RAG 混合检索深度解读:BM25 与向量分数为何不能直接相加?
近期与多位从事 RAG 工程的朋友交流混合检索 (Hybrid Search) 时,发现一个颇为普遍的现象——很多工程师对“混合检索”的理解仍停留在较浅的层面。面试过程中,当被问及 BM25 和向量分数如何融合时,十之八九的回答都是“加权相加,调调系数”。这个答案大方向正确吗?没错,但距离真正可落地的解决方案,中间还隔着好几层理解。
在深入探讨之前,我们先统一几个核心术语,避免后续讨论产生误解。
| 术语 | 含义 |
|---|---|
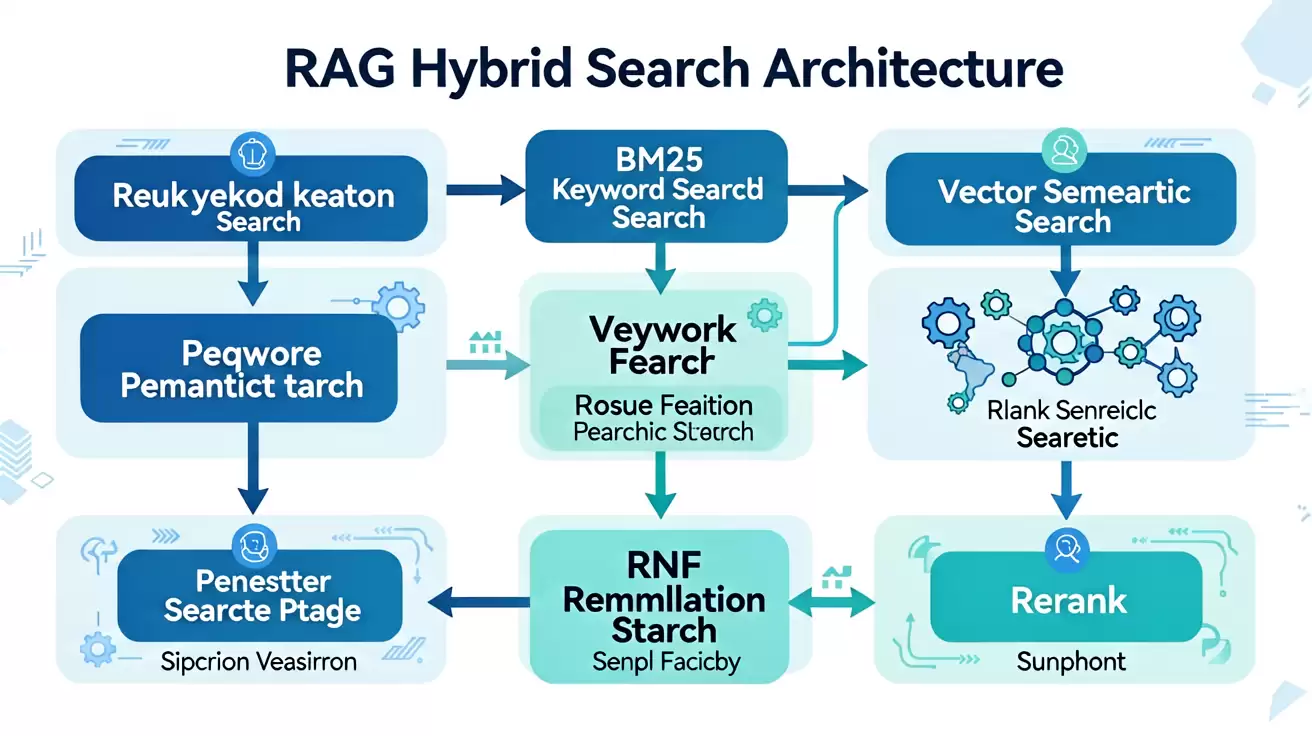
| Hybrid Search | 同时运用关键词检索与语义检索两路召回 |
| BM25 Score | 基于关键词匹配频率的统计评分 |
| Vector Score | 基于 Embedding 语义相似度的评分 |
| RRF | Reciprocal Rank Fusion,基于排名的融合方法,而非直接分数相加 |
| Rerank | 召回阶段之后的精排序阶段,通常采用 Cross-Encoder 模型 |
面试现场:一个常被误解的问题
在 RAG 工程面试中,常会出现这样一个问题:
这个问题实际上是一个经典的“陷阱题”。表面上是在询问权重配比,但面试官真正想考察的是:你是否明白 BM25 和向量这两路分数,在本质上就不应该直接相加。只有理解到这一层,你才能自然地引出“我们采用 RRF 按排名融合,并根据 Query 类型动态切换通道”——这才是面试官期望听到的答案。
一句话总结:BM25 关键词和向量语义两路不能进行分数硬加,正确的做法是按 Query 类型划分通道,最后再通过一次 Rerank 进行精排。
典型的翻车回答
最常见的回答形式如下:
final_score = 0.5 * vector_score + 0.5 * BM25_score# 根据效果调整系数
这个回答不能说完全错误——大方向是对的,Hybrid 确实需要合并两路结果。从配置层面,“能跑”,主流开源框架(如 LangChain、LlamaIndex)也确实提供了 alpha 这个可调节参数。因此,面试官通常不会直接否定,但这样的回答也暴露出理解深度的天花板。
问题究竟出在哪里?
