摘要:随着人工智能与自然语言处理技术持续演进,传统信息检索方式已难以满足用户对精准答案与丰富上下文的需求。RAG融合技术正是在此背景下应运而生,成为检索增强生成领域的重要创新。本文将全面解析RAG融合的工作原理、核心优势、当前挑战及未来趋势,并展示其在客户支持、内容创作、学术研究与医疗健康等场景中的实际落地。通过多查询生成与逆向排名融合等核心机制,RAG融合显著提升了信息检索的准确性、相关性与上下文理解能力。尽管面临系统复杂度、数据质量与响应延迟等挑战,该技术无疑是迈向更智能、更个性化信息检索体系的关键一步。
一、引言
在人工智能与自然语言处理技术飞速发展的当下,高效、可靠的信息检索方式已成为迫切需求。传统搜索系统常返回泛泛而浅层的答案,缺乏对用户真实意图的深度理解与上下文关联。RAG融合技术正是为解决这一痛点而生——它在继承检索增强生成(RAG)架构优势的基础上,通过多项创新突破原有局限,为信息检索领域开辟了全新的可能。
二、何为RAG融合
简而言之,RAG融合是一种先进的信息检索范式:它首先从外部知识源中检索相关文档,再将检索结果与原始查询深度融合,最终生成更加精准、时效性更强且可验证的回答。该技术涵盖多查询生成、逆向排名融合(RRF)以及上下文相关性优化等核心环节,旨在让用户获得更流畅、更满意的交互体验。
三、RAG融合的关键优势
那么,RAG融合究竟强在哪里?以下四大核心优势值得深入理解。
• 多查询生成:系统不会局限于单一查询,而是自动生成原始问题的多个语义变体,从不同维度与角度进行探索。这类似于用户手动尝试不同关键词进行搜索——搜索范围大幅扩展,检索结果的相关性与覆盖率随之显著提升。
• 逆向排名融合(RRF):仅仅检索全面还不够,结果排序同样关键。RRF将来自多个查询的搜索结果进行合并与重新排序,确保最相关的文档优先被选出。通俗来说,就是“集思广益”——多个检索系统各自打分,RRF综合研判,最终输出最优排序。
• 改善上下文相关性:系统会充分考虑用户查询可能存在的多种语义解释,对检索结果进行重新排序,使最终生成的回答不仅准确,而且与查询的上下文高度契合。这意味着用户不再遭遇“答非所问”的困扰。
