扩散模型这些年在AI圈有多火,已经不用多说了。从Stable Diffusion到Sora,再到各种图像编辑、三维生成和分子设计工具,它几乎成了现代生成模型的标配。它的思路很直观:先把真实数据一步步加噪,直到变成一团“噪声”;然后训练一个神经网络,学习如何逆向操作,把这团噪声“去噪”成全新的、有意义的样本。
但这里藏着一个非常尖锐的理论问题:高维分布,真的能被有限的样本学好么?
一张256x256的彩色图片,展开就是一个接近20万维的向量。按照传统统计学习的理论,要在这个维度上学会任意一个分布,需要的样本量会随着维度指数级增长。这就是著名的“维度灾难”(curse of dimensionality)。
如果这个最坏情况理论直接套在扩散模型头上,那它早就在真实任务里“翻车”了。可现实恰恰相反,扩散模型不仅生成质量高,还能创造出训练集里没有、但语义一致的全新内容。
这就引出了一个核心问题:为什么扩散模型能逃过这一劫?
最近,一篇理论论文给出了一个非常漂亮的解释:扩散模型之所以能泛化,很可能是因为真实世界的数据本身,就长在一个低维结构里。
01 为什么这篇论文值得关注?
简单来说,这篇论文把“扩散模型为什么有效”这个经验问题,升维到了一个更底层的框架里:它试图从数学上证明,扩散模型的训练过程、泛化能力,乃至可控生成,本质上都是在做同一件事——学习数据的低维结构。
这不再是“看现象”式的解释,而是试图回答“为什么”和“在什么条件下能行”。
02 核心观点:高维只是表象,低维才是本质
这篇文章最核心的思想,是区分两个维度:
| 概念 | 含义 | 对学习难度的影响 |
|---|---|---|
| 环境维度 | 数据被包装出来的表面维度,比如图像的像素个数。 | 看起来很吓人,往往很高。 |
| 内在维度 | 数据真正变化所需的最少自由度。 | 可能远低于环境维度,这才是关键。 |
自然图像虽然存在于高维像素空间里,但它们不是“随机乱飘”的。真实图像受限于物体形状、光照、纹理、语义类别等无数约束。这意味着,图像数据虽然“躺”在高维空间里,但实际上可能只集中在某个低维流形或低维子空间附近。
这彻底改变了问题的性质。扩散模型看起来是在学高维分布,但它真正需要学的,可能只是数据实际占据的那个“低维小世界”。
基于这个洞察,论文引入了一个精巧的数学模型:MoLRG(Mixture of Low-Rank Gaussians,低秩高斯混合模型)。
03 MoLRG:一个便于理论分析的“显微镜”
MoLRG可以看作是“低维结构化数据分布”的一个简化模型。传统的高斯混合模型假设每个成分都有完整的协方差矩阵,数据可以在所有方向上变化。而MoLRG假设每个高斯成分的协方差矩阵是“低秩”的。
换句话说,每个高斯成分并不占据整个高维空间,而是主要分布在一个低维子空间里。用更直观的话讲,每个低维子空间可以代表一类局部数据模式,比如不同的物体类别、姿态或纹理。
MoLRG的优势在于,它同时满足了两个要求:
- 贴近现实: 它符合“真实数据在低维流形附近”的直觉。
- 便于分析: 高斯模型数学性质好,特别适合推导出score function(得分函数)和去噪目标这类核心概念。
它不是一个完美的数据模型,而是一台理论“显微镜”,帮我们看清扩散模型学习低维结构的底层机制。

04 扩散模型训练到底在学什么?
要理解这篇论文,得先抓住扩散模型训练的“灵魂”:score function。它告诉我们,在某个噪声水平下,样本应该往哪个方向“修一修”,才能更像真实数据。
但直接学score function不容易。论文借助Tweedie’s formula,把它跟另一个概念——后验均值——联系了起来。也就是说,去噪网络其实是在学:给定一个带噪样本,它最可能对应的原始干净样本是什么。
从“去噪自编码器”的视角看,扩散模型的训练不只是“学会去噪”,而是在学习数据分布的结构:哪些方向是数据真正变化的方向,哪些方向只是噪声。
这正是低秩结构大显身手的地方。如果真实数据集中在某些低维子空间里,那么最优去噪器要做的,就是把那些偏离子空间的分量“按”回去,把噪声去掉。这就是整篇论文最核心的理论直觉来源。
05 理论结果一:单个低秩高斯 → 等价于 PCA
作者先从最简单的情况开刀:所有数据都来自同一个低维子空间。这时问题变成了:扩散模型能恢复出这个子空间吗?
