CUDA 第 9 课:Occupancy、Block Size 与 Kernel 启动配置调优
前面几节课我们已经看到,TILE 大小、blockDim 的配置、shared memory 的使用以及 bank conflict 的处理,每个环节都会对最终性能产生实实在在的影响。到了第 9 课,我们来解决一个更核心的问题:当你写好一个 kernel 后,到底应该怎么设置 block size,才能榨干 GPU 的性能?Occupancy 这个指标,又到底意味着什么?
一、本节课目标
这堂课的重点其实很清晰:搞懂什么是 occupancy,理解 block size 如何影响它;同时要意识到,occupancy 高并不等同于程序反赌。在此基础上,学会用 CUDA 自带的 API 去估算理论 occupancy,并通过实际实验去验证不同 block size 下的 kernel 执行时间。说白了一句话:别靠猜,用数据说话。
二、核心原理
1. 什么是 Occupancy?
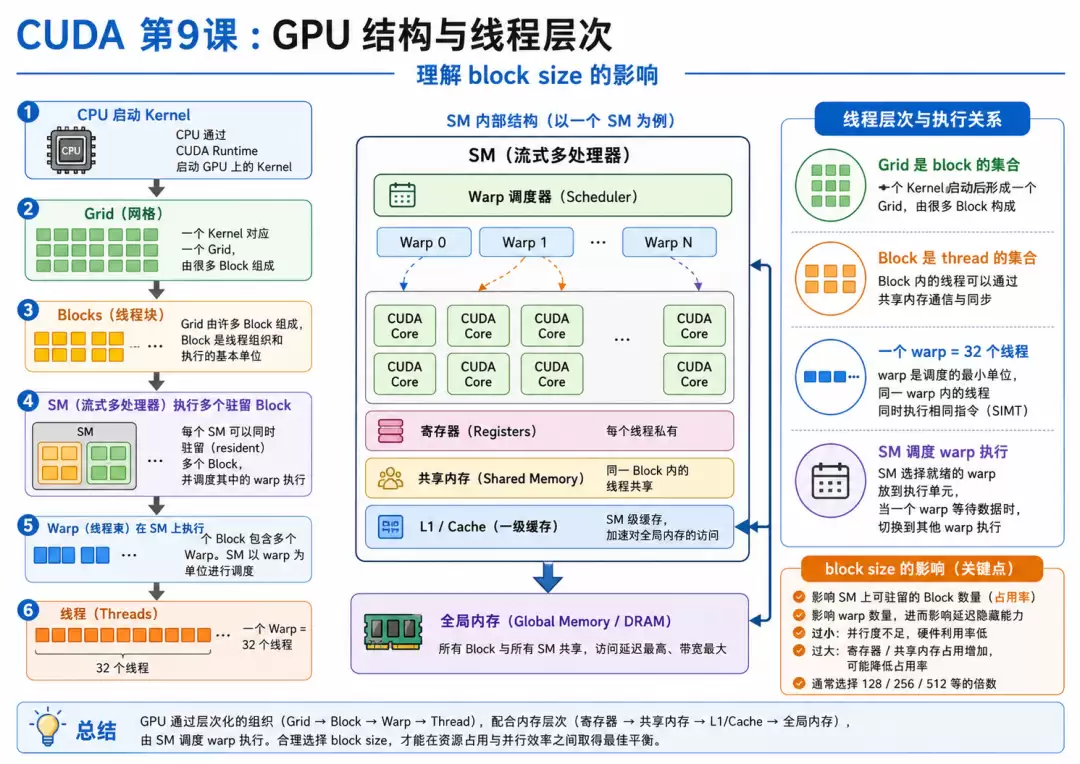
Occupancy 这个概念,说白了就是衡量一个 SM(流式多处理器)上活跃 warp 的利用率。举个例子你就明白了:一个 SM 理论上最多能同时塞进去 64 个 warp,但你的 kernel 因为各种资源限制,实际只能跑 32 个,那 occupancy 就是 50%。
那 GPU 为什么对 occupancy 这么上心?核心原因在于它要隐藏延迟。GPU 访问 Global Memory 的时候是有延迟的,当一个 warp 在等数据回来,SM 不会闲着,它会立即切换去执行另一个 warp。warp A 等内存 -> SM 执行 warp B -> warp B 等内存 -> SM 执行 warp C,靠着这种“轮转”机制,高 occupancy 就能更有效地把内存延迟给掩盖过去。