核心在于:BM25 分数与向量余弦相似度根本不在同一个数量级。
- BM25 是一种无上限的累计评分,其量级会随着文档长度和命中关键词的数量而浮动。一篇较长的文档在命中多个关键词时,分数可能高达数十甚至上百。
- 向量余弦相似度则是经过归一化处理的几何距离,量级稳定在
[0, 1]或[-1, 1]的固定窄区间内。
将两个性质完全不同的数字直接相加,无论权重如何调整,结果要么是一边完全压制另一边,要么是强行归一化后抹杀了区分度。问题的根源不在于权重 0.5 不对,而在于“对分数进行加权”这一做法本身就不正确。在生产环境中,依靠这个公式调整一周也很难得出理想结果,因为调节旋钮的方向本身就是错误的。
深度解析:分数尺度为何不能直接相加
我们先分别审视一下这两位“选手”的评分机制,就能明白它们为何难以融合。
BM25 的评分机制
BM25 公式本质上是 TF-IDF 的改进版:
score(D, Q) = Σ IDF(qi) * (tf(qi, D) * (k1 + 1)) / (tf(qi, D) + k1 * (1 - b + b * |D|/a vgdl))
其关键特征有三个:
- 累加性:每个命中关键词的贡献会累加起来,命中词越多,分数越高。
- 无上限:分数未归一化到固定区间,会随着语料库和文档长度浮动。
- 文档长度惩罚:通过
|D|/a vgdl项对长文档进行适度惩罚,但无法完全消除长度带来的影响。
向量相似度的评分机制
向量相似度(通常指余弦相似度)的计算方式:
cos_sim(A, B) = (A · B) / (||A|| * ||B||)
其关键特征也同样有三条:
- 有界性:结果严格限定在
[-1, 1]区间内。 - 归一化:向量本身已进行了 L2 归一化,分数不受文档长度影响。
- 语义导向:捕捉的是语义层面的接近程度,而非字面上的匹配。
量级对比实例
假设一个文档库的检索结果如下:
| 文档 | BM25 分数 | 向量余弦分 |
|---|---|---|
| Doc A | 12.5 | 0.87 |
| Doc B | 8.3 | 0.91 |
| Doc C | 3.1 | 0.72 |
如果直接使用 0.5 * BM25 + 0.5 * vector 进行计算,结果会如何?