论文证明,在合适的网络参数化下,扩散模型的训练目标等价于一个经典的主成分分析(PCA)问题。PCA的目标就是找到数据方差最大的方向,也就是恢复主低维子空间。
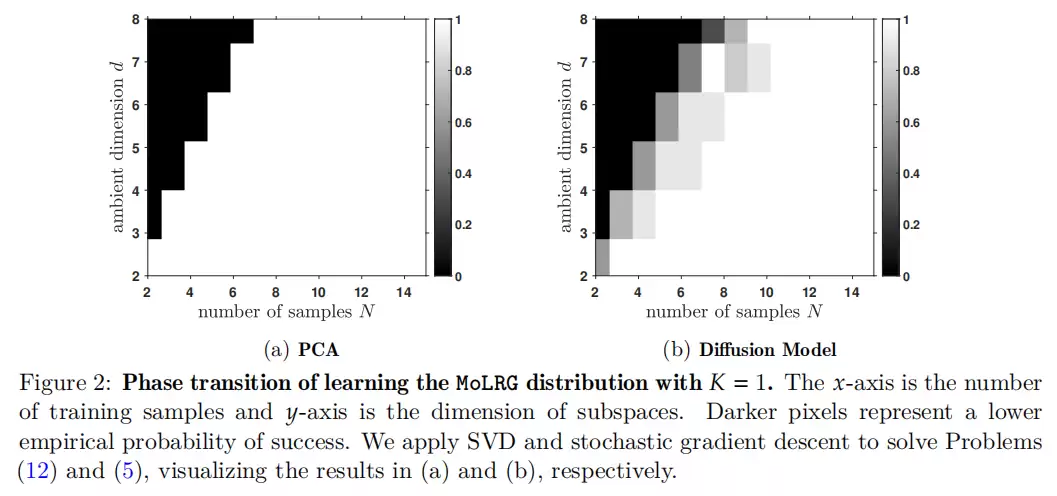
这个结论非常重要。它首先说明,在简化模型里,扩散模型的去噪训练不是神秘的黑箱拟合,而是在恢复数据的“主心骨”——主子空间结构。更重要的是,PCA的样本复杂度不是由环境维度决定的,而是由子空间的内在维度决定的。只要训练样本超过内在维度,模型就能稳定恢复这个结构。这给“逃离维度灾难”提供了一个最直接的证据。
06 理论结果二:多个低秩高斯 → 等价于子空间聚类
真实数据当然不会只来自一个子空间。比如图像里既有猫,又有狗,还有不同风格和姿态。一个子空间根本盖不住。于是作者考虑了更复杂的低秩高斯混合模型,也就是多个低维子空间并存的情况。
这时,问题从PCA变成了子空间聚类(subspace clustering)。子空间聚类要干两件事:一是判断每个样本属于哪个子空间,二是恢复每个子空间的基底。
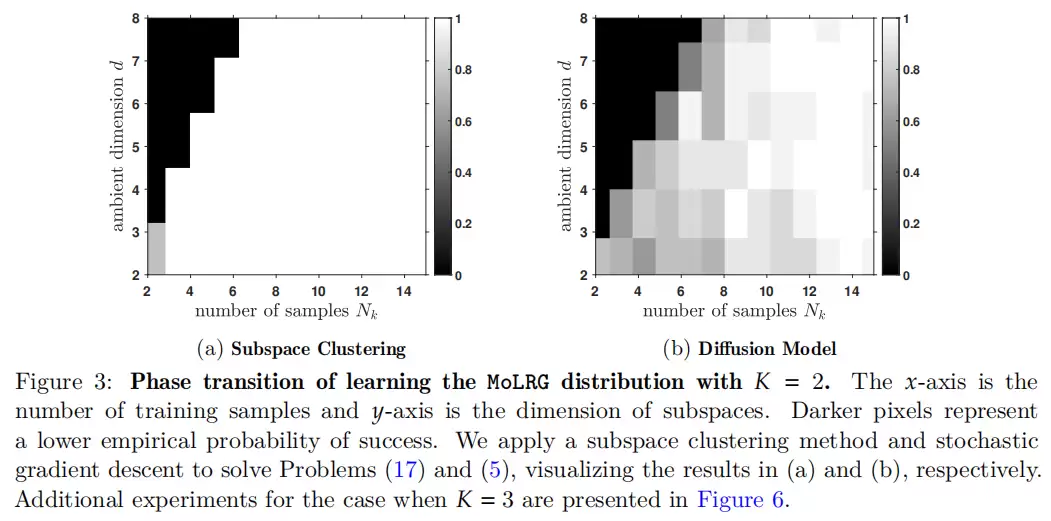
论文证明,在一定假设下,扩散模型的训练目标等价于一个经典的子空间聚类问题。这意味着扩散模型在训练时,隐式地学习了对不同数据成分进行分类,并分别恢复其低维结构。这个结论把扩散模型和经典的无监督学习(PCA、子空间聚类)建立了一个漂亮的联系。你看到了,从单个低秩高斯到多个,对应的正是从PCA到子空间聚类的跨越。
07 样本复杂度:内在维度才是关键
整篇论文最核心的理论结论可以概括为一句话:扩散模型泛化的关键在于数据的“内在维度”,而不是“环境维度”。
设环境维度为D,子空间维度为d,且 d << D。传统理论会告诉你,学习任意高维分布的样本复杂度可能取决于D,甚至呈指数增长。但本文的结果表明,在低秩结构存在时,关键变量变成了d。
更具体地说:
- 对于单个低秩高斯,当样本数n > d时,可以恢复底层子空间;当n < d时,就恢复不了。
- 对于多个成分,如果每个成分的样本数都超过其内在维度,就可以恢复其各自的子空间;否则,对应子空间可能无法被正确学习。