2. Block Size 为什么影响 Occupancy?
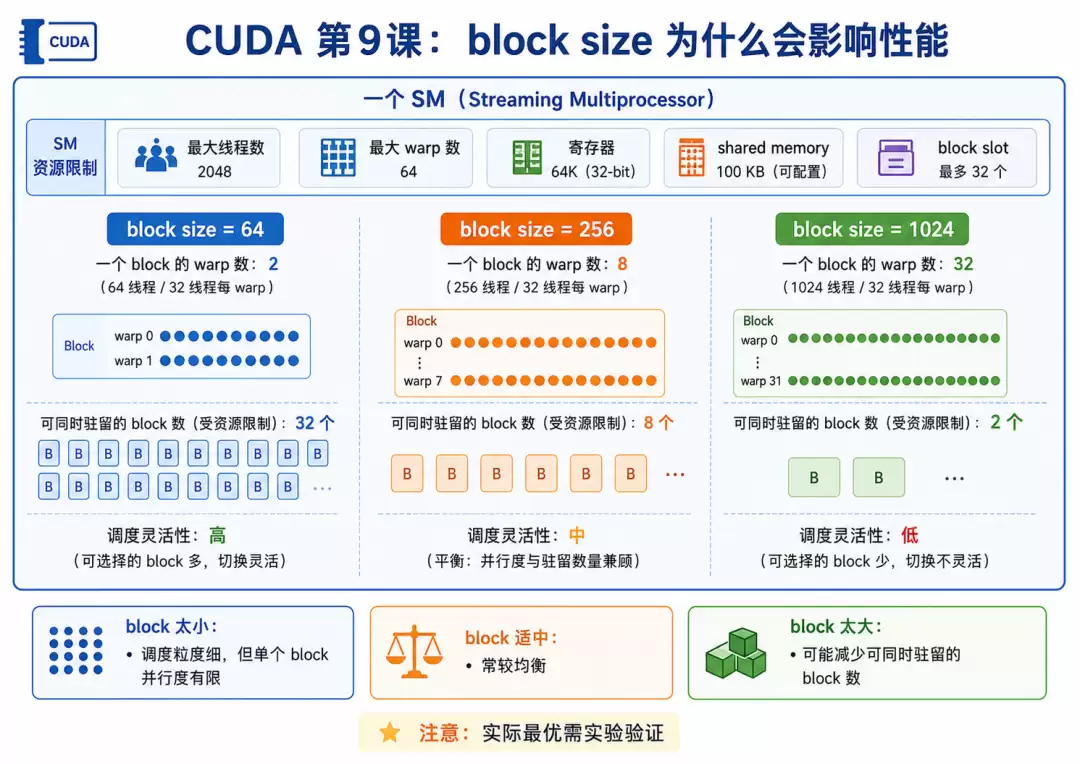
每个 block 在 SM 上都要占用一堆资源:线程、warp、寄存器、shared memory,还有 block slot。你选的 block size 不同,这些资源的消耗情况就截然不同。
比方说,block size = 64 时,每个 block 里只有 2 个 warp;block size = 256 时是 8 个 warp;到了 block size = 1024,那就是 32 个 warp 了。block 选得太小,虽然能启动大量 block,但每个 block 里的线程数太少,调度开销会变大,单个 block 内的并行度也不够。反过来,block 选得太大,一个 block 占用的线程、寄存器、shared memory 太多,导致一个 SM 上能同时放的 block 数量锐减,调度灵活性反而下降。所以 block size 真不是越大越好,常见的起点通常是 128、256 或 512。