| 文档 | 计算过程 | 混合分 |
|---|---|---|
| Doc A | 0.512.5 + 0.50.87 | 6.685 |
| Doc B | 0.58.3 + 0.50.91 | 4.605 |
| Doc C | 0.53.1 + 0.50.72 | 1.91 |
显而易见,BM25 的分数完全主导了排序结果,向量分数的差异(0.87 对比 0.91)在 BM25 的巨大量级面前几乎可以忽略不计。向量这一路实际上并未对最终的排序决策产生实质性影响。
Hybrid 调参的真正可操作变量
Hybrid 调参,其真正可操作的变量实际上包含三个层次,从粗到细依次为:Query 路由、合并算法、以及按类型动态调整的权重。只有厘清这三层,调参才能落到实处。
判断一:分数尺度不同,不能直接相加
BM25 是无上限的累加评分,而向量相似度则稳定在一个固定区间。两个分数本身就处于不同的度量体系——不归一化,BM25 会压制向量;归一化,又会抹杀其区分度。
结论是:能不对分数进行调整就尽量不对分数调整,让两路各自独立地排出名次,再去合并这两份排名,才是正确的做法。
判断二:起步阶段使用 RRF,无需调整分数
RRF(Reciprocal Rank Fusion)只看重排名,不关心具体分数。它的公式非常简洁:
RRF_score(d) = Σ_{r ∈ Ranks} 1 / (k + rank_r(d))
其中,k 是一个常数(通常取 60),rank_r(d) 是文档 d 在某一路召回中的排名。
RRF 的核心思想很简单:每条文档在两路召回里各自排名第几,按照“名次越靠前贡献越大”的原则合并成一份总分。这种方法对两路分数尺度差异完全免疫,几行代码即可实现,对于绝大多数 RAG 系统起步阶段来说足够使用。
具体实现也非常直接:
def rrf_fusion(bm25_results: list, vector_results: list, k: int = 60, top_n: int = 10):"""Reciprocal Rank Fusion 实现:param bm25_results: BM25 召回结果列表,按分数降序排列:param vector_results: Vector 召回结果列表,按分数降序排列:param k: RRF 常数,通常取 60:param top_n: 返回前 N 个结果"""scores = {}# BM25 路的贡献for rank, doc_id in enumerate(bm25_results, 1):scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank)# Vector 路的贡献for rank, doc_id in enumerate(vector_results, 1):scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank)# 根据 RRF 分数排序,取前 N 个sorted_docs = sorted(scores.items(), key=lambda x: x[1], reverse=True)return [doc_id for doc_id, _ in sorted_docs[:top_n]]
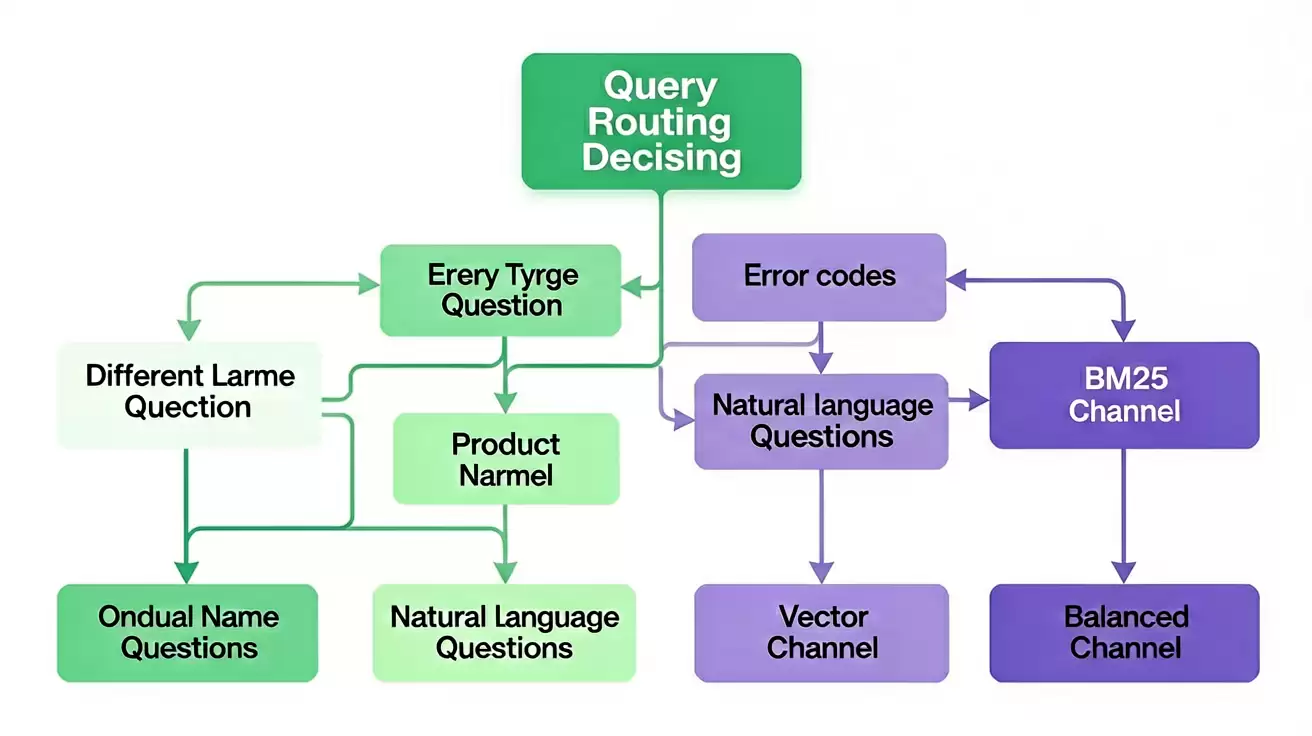
判断三:Query 类型决定哪一路应被侧重
不同类型的 Query 对两路检索的依赖程度天然存在差异,这一点很容易理解:
| Query 类型 | 示例 | 应主导的路 | 原因 |
|---|---|---|---|
| 编号/错误码 | ERR-4042, v2.3.1 | BM25 | 精确匹配优先,语义相似度难以区分 |
| 产品代号/术语 | K8s 节点漂移 | BM25 | 领域专有名词需要字面命中 |
| 自然语言描述 | "为什么订单创建后库存没扣减?" | Vector | 语义理解优先 |
