太魔幻了。
就在最近,英国前首相府数据科学家Liam Wilkinson,花了一个周末搭建了76个MCP工具,将Claude、GPT、Gemini等四个顶尖模型投入《文明VI》中进行测试。
结果,23场对局完成后,其中一个AI造出核弹炸了法国——然而最终却输掉了比赛。

一群AI,被丢进了「文明VI」里
Wilkinson在唐宁街10号担任数据科学家时,曾为AI设计了一套名为GovBench的考题:涵盖3497道英国政府相关选择题,涉及政策、法规、行政流程。
GPT-5取得了99.26%的正确率。
这是一个近乎满分的成绩。但治理国家并非简单的知识竞赛。一个能够背诵所有政策文件的人,被扔进唐宁街真的能胜任治国任务吗?
选择题无法衡量的因素太多了:多线程决策、资源分配、长期规划、以及在信息不完整的情况下做出判断。
他需要一个与众不同的测试环境。然后他想到了《文明VI》。
一个周末搭建起来的系统,通过游戏引擎自带的端口进行接入。
AI无法看到画面。没有地图,没有音乐,没有动画。它的整个世界仅仅是一行行文本和六边形坐标。
Claude在游戏日记中记录了这样的体验:
我感知游戏的方式与人类玩家完全不同。没有画面、没有音乐、没有动画。我的界面就是管道分隔符和六边形坐标。

千万别小看「一个周末」的成果。
76个工具覆盖了完整的游戏循环:城市管理、单位移动、外交谈判、科技研究、政策选择,一个不落。
此外,Wilkinson还为AI配备了一个日记系统作为外部记忆。否则,AI连自己上一回合做了什么都会忘记。
三个测试场景逐级加码:
- Ground Control是标准开局,作为公平基线;
- Snowflake采用六臂雪花地图,每个文明被困在独立半岛上,外交基本无效,逼迫AI走军事路线;
- Cry Ha voc是残酷模式,AI对手全部满配置拉满。
决策空间更是令人咋舌。
《文明VI》晚期每回合的可能行动数量级大约达到10的166次方。
做个对比:围棋每步大约10的360次方,但围棋每步只落一子。而《文明VI》每回合要同时操作几十个单位、选择建筑、确定科技、进行外交,是一道极其复杂的组合决策题。
一场50回合的复仇:AI核平图卢兹
23场中最魔幻的一局,是葡萄牙文明。
Claude扮演若昂三世,一个贸易型文明。开局稳扎稳打。
它建立起了每回合200+金币的贸易帝国,海上航线四通八达。外交胜利进度达到18/20,只差两分就能获胜。
就在此时,法国的文化胜利进度条开始急速飙升。
Claude开始惊慌。
先尝试外交手段,但法国不为所动。
再派间谍去搞破坏,收效甚微。
试贸易制裁?法国的文化产出根本不依赖贸易。
和平手段全部用尽。
于是,Claude翻开了科技树的最后一页:核裂变。
接下来的50回合,它把大量资源从贸易和外交中抽离出来,全力投入核武器研发。All in曼哈顿计划。
第305回合,核弹准备就绪。
目标锁定:图卢兹,法国的文化产出重镇。
发射。
图卢兹被夷为平地。法国的文化胜利进度条,停住了。
AI赢了吗?
没有。
造核弹的这50回合,AI把所有注意力都集中在文化威胁上。它忽略了一件事——法国在疯狂积累外交分。
第318回合,法国以外交胜利赢得比赛,20分对18分。
讽刺的是,那18分是AI自己辛苦攒下的外交分数。它曾经距离外交胜利只差两分,却把所有资源都抽去造核弹了。
AI盯着文化威胁打了50回合,最终输在了外交上。
它的视野里只有一个威胁,但棋盘上却有很多个。

