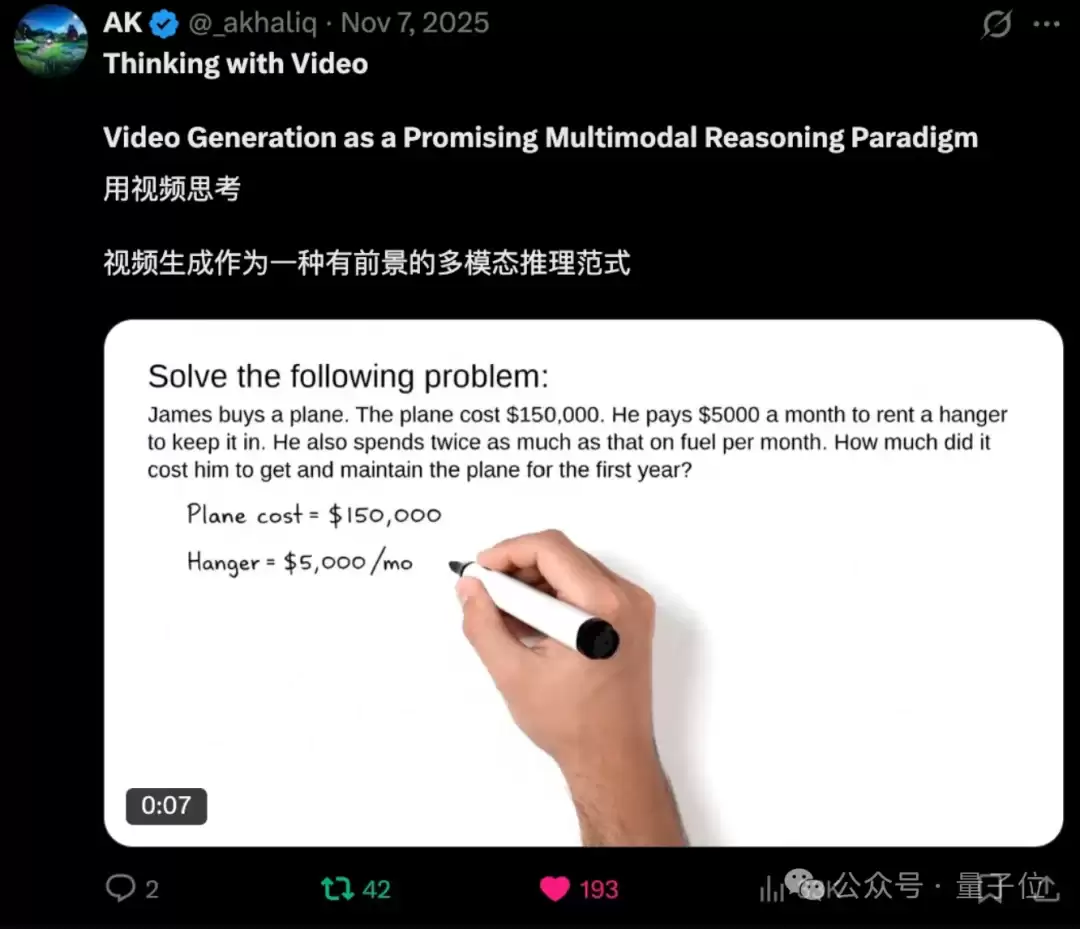
VideoThinkBench中的文本任务,输入由文本提示词和参考图像组成(图10)。问题既写在提示词中,也展示在参考图像里。模型需要生成一段视频,在视频中写出解题过程(图11),并通过语音说出最终答案。评测时,大模型基于标准答案,分别判断最后一帧和语音中的答案是否正确。

△图11:在视频生成中解决GSM8K题目
结果出人意料:如表4所示,Sora-2在多个文本测试集上表现亮眼,例如MATH准确率达92%,MMMU达69.2%。当然,在更难的文本任务上与顶尖视觉语言模型仍有明显差距。但这一结果证明,视频生成模型通过在视频帧中嵌入文本来进行文本推理的路径是可行的。
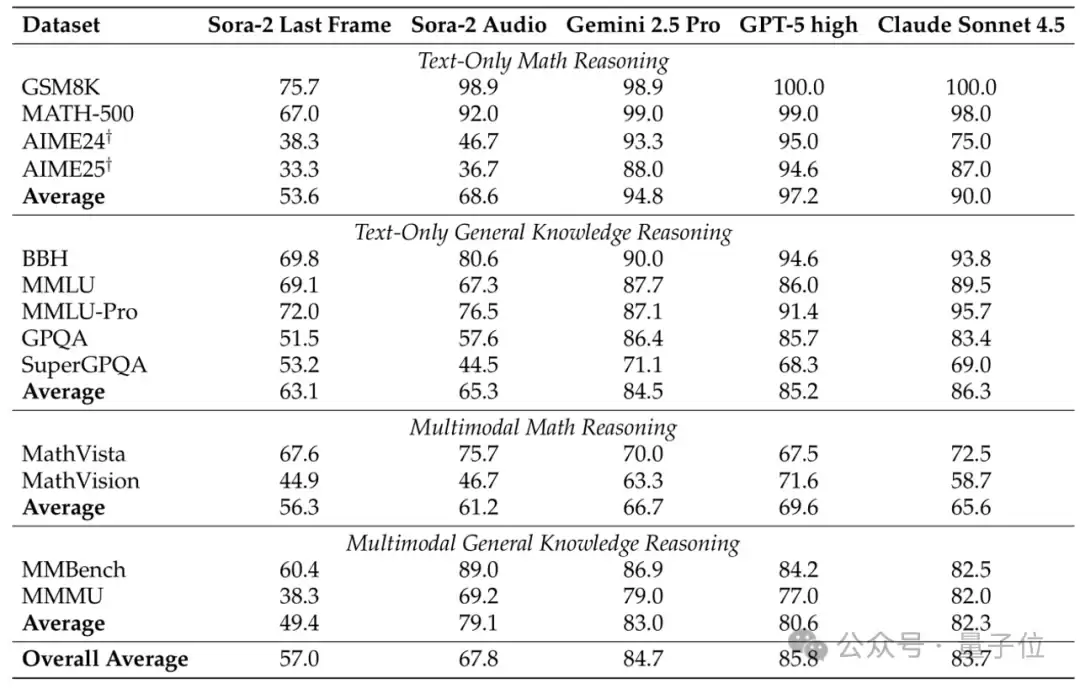
△表4:文本任务评测结果
团队还专门分析了文本任务表现是否来自测试集泄露。通过改编测试数据(GSM8K与MATH),修改问题中的数值和表述重新测试,结果Sora-2的表现并未下降(表5)。说明能力并非来自记忆,而是真正具有潜力。
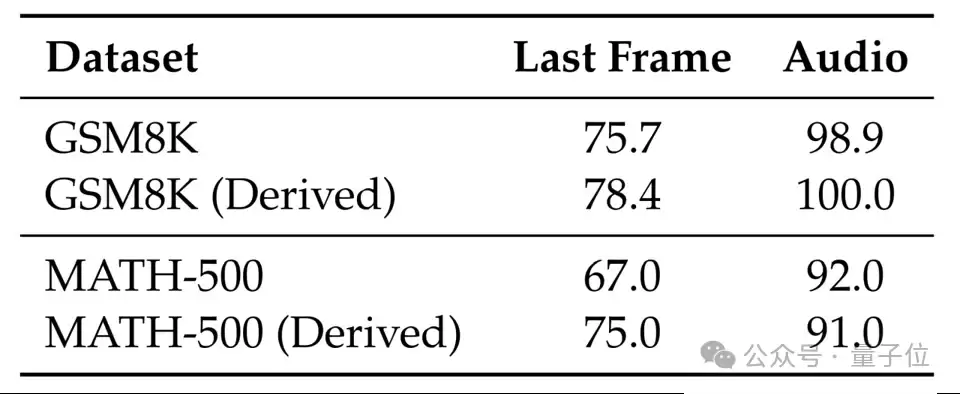
△表5:在原始与改编文本题目上的表现