3. Occupancy 高一定最快吗?
这是个很经典的认知误区。Occupancy 只告诉你 SM 上有多少个 warp 可供调度,但最终性能还取决于很多其他因素:Global memory 访问是否 coalesced、shared memory 里有没有 bank conflict、寄存器有没有溢出、指令吞吐是不是成了瓶颈、L1/L2 cache 命中率如何,以及 kernel 本身的计算密度。所以,高 occupancy 只是“有可能”带来高性能的一个前提条件,绝不是充分条件。
本课要建立的核心认识,其实就是下面这张图所表达的:occupancy 和性能之间的关系是复杂的,需要通过实验去探索最优配置。
 在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
三、实验设计
为了验证上述观点,我们写一个简单的 compute kernel,让所有线程对数组做多轮 fmaf 计算。操作不复杂,就是反复执行 v = fmaf(v, 1.000001f, 0.000001f);。然后我们分别用 block size = 64、128、256、512、1024 来跑,重点观察几个指标的变化:理论 occupancy 算出来是多少,kernel 执行时间差多少,GFLOPS 表现如何,以及最快的那组 block size 是不是对应着最高的 occupancy。答案可能跟你直觉想的不太一样。
四、完整可运行 CUDA C ++ 代码
代码我们已经准备好了,保存为 lesson09_occupancy_block_size.cu。
#include
#include
#include
#include
#include
#include
#include
#define CUDA_CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
std::cerr << "CUDA Error: " << cudaGetErrorString(err) \
<< " at " << __FILE__ << ":" << __LINE__ << std::endl; \
std::exit(EXIT_FAILURE); \
} \
} while (0)
/*
* 一个简单的计算型 kernel。
*
* 每个线程处理一个元素。
* iters 控制每个元素做多少次 fmaf。
*
* fmaf(a, b, c) 大致表示:
* a * b + c
*
* 通常可以粗略按 2 FLOPs 估算。
*/
__global__ void compute_kernel(const float* in, float* out, int n, int iters) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
float v = in[idx];
for (int i = 0; i < iters; ++i) {
v = fmaf(v, 1.000001f, 0.000001f);
}
out[idx] = v;
}
}
/*
* 测量 kernel 平均执行时间。
*
* 注意:
* 这里测的是 kernel time only。
* 不包含 H2D、D2H、cudaMalloc、CPU 初始化。
*/
float time_kernel(const float* d_in,
float* d_out,
int n,
int iters,
int block_size,
int repeat) {
int grid_size = (n + block_size - 1) / block_size;
/*
* warmup。
*/
compute_kernel<<>>(d_in, d_out, n, iters);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaDeviceSynchronize());
cudaEvent_t start, stop;
CUDA_CHECK(cudaEventCreate(&start));
CUDA_CHECK(cudaEventCreate(&stop));
float total_ms = 0.0f;
for (int r = 0; r < repeat; ++r) {
CUDA_CHECK(cudaEventRecord(start));
compute_kernel<<>>(d_in, d_out, n, iters);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaEventRecord(stop));
CUDA_CHECK(cudaEventSynchronize(stop));
float ms = 0.0f;
CUDA_CHECK(cudaEventElapsedTime(&ms, start, stop));
total_ms += ms;
}
CUDA_CHECK(cudaEventDestroy(start));
CUDA_CHECK(cudaEventDestroy(stop));
return total_ms / repeat;
}
/*
* 使用 CUDA Runtime API 估算理论 occupancy。
*/
double estimate_occupancy_percent(int block_size,
const cudaDeviceProp& prop) {
int active_blocks_per_sm = 0;
CUDA_CHECK(cudaOccupancyMaxActiveBlocksPerMultiprocessor(
&active_blocks_per_sm, compute_kernel, block_size, 0));