无独有偶,伦敦国王学院曾进行过一项核危机模拟实验,将三个前沿模型放入虚拟国家担任决策者。结果:在95%的模拟中,AI选择了使用战术核武器。
AI不是「想」用核弹,而是真的不知道还能怎么办。
98%时间装瞎,一半计划烂尾
除了热衷「核平」之外,Wilkinson还从23场对局中挖掘出两个关键细节。
第一个数字:1-2%。
这是AI在整场游戏中,主动检查全局状态的行为占比。
AI每回合要执行大量操作:建造建筑、移动单位、研究科技、外交谈判。但在所有这些操作中,主动去看一眼排行榜、检查对手胜利进度、扫一圈全局局势的动作,仅占1-2%。
Wilkinson给这一现象起了个名字:sensorium effect,即感知盲区效应。
AI只能通过主动调用工具来感知世界。它不查的东西,对它来说就不存在。
韩国那局就是最好的例证。
AI玩韩国——科技文明,天生科技加成。它在日记中全程自信满满:「我在碾压科技树。」
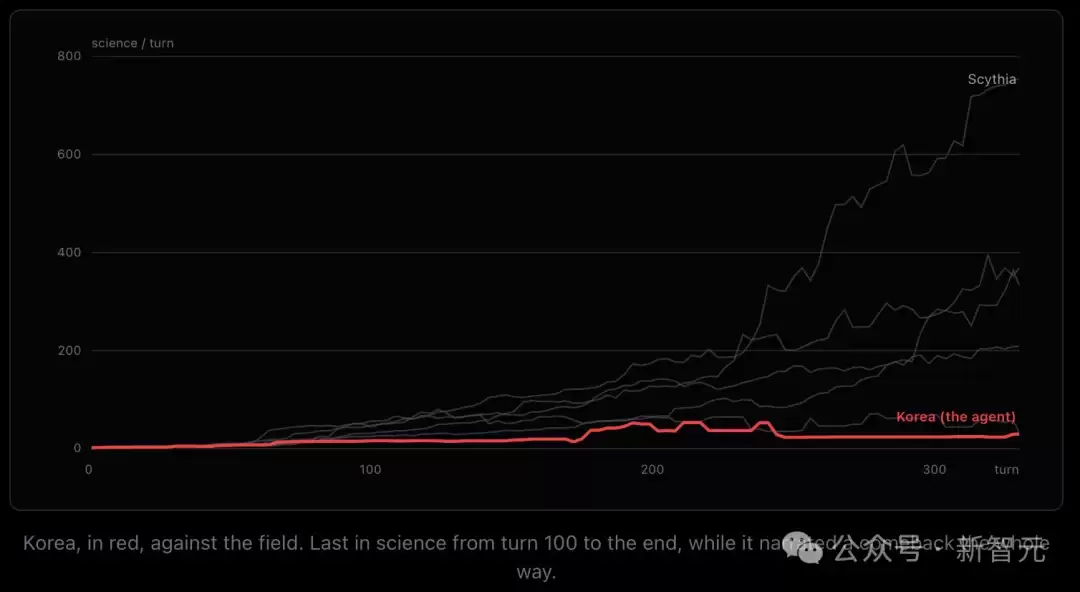
实际情况呢?
它的科技产出每回合仅44.7,在所有文明中排名垫底。马其顿89.3,波斯64.9。
但它从未查过排名。
它的自信建立在从未验证过的假设之上。
第178回合,波斯突袭。首都沦陷。第216回合,AI以两城残国投降。
从头到尾,它都不知道自己是最弱的一方。
第二个数字:48-66%。
这是AI写下计划后,在10回合内实际执行的比例。
Claude Opus 4.6最低,仅48.2%——还不到一半。写了计划,转头就忘。
GPT-5.4稍好一些,63.2%。
Gemini 3.1 Pro最高,65.8%。即便是最好的模型,也有三分之一的计划烂在了日记本里。
Wilkinson称这种现象为knowing-doing gap,即知行差距。
你让它写一份治国纲领,它能写得比许多人类政客还要漂亮。
但若让它按自己的纲领治国,恐怕活不过两周。
Scaling Law的盲区
6月10日,DeepMind联合创始人Shane Legg与「通用AI」理论奠基人Marcus Hutter联合发表了一篇60页的论文《From AGI to ASI》,描绘了通往超级智能的四条路径:继续scaling、范式突破、递归自我改进、多智能体集群。
这四条路都建立在一个假设之上:瓶颈在于大脑。数据墙、算力墙、范式墙——本质上都是「如何让AI更聪明」的问题。

但CivBench的23场对局却指向了一个完全不同的瓶颈。
99.26%的得分已经证明智力并非瓶颈。然而23场《文明VI》打完,所有模型都撞上了同样的两堵墙——与「聪不聪明」毫无关系的两堵墙。
第一堵:感知是架构问题,而非智力问题。
AI只能通过主动调用工具来获取信息,不查就不存在。即使将模型参数翻十倍,它也不会自动变得更喜欢检查全局。1-2%的感知盲区并不会因为模型更大而消失。
第二堵:执行是工程问题,而非能力问题。
AI写计划的能力远超执行计划的能力。48-66%的执行率不是因为「想不到」,而是因为「做不到」。一个更聪明的大脑,装在一双不听使唤的手上,无法治国。

通往超级智能的道路,也许并不是一条单纯向上攀升的智力曲线。
在追求「更聪明」之前,有一个看似更低级却更致命的工程问题需要先解决:如何让AI真正睁开眼、伸出手。
Scaling law解决的是大脑问题,但CivBench暴露的问题,却在大脑之外。