| 混合型 | "ERR-500 是什么原因导致的?" | 平衡通道 | 既包含硬性 Token,又包含语义描述 |
与其耗费精力去调整一个全局的 alpha 系数,不如编写一个轻量级的 Query 分类器,根据类型将 Query 路由到不同的通道。这个思路在实际应用中要高效得多。
判断四:Hybrid 调参应关注 Bad Case,而非平均指标
这一点至关重要。Hybrid 的真正价值体现在尾部——它挽救的是单路检索失败的那一小部分 Case。整体平均召回率提升一两个百分点意义不大,但某类 Query(例如硬性 Token 漏召回、长描述被关键词带偏)从回答错误变为回答正确,才是真正有价值的改进。
调参时,优先顺序应为:将最近的失败案例进行分类,针对每一类问题去调整通道权重,而不是盯着一个平均值进行微调。
面试官追问链
理解了上述思路,就能从容应对面试官的连环追问。
追问1:BM25 和 Vector 分数尺度不同,为什么不能直接相加?
BM25 的分数是未经归一化的累加值——文档越长、命中词越多,分数越高,整体量级还会随语料库浮动;余弦相似度是归一化的几何距离,量级稳定。两个数字直接相加,一条 BM25 文档的分数动辄是向量分数的几十倍,向量那一路实际上根本没有参与排序决策。
强行进行 Min-Max 归一化也无法解决问题:BM25 的“满分 1.0”与向量的“满分 1.0”含义不同,属于同名不同义。BM25 的 1.0 可能意味着“此文档在当前 Query 下命中了所有关键词”,而向量的 1.0 则表示“两个向量方向完全一致”。归一化后,排序反而可能更加混乱。
修复路径有两条:要么不调整分数(使用 RRF 合并排名),要么换成可学习的归一化方法(例如使用 Cross-Encoder 为两路结果重新打分以对齐尺度)。
追问2:如何识别一个 Query 更依赖关键词还是语义?
一个轻量级的分类器就足够了,主要考察四个信号:
| 信号 | 判断逻辑 | 路由方向 |
|---|---|---|
| 正则匹配 | 命中 ID、错误码、版本号、订单号格式 | BM25 |
| 领域词典 | 命中“必须走关键词”的专有名词表(产品代号、合规术语等) | BM25 |
| Query 长度 | 很短的 Query(几个词以内)向量的区分度较差 | BM25 |
| 疑问句特征 | 出现“为什么/怎么/如何/能不能”等词 | Vector |
关键在于:这个分类器无需任何模型,仅靠规则加词典就能覆盖大多数路由需求,剩下不确定的 Query 走平衡通道兜底即可。
一个简单的实现示例:
import reclass QueryRouter:def __init__(self, domain_terms: list):# 领域词典self.domain_terms = set(domain_terms)# 正则模式:ID、错误码、版本号、订单号self.patterns = [r'[A-Z]+-d+', # ERR-4042r'v?d+.d+.d+',# v2.3.1r'ORDd{10,}', # ORD20260629001]# 疑问词self.question_words = ['为什么', '怎么', '如何', '能不能', '是什么', '怎么办']def classify(self, query: str) -> str:# 信号 1:正则匹配for pattern in self.patterns:if re.search(pattern, query):return 'bm25'# 信号 2:领域词典for term in self.domain_terms:if term in query:return 'bm25'# 信号 3:长度if len(query) <= 10:return 'bm25'# 信号 4:疑问句for word in self.question_words:if word in query:return 'vector'# 默认走平衡通道return 'balanced'
追问3:Hybrid 之后还需要 Rerank 吗?
