大语言模型中的参数冗余并非浪费,而是在训练、推理、后训练等生命周期中扮演着四种截然不同的关键角色。本文将从“参数冗余谜题”出发,层层拆解这些看似“吃空饷”的参数背后的真实作用。

那条光滑的幂律曲线背后,从来没有什么免费的冗余。
为什么会有“参数冗余”的错觉?
自从 Jared Kaplan 等人在 2020 年画出那条幂律曲线,Scaling Law 就成了大模型时代最重要的经验法则。参数越大,模型越强,成了定理。
但在 2024 年,百川智能发表了一篇名为 ShortGPT 的论文。他们直接把 LLaMA-2-13B 的 40 层 Transformer 砍掉了 10 层。结果模型在 MMLU 上的得分却仅仅从 55.0 跌落到了 52.2。
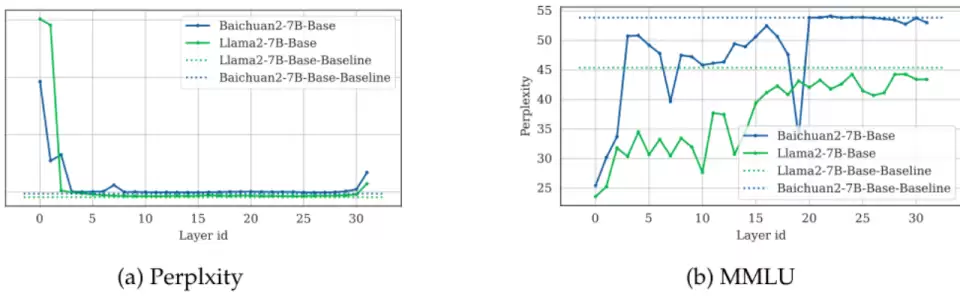
ShortGPT 删层实验,逐层移除后 PPL(左)与 MMLU(右)几乎不变,深层尤其稳(图源 Men et al. 2024, Fig.1)
四分之一的层没了,核心知识基准却几乎毫发无损。
随后,牛津大学在 2025 年发表的研究《大语言模型中的深度诅咒》(The Curse of Depth in Large Language Models)又重现了这个现象。他们发现,大模型深层网络里相邻层的输出几乎是完全同质化的,把这些层直接抽走,性能不仅没崩,甚至有时还会微微反弹。
这似乎说明,大模型里有大量的层都在「吃空饷」。
如果这些参数都在空转,Scaling Law 就变得很可疑了。我们是否真的有必要要这么多的参数?它们真的在给模型带来好处吗?
这就是 Scaling Law 的一个重要谜题,即参数冗余谜题。
过去两年,最顶尖的 AI 研究者们开始了一场向微观下潜的战役。试图从各个角度去破解这一谜题。在这一过程中,也将 Scaling Law 从「经验公式」升级为「物理定律」。
两年之后,这些孜孜不倦互相印证的研究,终于构成了一张网络,来部分解释了这些冗余参数的机理和作用。
如果把模型的一生拆开,将训练、推理、后训练(微调)这三段账分开来算,你会发现,这些被统称为「冗余」的参数,其实在不同阶段扮演着四种截然不同的角色。