int active_warps = active_blocks_per_sm * block_size / prop.warpSize;
int max_warps = prop.maxThreadsPerMultiProcessor / prop.warpSize;
return 100.0 * static_cast(active_warps) /
static_cast(max_warps);
}
int main(int argc, char** argv) {
int n = 1 << 26; // 67,108,864 floats,约 256 MB
int iters = 256; // 每个元素计算 256 次
int repeat = 10;
if (argc >= 2) {
n = std::atoi(argv[1]);
}
if (argc >= 3) {
iters = std::atoi(argv[2]);
}
if (argc >= 4) {
repeat = std::atoi(argv[3]);
}
cudaDeviceProp prop;
CUDA_CHECK(cudaGetDeviceProperties(&prop, 0));
std::cout << "CUDA Lesson 9: Occupancy and Block Size\n";
std::cout << "GPU name: " << prop.name << "\n";
std::cout << "SM count: " << prop.multiProcessorCount << "\n";
std::cout << "Warp size : " << prop.warpSize << "\n";
std::cout << "Max threads per block : " << prop.maxThreadsPerBlock << "\n";
std::cout << "Max threads per SM: " << prop.maxThreadsPerMultiProcessor << "\n";
std::cout << "Shared memory per block : "
<< prop.sharedMemPerBlock / 1024 << " KB\n";
size_t bytes = static_cast(n) * sizeof(float);
std::cout << "Problem size\n";
std::cout << " Elements: " << n << "\n";
std::cout << " Array size: "
<< bytes / 1024.0 / 1024.0 << " MB\n";
std::cout << " Iters per element : " << iters << "\n";
std::cout << " Repeat: " << repeat << "\n";
std::vector h_in(n);
std::vector h_out(n);
for (int i = 0; i < n; ++i) {
h_in[i] = static_cast((i % 100) + 1) * 0.001f;
}
float* d_in = nullptr;
float* d_out = nullptr;
CUDA_CHECK(cudaMalloc(&d_in, bytes));
CUDA_CHECK(cudaMalloc(&d_out, bytes));
CUDA_CHECK(cudaMemcpy(d_in, h_in.data(), bytes, cudaMemcpyHostToDevice));
std::vector block_sizes = {64, 128, 256, 512, 1024};
std::cout << "\n"
<< std::left << std::setw(12) << "block"
<< std::setw(14) << "grid"
<< std::setw(18) << "occupancy(%)"
<< std::setw(14) << "time(ms)"
<< std::setw(14) << "GFLOPS"
<< "status\n";
for (int block_size : block_sizes) {
if (block_size > prop.maxThreadsPerBlock) {
std::cout << std::left << std::setw(12) << block_size
<< std::setw(14) << "-"
<< std::setw(18) << "-"
<< std::setw(14) << "-"
<< std::setw(14) << "-"
<< "SKIP: block_size > maxThreadsPerBlock\n";
continue;
}
int grid_size = (n + block_size - 1) / block_size;
double occupancy = estimate_occupancy_percent(block_size, prop);
float ms = time_kernel(d_in, d_out, n, iters, block_size, repeat);
/*
* 每次 fmaf 粗略按 2 FLOPs 估算。
*/
double flops = 2.0 * static_cast(n) * static_cast(iters);
double gflops = flops / (ms / 1000.0) / 1e9;
std::cout << std::fixed << std::setprecision(3)
