说实话,现在市面上的图像生成模型确实不少,各有各的绝活。但OmniGen算是少数让人眼前一亮的工作之一。它来自北京市人工智能研究院,主打一个“统一”——一个模型,包揽文生图、主题驱动生成、身份保留、图像编辑、图像条件生成等任务。更关键的是,它不需要你额外设载任何插件,也不用操心什么预处理步骤。你只需要给一段文本提示,模型自己就能从输入图像里识别出关键特征,比如想要的对象、人体姿势、深度映射——一步到位,省心省力。
概述
OmniGen的设计思路很直接:一个模型,根据多模态提示,生成各种图像。它简单、灵活,而且容易上手。作者已经把推理代码公开了,方便大家去探索更多可能性。
细想一下,现有的图像生成模型,要实现理想效果,往往得走一大串流程:加装ControlNet、IP-Adapter、Reference-Net这些额外网络模块,还得先做人脸检测、姿势估计、裁剪等预处理。这实在太繁琐了。未来的图像生成范式应该更简单、更灵活——直接通过任意的多模态指令生成图像,不需要任何额外插件和操作。这就像一个专门干图像生成的GPT。
当然,受限于资源,OmniGen还有改进空间。但团队会持续优化它,也希望这个工作能启发更多通用的图像生成模型。更重要的是,你可以轻松地微调OmniGen,不用为特定任务专门设计网络结构。准备好数据,跑个脚本就行。这意味着想象力将不再受限——每个人都能构造任何图像生成任务,玩出一些非常有趣、奇妙甚至富有创意的事情。

OmniGen 能做什么?
那OmniGen到底能干啥?一句话:它从文本到图像、主题驱动、身份保留、图像编辑到图像条件生成,几乎包圆了。而且全程不需要额外插件或操作。你只需要用文本提示,模型就能自动识别输入图像中的特征——是哪个对象、什么姿势、深度如何,它自己判断。
下面是它的功能演示:你可以通过OmniGen灵活控制图像生成。

引用表情生成
输入多幅图像,用简单通用的语言引用图像中的对象,OmniGen就能自动识别每幅图像里需要的对象,并生成新图像。整个过程不需要进行图像裁剪或人脸检测等额外操作。

方法
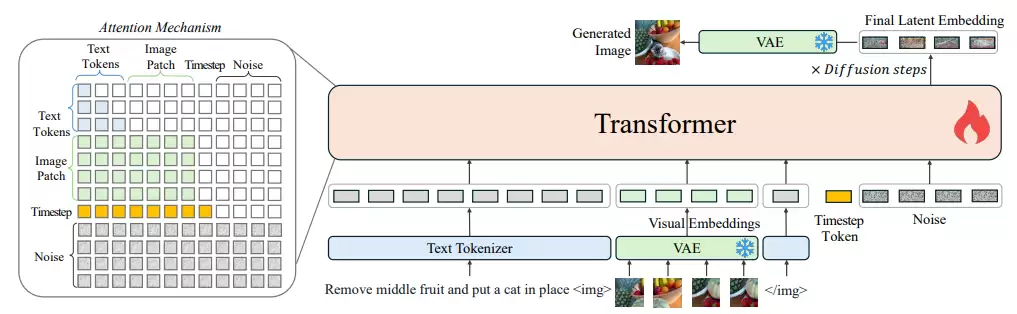
OmniGen 的框架
文本被标记为token,输入图像通过VAE转换为嵌入。OmniGen可以接受自由形式的多模态提示,并通过整流方法生成图像。

OmniGen 模型训练数据示例
所有任务的输入被标准化为任意交错的图像文本序列格式,用作模型的提示。占位符|image_i|表示提示中第i个图像的位置。

(a)GRIT-Entity数据集的构建过程说明:使用实例分割和重绘方法来获取大量数据。(b)构建网络图像数据集时使用的交叉验证策略说明:对于人物A和人物B的合影,从人物A和人物B的单张照片中抽取几张图像,并询问MLLM他们是否出现在合影中。只有当人物A和人物B的“是”比例都达到特定阈值时,才会保留合影。然后使用标记为“是”的单张图像与相应的组图像构建数据对。
更多结果展示

文本生成图像的结果

主题驱动生成的结果
OmniGen可以根据参考图像中的对象生成新图像。当参考图像包含多个对象时,它可以根据文本指令自动识别需要引用的对象。
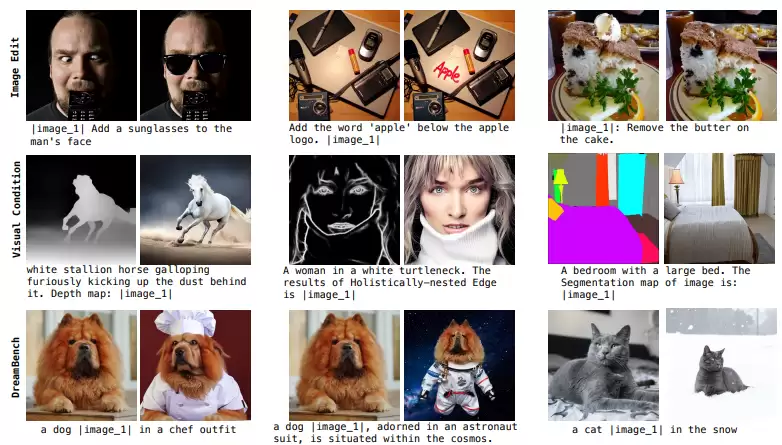
OmniGen在不同图像生成任务中的表现。
OmniGen在传统视觉任务上的表现。