在2025年6月12日至13日举办的第八届智源大会上,世界模型是全场最受瞩目的技术议题之一。汇聚了具身智能、机器人控制、游戏引擎、物理AI基础设施等领域的顶尖研究者,共同交流世界模型的技术路线与发展方向。其中,昆仑万维旗下Skywork首席科学家刘扬以《Matrix-Game:长时序记忆下的实时流式交互式世界模型》为题,深入讲解了Matrix-Game的研发历程与最新突破,并首次公开了Matrix-Game 3.5的核心技术细节。本教程将基于大会内容,为你系统拆解世界模型的定义、技术演进、数据构建与关键挑战。

一、重新定义世界模型:从“预测下一帧”到“状态-动作联合生成”
当前,全球世界模型赛道呈现出技术路线快速分化的格局。尽管路径各异,但一个共识正在浮现:世界模型已从纯学术命题,演变为机器人、仿真、游戏与通用AI底层能力的竞争核心。在国内,昆仑万维的Matrix-Game是该领域起步最早、系统化程度最高的技术力量之一。
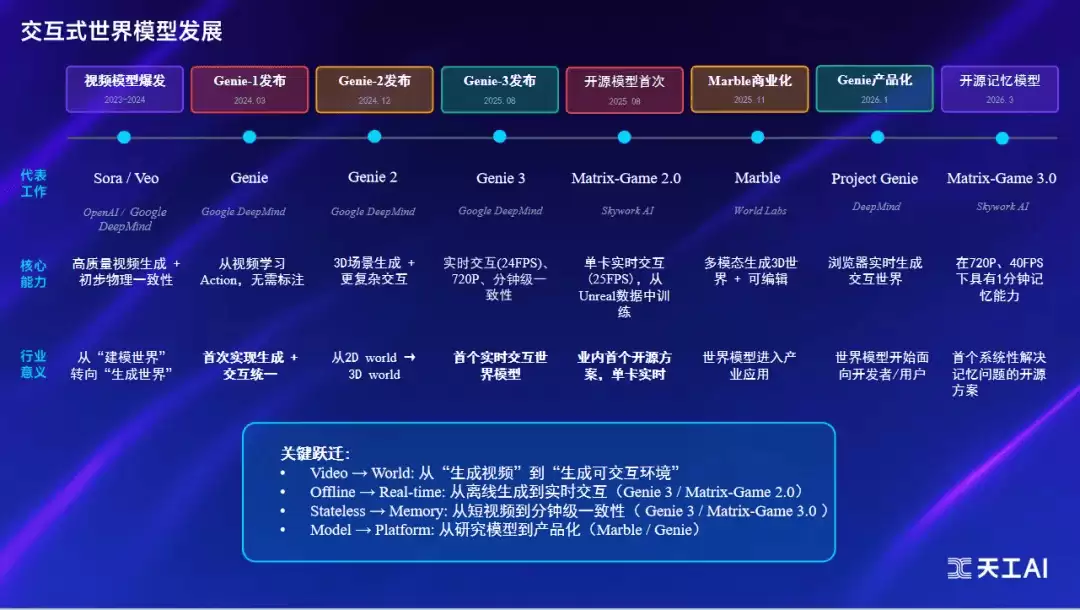
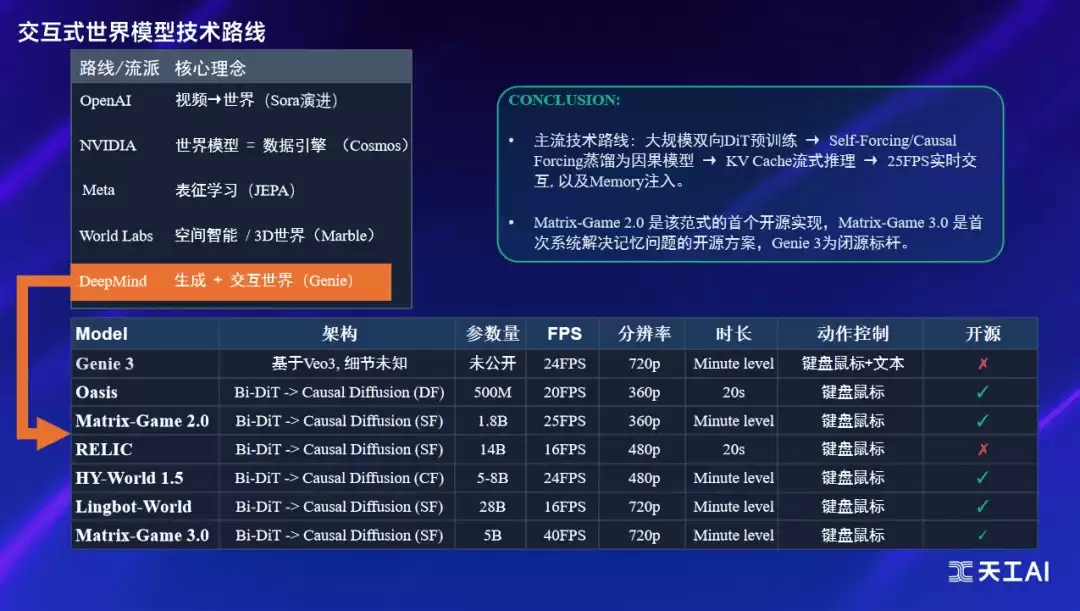
从技术落地上看,全球主流技术路线已逐渐清晰:先进行大规模双向DiT预训练,再通过Self-Forcing或Causal Forcing蒸馏为因果模型,配合KVCache实现流式推理,最终达到25FPS的实时交互水平,辅以记忆注入机制解决长时程一致性问题。
Matrix-Game 2.0正是这一技术范式中首个开源的实现方案,而Matrix-Game 3.0则首次系统性地将记忆问题纳入开源解决方案。目前,Skywork的Matrix团队正全力推进从3.0到3.5的升级,核心目标在于攻克长时序生成中的记忆瓶颈,并实现5B参数模型在720P分辨率下的实时生成能力。
基于长期研究,刘扬指出,“世界模型”一词在业内的定义混乱程度远超普遍认知——视频生成、3D表征、交互式模拟器等不同方向的研究者所指并非同一对象。

1.1 刘扬提出的世界模型理解框架
他在演讲中提出了自己的理解框架,包含三个核心层次:
- 理解当下状态:这超越纯视觉信息。一个真正的世界模型需要理解物体级别的物理属性——墙是否可穿越、水的温度等。纯视觉信号天然无法覆盖这些信息。
- 预测下一个状态:在充分理解当前状态的基础上,模型需对世界的后续演化做出推断。
- 将预测结果渲染呈现:使开发者和用户能够观测“下一帧”。
1.2 关键突破:状态与动作的联合训练
然而,团队的思考并未停留于此。Matrix-Game的实际训练揭示了一个更关键的结论:状态的预测与动作的生成应当联合训练,而非分而治之。
当我们把下一帧状态的生成和动作的生成进行联合训练,发现无论对状态理解还是对状态和动作的预测,都会带来显著的提升。
这意味着他眼中更完整的世界模型,是对状态与动作的联合理解与联合生成——而非单向的观测世界、预测下一帧。根据具体应用场景,模型可以侧重输出状态(用于交互模拟器)或侧重输出动作(用于机器人控制)。这一统一框架,是Skywork团队对世界模型认知的核心升级。