这给出了一个非常清晰的“相变”图景:学习难度从环境维度转移到了内在维度上。这也是论文标题里“Breaking the Curse of Dimensionality”的真正含义。扩散模型不是无条件地战胜了维度灾难,而是在数据本身具备低维结构时,其学习难度才被控制住。
08 从记忆到泛化:清晰的相变&现象
扩散模型是真的“理解”了数据,还是仅仅“记住了”训练集?这是生成模型理论里的关键问题。如果只是记忆,那它生成的新样本不过是训练数据的变体;如果泛化了,它就能生成从未见过、但仍符合规律的新内容。
本文把这个问题和样本复杂度联系起来。作者发现,当训练样本不足时,模型处于“记忆模式”;当样本超过某个阈值后,就进入“泛化模式”。而这个阈值,恰恰与数据的内在维度相关。
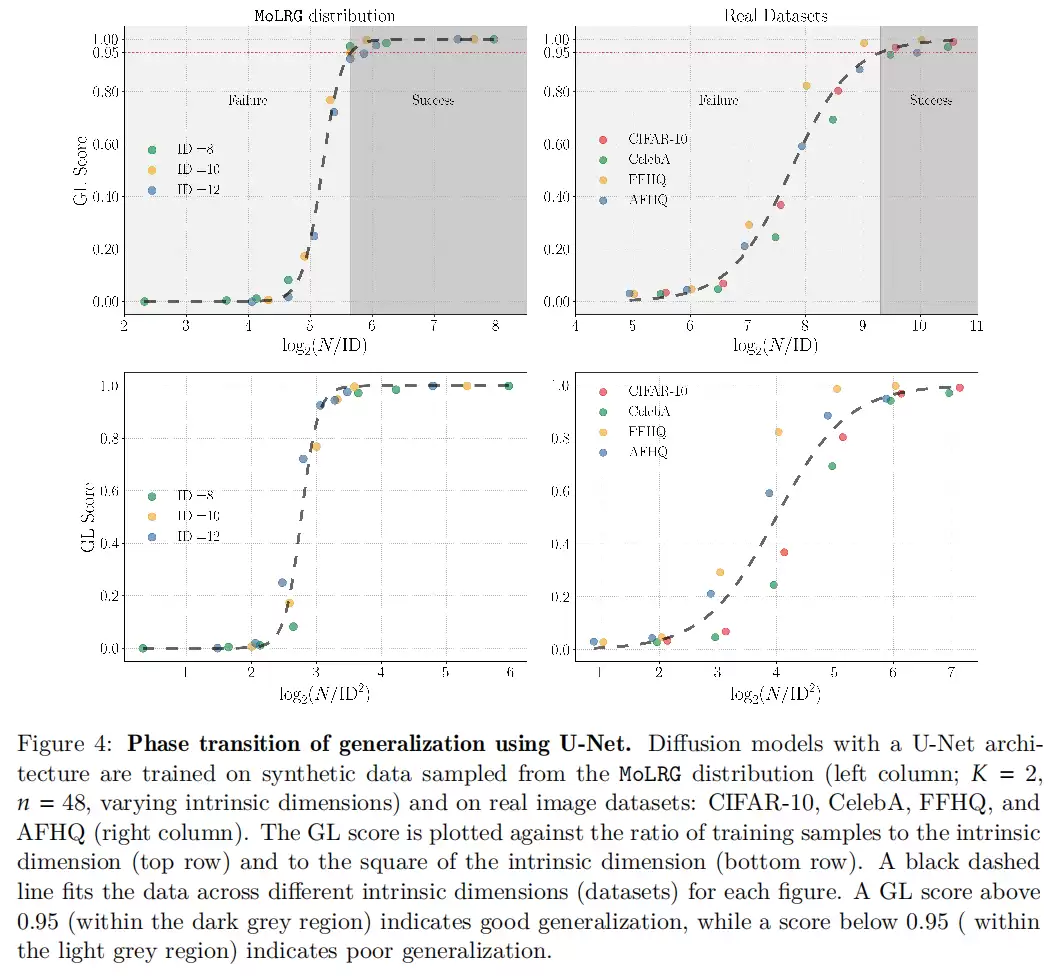
论文在合成数据和真实图像数据上都观察到了这种相变。这说明,扩散模型的泛化不是一个模糊的经验现象,而是有清晰的几何基础:当样本数覆盖了真实分布中的关键变化方向时,模型才能真正泛化。这对理解大模型训练也很有启发——数据规模重要,但数据是否覆盖了关键的变化方向,可能更关键。
09 子空间基底 ≈ 语义方向?
这篇论文还有一个非常有意思的实践发现。作者分析了预训练扩散模型中去噪网络的Jacobian矩阵(一种梯度矩阵),并研究了它的奇异向量。实验发现,某些最主要的奇异向量,可以作为语义编辑方向。
沿着这些方向去扰动中间噪声状态,你就可以控制生成图像中的属性,比如性别、发型、颜色、面部特征。相比之下,沿随机方向扰动,几乎不会产生稳定、可解释的变化。

这个发现非常诱人。它说明,扩散模型内部的低维结构,并不只是数学家笔下的抽象子空间,而可能对应着真实图像中的语义变化坐标。换句话说,模型内部已经以一种无监督的方式,把“发型”和“肤色”这些概念,编码成了不同的低维方向。这为训练后图像编辑、可控生成和无监督语义发现,提供了坚实的理论基础。
10 这篇文章与现有理论有何不同?
近几年,关于扩散模型的理论研究已经不少,主要围绕几个方向:采样收敛性、得分函数近似、记忆与泛化的边界、以及用高斯混合模型分析其行为。
本文的独特之处在于,它不是研究任意分布,也不是只研究全秩或各向同性的高斯混合,而是把重点放在了低秩协方差结构 上。这一步非常关键。因为低秩性直接对应数据的低维结构,而低维结构正是突破维度灾难的核心。