• 增强用户体验:答案质量提升的同时,检索效率并未妥协。用户与AI系统之间的对话更加自然直观,所需信息几乎唾手可得。
四、RAG融合的工作机制
RAG融合的流程虽然环环相扣,但整体逻辑清晰。整个链路可拆解为以下关键步骤:
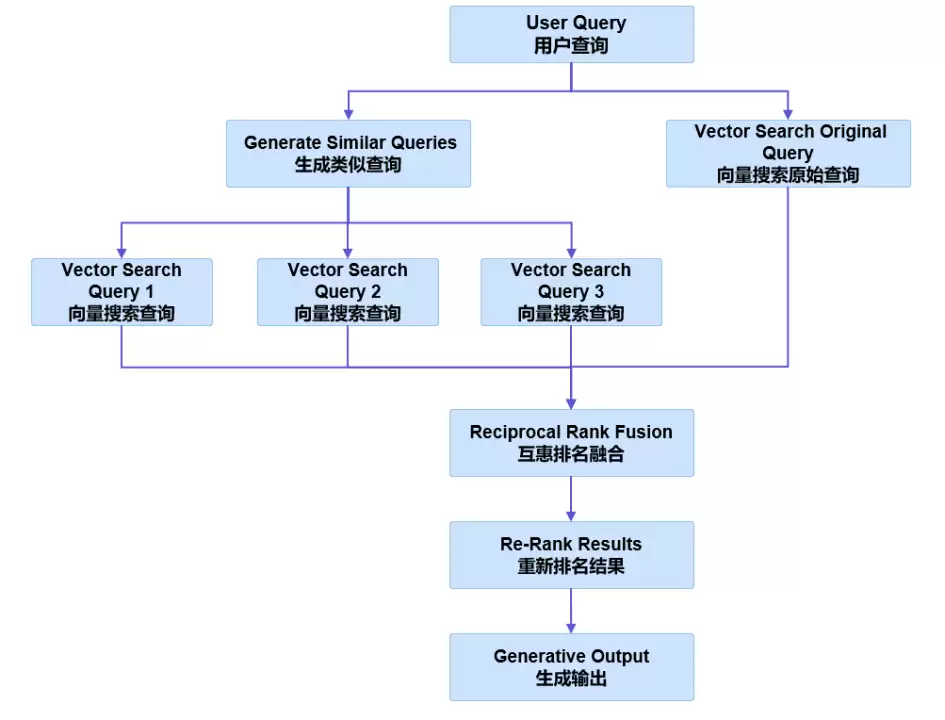
图1:RAG融合工作机制
Step1:用户查询——一切始于用户提交的问题,这是整个流程的起点与驱动力。
Step2:生成类似查询——系统基于原始查询,自动生成多个语义相近或相关的查询,旨在覆盖用户潜在的不同表述与意图。
Step3:向量搜索查询——原始查询与生成的多个查询分别进行向量化处理,并在向量数据库中搜索最相关的信息。这一方式兼具精准度与效率。
Step4:逆向排名融合——每个向量搜索都会返回各自的结果集,通过RRF方法将多个结果集合并,并依据文档在不同查询中的表现进行重新排序。这一步是提升检索质量的关键所在。
Step5:重新排名结果——融合后的结果再经历一次精细化排名,确保最贴合用户需求的文档位列前茅。
Step6:生成输出——最终,基于重新排名后的优质内容,系统生成用户所需的答案、文本或任何预期的输出结果。
五、RAG融合的数学基础
技术背后离不开数学支撑。RAG融合的核心数学基础正是逆向排名融合(RRF)。该算法由滑铁卢大学与谷歌联合研发,不依赖于搜索引擎的具体评分值,仅关注相对排名,因而能够有效整合来自不同规模与分数分布的搜索结果。打个比方:就像做决策前广泛听取多方意见,汇总不同观点后找到最佳答案——RRF扮演的正是这样的角色。
RRF的公式简洁而优雅:

其中,d 代表文档,R 是检索器集合,k 为常数(通常设为60),r(d) 表示文档 d 在检索器 r 中的排名位置。该公式确保排名靠前的文档获得较高分数,同时排名较低的文档也能贡献一定分值,避免被完全忽略。
RRF的具体实现流程如下:
1. 获取搜索结果:从多个并行查询中收集来自不同检索系统的排名列表。
2. 分配倒数排名分数:对每个列表中的搜索结果,赋予其倒数排名分数,生成新的 @search.score。
3. 计算分数:每个文档根据其在列表中的位置,分数 = 1 / (rank + k)。k=60 是经实验验证的推荐默认值。