当然,人工案例分析也暴露了问题——视频中的书写过程未必可靠。如图12所示,仅有13.91%的解答视频中文本过程完全正确,将近一半的过程无法阅读或存在错误。模型能给出正确答案,但难以生成清晰、稳定且完全正确的推理步骤。

△图12:对Sora-2文本作答过程的分析
研究还分析了视频生成模型的文本能力是否可能来自前置的提示词改写模型。Wan 2.5的API可控制是否允许改写提示词,关闭提示词改写后,Wan 2.5在文本任务上的表现几乎降为零(表6)。这表明,如果存在提示词改写模块,它可能在最终视频生成前就已经解出了文本题目。
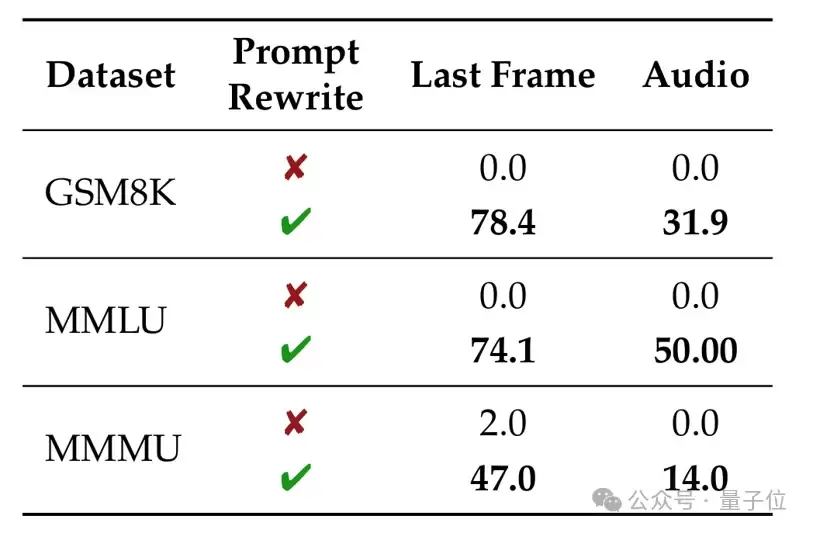
△表6:Wan 2.5在有无提示词改写下的表现
视频生成推理的测试时扩展可能成为新的研究前沿
在大语言模型推理中,经典的测试时扩展方法如Self-Consistency通过多次采样和多数投票提升准确率。团队发现,Thinking with Video也有类似结论。
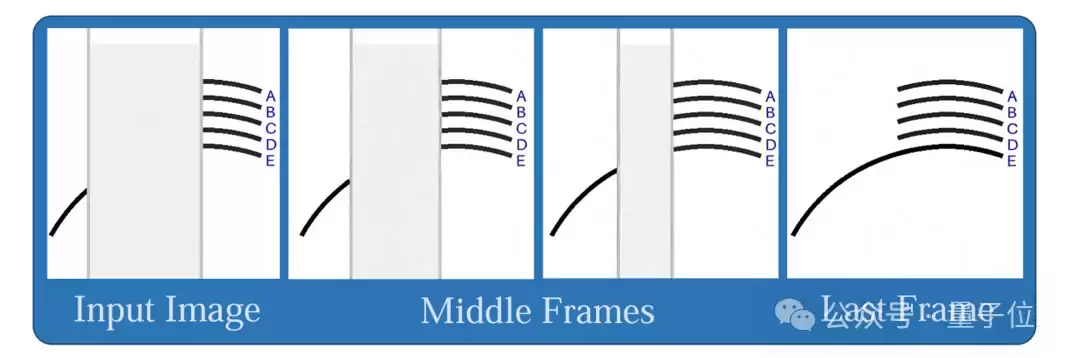
△图13:通过视频生成解决Arc Connect问题
在Eyeballing Puzzle的Arc Connect任务(图13)中,只看单次生成的最后一帧,准确率为56%;改用多帧多数投票后提升到68%。进一步让Sora-2生成5次视频并对结果投票,多帧多数投票准确率直接飙升至90%(表7)。

△表7:采样多个视频进行投票的结果
Self-consistency能够提升视频生成模型在视觉任务上的表现,这意味着视频生成模型的测试时扩展将成为新的研究前沿。
总结
这项研究首次提出了Thinking with Video这一多模态推理新范式——以视频生成模型为基础,将视频帧作为统一媒介进行多模态推理。在作者设计的VideoThinkBench上,视频生成模型展现出卓越的推理能力。借助绘画与想象的优势,Sora-2在视觉任务上可媲美顶尖视觉语言模型;此外还展现出通过书写文本来解决文本推理问题的潜力。更有趣的是,视频生成模型还能充当少样本学习器,而Self-consistency可以进一步提升推理性能。可以说,Thinking with Video为多模态推理开辟了全新的可能性。
论文链接:
https://arxiv.org/abs/2511.04570
项目网站:
https://thinking-with-video.github.io
代码仓库:
https://github.com/tongjingqi/Thinking-with-Video
数据集:
https://huggingface.co/datasets/OpenMOSS-Team/VideoThinkBench