需要。这两个步骤解决的是不同的问题,一个负责“不漏”,一个负责“不乱”。
| 阶段 | 职责 | 解决的问题 |
|---|---|---|
| Hybrid | 召回保证不漏 | 确保相关文档不被遗漏 |
| Rerank | 精排避免混乱 | 确保最相关的文档排在前面 |
RRF 合并出来的候选集,其排序仍然不够可靠——它只是简单地将两路的排名相加,对于“到底哪一条最切题”的判断还是比较粗糙。Rerank(通常使用 Cross-Encoder)能够联合查看 Query 与候选文档的语义信息,将真正相关的几条文档提到最前面。
缺少这一步,Hybrid 的优势只兑现了一半,因为最终输入到 Prompt 中的依然是排序粗糙的结果。
实战:售后知识库 Hybrid 调参完整迁移
理论讲再多,不如看一个完整的实战案例。售后 RAG 需要同时处理错误码追踪、产品政策咨询、客户情绪复述三类 Query,是 Hybrid 调参最容易暴露问题的场景。下面是一次完整的迁移过程。
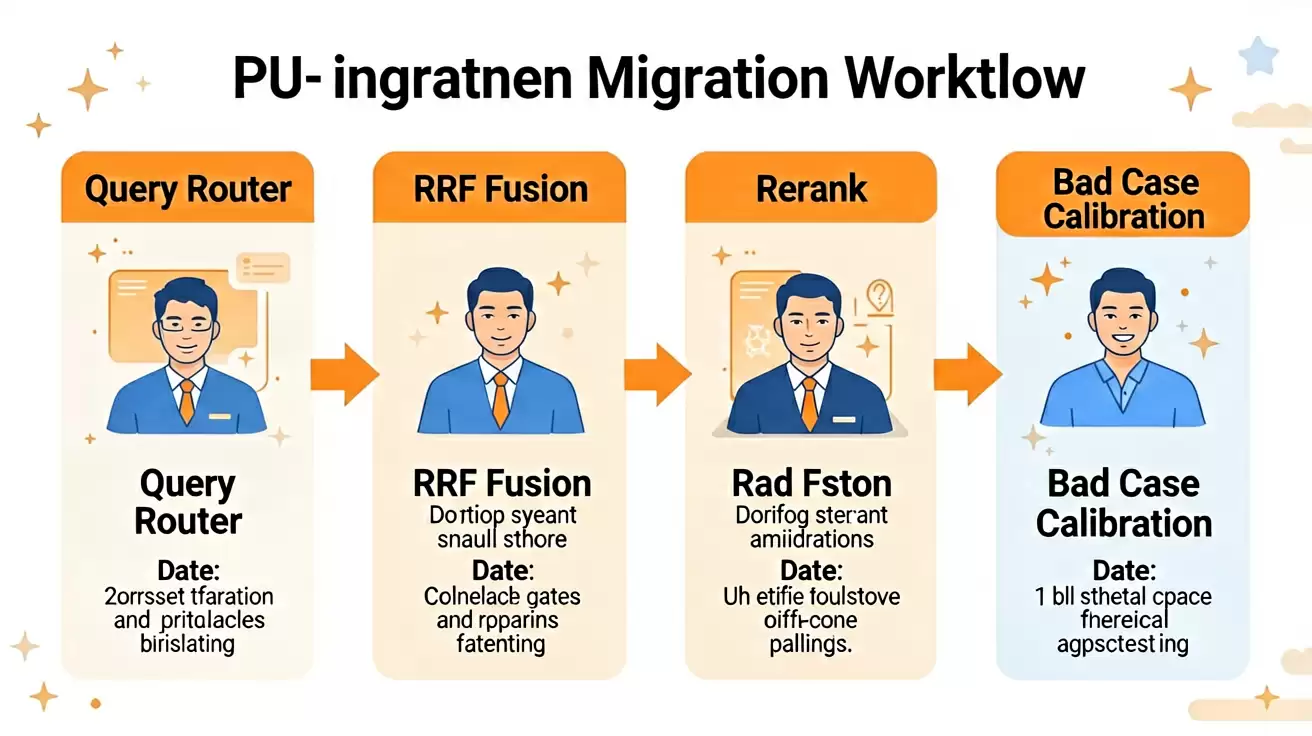
STEP 1:编写一个轻量 Query 分类器
基于正则表达式、领域词典、Query 长度和疑问句特征这些简单信号,将 Query 分为“偏关键词”、“偏语义”、“平衡”几类,并路由到不同的通道。
结果:大多数 Query 提前进入了合适的通道,少量不确定的 Query 则走平衡通道兜底。
STEP 2:将分数加权替换为 RRF
将合并方式改为只看排名的 RRF;调参的旋钮从“分数权重”转变为“通道参与度”,两路依然保持独立排序。
结果:尺度差异的问题直接消失,调参的方向变得清晰明确。
STEP 3:引入 Rerank 进行精排
在 RRF 之后,使用 Cross-Encoder 对 Top 候选文档再进行一次精排序,最终只将最相关的几条结果送入 Prompt。
结果:相关性更高的内容能够稳定地排到前面,Prompt 中的噪声显著降低。
STEP 4:使用 Bad Case 回归集进行校准
固定一组线上的失败案例作为回归集,按照 Query 类型分别调整通道权重;不看平均值,只关注每一类尾部案例是否被成功挽回。
结果:尾部 Case 的准确率明显回升,整体均值也随之提升。
关键数字
使用同一套包含 200 条 Query 的回归集(数据来源:内部售后回归集)进行迁移前后对比,效果立竿见影:
| 指标 | 迁移前 | 迁移后 | 提升幅度 |
|---|---|---|---|
| 错误码类准确率 | 52% | 93% | +41pp |
| 自然语言描述类 | 74% | 88% | +14pp |
| 整体准确率 | 66% | 90% | +24pp |
没有更换 Embedding 模型,没有调整 Chunk 大小,仅仅调整了 Hybrid 调参的三层结构——这个结果很有说服力。
RRF 的数学原理与参数选择
RRF 公式中的常数 k 通常取 60,这个值并非随意选择。
为什么选择 k=60?
k 的作用是控制排名靠后的文档对总分贡献的衰减速度:
k越小(如 k=10):排名差异的影响被放大,第 1 名和第 10 名的差距会很大。k越大(如 k=100):排名差异的影响被压缩,名次之间的贡献差距变小。
k=60 是一个经验值,在大多数场景下,它能让“排名靠前”的文档获得显著更高的权重,同时不会让排名稍后的文档完全失去竞争力。
RRF 对比其他融合策略
| 融合策略 | 核心思路 | 优点 | 缺点 |
|---|---|---|---|
| 分数加权 | α*BM25 + (1-α)*Vector | 实现简单 | 尺度不同,权重难以调整 |
| Min-Max 归一化后加权 | 归一到 [0,1] 再加权 | 看似解决了尺度问题 | 同名不同义,归一化后仍可能乱排 |
| RRF | 只看排名,按名次融合 | 对尺度差异免疫,参数少 | 未利用分数绝对值信息 |
| Cross-Encoder Rerank | 使用模型重新打分 | 精度最高 | 计算开销大,不适合召回阶段 |
Cross-Encoder Rerank 的原理
Rerank 阶段通常采用 Cross-Encoder 架构,它与 Embedding 模型(Bi-Encoder)存在本质区别:
Bi-Encoder 对比 Cross-Encoder
| 特性 | Bi-Encoder(Embedding) | Cross-Encoder(Rerank) |
|---|---|---|
| 输入 | Query 和 Document 分别进行编码 | Query 和 Document 拼接后一起编码 |
| 计算 | 可以预计算 Document 向量 | 必须实时计算每一对 (Query, Document) 的分数 |
| 速度 | 快,适合召回阶段 | 慢,适合精排阶段 |
| 精度 | 中等 | 高 |
| 典型模型 | text-embedding-3-small, BGE | BGE-Reranker, Cohere Rerank |
Cross-Encoder 精度更高的原因是,它能够捕捉 Query 和 Document 之间的细粒度交互——注意力机制可以在两个序列之间建立 Token 级别的关联,而不是像 Bi-Encoder 那样先各自压缩成固定维度的向量再进行比较。
Rerank 的性能考量
由于 Cross-Encoder 需要实时计算每一对 (Query, Document) 的分数,其计算复杂度为 O(N),其中 N 是候选文档的数量。因此,Rerank 通常只作用于 Hybrid 召回后的 Top K(例如 K=20-50)候选集,而非全量文档库。
典型的 RAG 检索流水线:
Query → [BM25 召回 Top 50] → 并行→ [Vector 召回 Top 50] → RRF 融合 → Top 20 → Cross-Encoder Rerank → Top 5 → Prompt
判断 Checklist
在评估一个 RAG 系统的 Hybrid 检索方案时,可以使用以下 Checklist 逐项检查:
- 是否优先使用 RRF 而非分数加权进行合并?