所以,这篇论文的贡献不仅仅是“又分析了一个高斯模型”,而是把问题从“学习高维密度”转换成了“恢复低维子空间结构”。这种问题重写的思路,非常有启发性。
11 论文贡献总结
可以将这篇论文的贡献概括为四点:
1. 提出MoLRG作为分析扩散模型低维分布学习的理论模型
用低秩高斯混合模型刻画数据的低维结构,让“低维流形假设”可以进入可证明的数学框架。
2. 证明扩散训练等价于PCA/子空间聚类
在单个低秩高斯下等价于PCA,在多个下等价于子空间聚类。这为理解扩散模型的训练提供了一个极其清晰的几何解释。
3. 证明样本复杂度随内在维度线性增长
证明了学习底层MoLRG分布所需的最小样本数主要由内在维度决定,而非环境维度。这为模型为何能逃离维度灾难提供了理论解释。
4. 将理论与真实图像的泛化和可控生成联系起来
在真实图像上观察到泛化相变,并发现低维子空间基底与语义方向之间存在对应关系,为可控生成提供了理论启发。
12 思想精髓:扩散模型是一种低维结构学习器
如果用一句更抽象的话来概括,那就是:扩散模型的成功,源于它隐蔽地学习了数据的低维结构。
这句话有三个层次。第一,真实数据不是任意高维的,而是有结构的。第二,这种结构可以用低维子空间或流形近似。第三,扩散模型的去噪训练,恰好能隐式地恢复这些低维结构。因此,扩散模型并非“魔法般地战胜了高维性”,而是利用了真实世界数据分布的几何规律。这也解释了为什么它在自然图像上非常成功,而在结构更稀疏、约束更复杂的领域(如某些稀有分子数据)中还会面临挑战。
13 对AI药物设计和分子生成的启发
虽然本文主要是针对图像,但它对AI药物设计同样有深刻的启发。分子数据本质上也是高维、离散、稀疏且强约束的。无论是分子图、三维构象还是蛋白-配体复合物,都不是“随机分布”的,而是受到化学价键规则、构象能量面、合成可及性等重重限制。
因此,分子生成模型真正需要学习的,也可能不是整个组合爆炸式的化学空间,而是其中可合成、可稳定、可结合、可优化的低维有效结构。
从这个视角出发,可以提出几个非常值得研究的问题:
1. 分子扩散模型是否也在学习低维化学结构?
药物样分子受到类药性和骨架模式约束,其有效化学空间可能具有局部低维结构。
2. 三维构象生成是否由少数关键自由度控制?
分子构象的复杂性,往往集中在可旋转键和环系构象等少数自由度上。模型可能主要在学习这些低维构象“旋钮”。
3. 蛋白-配体结合是否存在低维相互作用流形?