<< std::left
<< std::setw(12) << block_size
<< std::setw(14) << grid_size
<< std::setw(18) << occupancy
<< std::setw(14) << ms
<< std::setw(14) << gflops
<< "OK\n";
}
CUDA_CHECK(cudaMemcpy(h_out.data(), d_out, bytes, cudaMemcpyDeviceToHost));
/*
* 简单检查输出是否是有限数。
*/
bool ok = true;
for (int i = 0; i < 10; ++i) {
if (!std::isfinite(h_out[i])) {
ok = false;
break;
}
}
std::cout << "Check output finite: " << (ok ? "PASS" : "FAIL") << "\n";
CUDA_CHECK(cudaFree(d_in));
CUDA_CHECK(cudaFree(d_out));
return ok ? 0 : 1;
} 五、编译与运行
我们用 Tesla T4 来做测试,编译命令如下:
nvcc -O3 -arch=sm_75 lesson09_occupancy_block_size.cu -o lesson09_occupancy直接运行默认实验:
./lesson09_occupancy当然也支持自定义参数,比如 ./lesson09_occupancy 67108864 256 10,第一个参数是元素数量 n,第二个是每个元素的 fmaf 迭代次数,第三个是重复测量的次数。
六、输出现象
我们在 Tesla T4 上跑出来的结果是这样的:
CUDA Lesson 9: Occupancy and Block Size
GPU name: Tesla T4
SM count: 40
Warp size : 32
Max threads per block : 1024
Max threads per SM: 1024
Shared memory per block : 48 KB
Problem size
Elements: 67108864
Array size: 256 MB
Iters per element : 256
Repeat: 10
block grid occupancy(%) time(ms) GFLOPS status
64 1048576 100.000 11.243 3055.998 OK
128 524288 100.000 10.850 3166.698 OK
256 262144 100.000 6.131 5604.707 OK
512 131072 100.000 6.715 5116.723 OK
1024 65536 100.000 6.729 5105.893 OK
Check output finite: PASS七、分析实验结果
1. block=64 为什么可能不够快?
block=64 时每个 block 只有 2 个 warp,虽然 occupancy 也是 100%,但 block 数量过多,调度开销上来了,单个 block 内能组织的工作也比较有限,导致整体效率偏低。
2. block=256 为什么常常表现较好?
block=256 是很多 CUDA kernel 的默认配置,每个 block 有 8 个 warp。它在多个维度上达成了不错的平衡:线程数够多、warp 数适中、block 数量不会多到离谱、SM 上通常能驻留多个 block,调度灵活性很好。从数据上看,它在这次实验里也跑到了最快的 6.131 ms,GFLOPS 达到 5604.7,表现相当突出。
3. block=1024 为什么不一定最快?
block=1024 虽然线程很多,每个 block 有 32 个 warp,但 block 太大了,一个 SM 上能同时放的 block 数量会减少,调度灵活性下降,寄存器资源的压力也会变大。所以即使 occupancy 依然是 100%,实际跑下来却比 block=256 要慢一些。
4. 为什么 occupancy 一样,性能还不同?
这正是本课要强调的关键点:occupancy 只说明 SM 上可以驻留多少个 warp,但它没有告诉你这些 warp 的执行效率如何、访存是否合并、寄存器使用是否高效、指令调度是否顺畅、cache 行为是否友好。所有这些因素叠加在一起,才共同决定了最终的执行时间。因此,即便所有 block size 都显示 100% occupancy,运行时间的差异依然很明显。
八、和前面课程的关系
如果回头去看之前做矩阵乘法时的实验,你可能会发现 TILE=8、16、32 时,性能有明显差异。这不光是 shared memory tile 大小的问题,更关键的是,block = TILE × TILE,所以 block size 本身也跟着变了:TILE=8 对应 block=64 线程,TILE=16 对应 block=256 线程,TILE=32 对应 block=1024 线程。第 9 课的内容恰好解释了为什么 TILE 变化时,即使是 naive kernel,性能也会跟着起伏——本质就是 block size 变了。
最后做个总结:block size 确实会影响 kernel 性能;occupancy 表示 SM 上活跃 warp 的比例,它有助于隐藏延迟,但不是性能的唯一决定因素;block 太小调度效率低,block 太大调度灵活性差;256 threads/block 是一个常见但不绝对的最优起点;最终性能必须通过实验来验证。一句话:别盲目追求高 occupancy,实际跑一跑,哪个最快就用哪个。