- 是否具备 Query Classifier,能将不同类型的 Query 路由到不同的通道权重?
- 通道权重是基于检索参与度而非分数权重?
- Hybrid 之后是否还会经过 Cross-Encoder Rerank?
- 调参所使用的回归集是否包含失败样例(Bad Case)而非随机抽样?
- 评估指标是否同时考虑分类准确率,而不仅仅是整体平均值?
常见陷阱总结
| 陷阱 | 问题 | 修复方案 |
|---|---|---|
0.5*BM25 + 0.5*Vector | 尺度相差多个数量级 | 改用 RRF 合并排名 |
| 简单 Min-Max 归一化就当作对齐 | 同名不同义,归一化后排序混乱 | 使用 RRF 或 Cross-Encoder 重新打分 |
| 所有 Query 使用相同权重 | 硬性 Token 类的优势被语义类拖低 | 编写 Query 分类器进行通道划分 |
| 根据整体平均值调整权重 | 尾部 Case 未改善却误以为成功 | 使用 Bad Case 回归集,按类型评估 |
落地建议
根据系统所处的阶段,有以下不同的落地策略:
已经使用分数加法的团队:先将合并算法切换为 RRF,这几乎零成本,能立刻看到改善;然后再增加一个轻量级的 Query 分类器,按类型划分通道。
尚处原型阶段的团队:直接以 RRF 起步,路由功能可以先不做。等积累足够多的线上 Query 日志后,再分析哪些类型的 Query 在单路下表现不佳,并有针对性地补充路由规则。
面试表达:将“Hybrid 调的不是分数权重”作为一个分水岭观点,再把 Query 路由、RRF、Bad Case 这三层串联起来讲解,足以展示你的理解深度。
总结
Hybrid 检索的核心洞见可以归结为一句话:BM25 和 Vector 的分数不在一个量级,直接加权是常见的教程式陷阱。
正确的落地路径是:
- 起步使用 RRF——只看排名,免疫尺度差异。
- 编写一个 Query Classifier——将硬性 Token / 语义 / 混合类型的 Query 分开,走不同的通道权重。
- Hybrid 之后必须进行 Rerank——Cross-Encoder 精排确保最相关的内容排在最前面。
- 调参权重应关注 Bad Case,而非平均指标——Hybrid 的真实价值体现在尾部 Case,整体均值变化容易产生误导。
在工程实践中,这套方法论已在多个 RAG 场景中得到验证。错误码类 Query 的准确率可以从 52% 提升到 93%,自然语言描述类从 74% 提升到 88%,整体从 66% 提升到 90%——而这一切只需要调整检索策略,无需更换 Embedding 模型或重新切分文档。
下次再遇到 Hybrid 面试题时,建议不要急着报权重;先问 Query 类型、合并算法和 Bad Case——这三个问题能把“会调参”和“只会套公式”的人区分开来。
延伸阅读
- BM25 算法详解 — BM25 的数学原理和参数含义
- Reciprocal Rank Fusion 论文 — RRF 的原始论文
- Cross-Encoder 对比 Bi-Encoder — Sentence-Transformers 的 Retrieve & Rerank 示例
- LangChain Hybrid Search 文档 — 主流框架中的 Hybrid Search 实现