结合模式(如氢键、疏水作用)是有限的,不同配体可能共享相似的“结合模式子空间”。
4. 可控分子生成中的“性质方向”是否类似图像的语义方向?
在图像中,存在控制“发型”的方向。那么在分子生成中,是否存在对应于logP、极性、结合模式或选择性的“性质方向”?
5. 数据规模与泛化能力是否也由内在维度决定?
小分子活性数据有限。如果任务的“内在维度”较低,扩散模型或许仍能泛化;但如果任务涉及复杂的靶点诱导契合,样本复杂度可能会显著升高。
这些问题都值得进一步深挖。从这点来看,本文不仅是一篇图像扩散模型的理论论文,也为分子扩散模型和AI药物设计提供了一条重要的理论思路:与其和“维度灾难”硬碰硬,不如去理解数据本身的“内在维度”。
14 论文的局限性
当然,作为一篇理论文章,我们需要理性看待它的边界。
1. MoLRG是理想化模型
真实图像分布并不严格服从低秩高斯混合。它更像是一种局部线性近似,用于捕捉低维流形的基本性质,不能直接等同于对真实大规模扩散模型的完整解释。
2. 子空间正交假设较强
为了理论可解,论文假设不同子空间之间有很好的分离性,甚至部分分析中要求相互正交。真实数据中的语义流形往往是重叠、弯曲和纠缠的。
3. 网络参数化仍然简化
实际扩散模型用的大多是U-Net、Transformer等高度非线性的复杂架构。为了建立理论等价关系,论文使用了简化的去噪网络参数化。这使得理论结果有解释价值,但与实际模型之间仍存在距离。
4. 真实图像实验是支持性证据
论文在真实图像上观察到的泛化相变和语义方向,更多是对理论直觉的一种支持,而非严格证明真实模型就完全按MoLRG的机制工作。
总结
这篇论文为扩散模型提出了一个更深层的解释:它的成功,很可能建立在对数据低维结构的学习之上。在MoLRG假设下,作者证明了扩散模型训练与PCA / 子空间聚类之间的等价关系,并指出其样本复杂度主要由内在维度决定,为模型逃离维度灾难提供了清晰的理论图景。
当然,理论仍建立在理想化假设之上,距离完整解释真实大规模扩散模型还有很长的路。但它的重要性恰恰在于:它把一个高度经验化的现象,转化成了一个可以分析、可以证明、可以扩展的数学问题。对于今天的生成式AI研究而言,这类理论工作非常重要。因为真正深刻的理解,往往不是告诉我们模型“能做什么”,而是告诉我们模型“为什么能做到”,以及“在什么条件下才能做到”。