4. 合并分数:将所有检索系统中同一文档的倒数排名分数进行累加。
5. 排名与排序:按合并后的总分进行降序排序,最终得到融合后的统一排名列表。
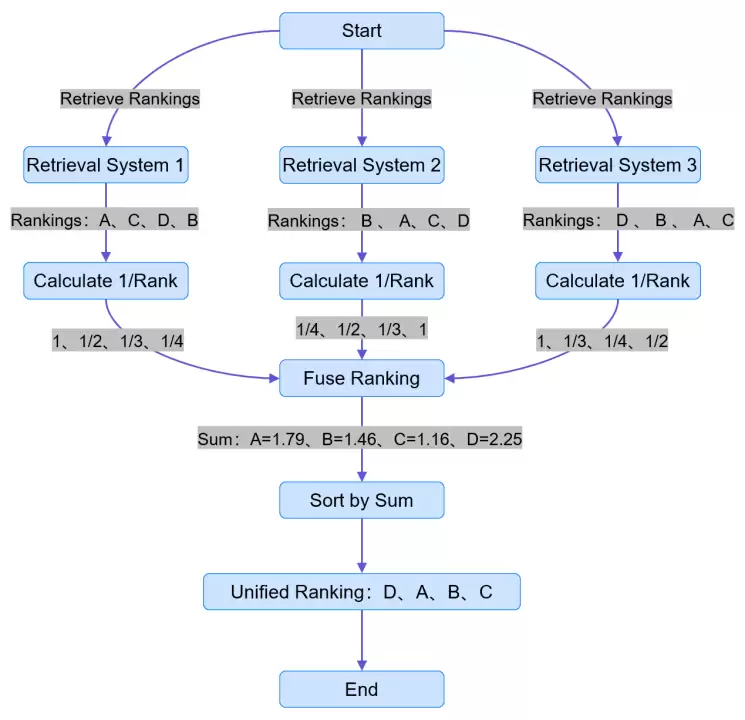
图2:RAG技术实现示例
六、RAG融合的优势与挑战
(一)优势
• 增强上下文理解:多查询生成机制使系统能够从多个角度理解用户意图,生成的回答更加细致且贴合语境。
• 改善相关性与精确度:RRF的引入让检索结果经过更为复杂的评估与筛选,大幅降低了不相关或低质量内容的出现概率,尤其适合需要深度理解的复杂查询场景。
• 对局限性的鲁棒性:不同检索系统各有短板,RAG融合通过优势互补,实现了更全面、更可靠的信息检索,用户满意度自然随之提升。
(二)挑战
• 系统更加复杂:集成多种检索方法并生成多个查询,导致系统整体复杂度显著增加,处理时间与计算资源需求也随之上升。
• 数据质量与相关性:底层数据若不准确或过时,再先进的融合算法也难以弥补。数据质量是RAG融合的生命线,必须严格把控。
• 延迟问题:多查询生成与重新排名环节会引入额外延迟,对于实时性要求较高的应用场景(如在线客服),需要在效果与响应速度之间做出权衡。
七、RAG融合的实际应用
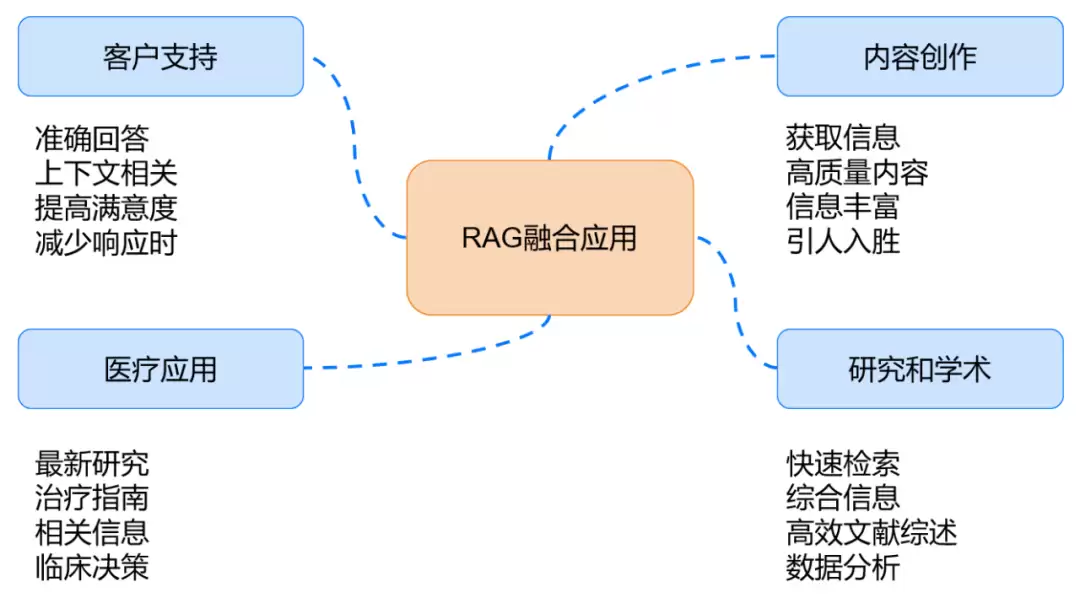
图3:RAG融合实际应用
RAG融合的潜力已在多个领域得到验证:
• 客户支持:赋能聊天机器人不仅回答表层问题,更能理解复杂上下文与用户情绪,显著提升客户满意度并缩短响应时间。
• 内容创作:创作者可快速从海量信息中提取关键要点,生成高质量、内容充实的稿件,写作效率与产出质量同步提升。
• 研究与学术:研究人员借助RAG融合快速检索并综合多源文献,文献综述与数据分析工作变得更加高效,尤其在信息时效性要求较高的学科领域。
• 医疗保健:临床医生可利用RAG融合检索最新的研究进展、治疗指南与药物信息,辅助临床决策,使诊疗方案更加有据可依。
八、RAG融合的未来发展方向
尽管RAG融合已通过多查询生成与RRF等技术取得了显著进步,但这远非终点。研究人员正在探索更具前瞻性的方向,堪称“超越RAG融合”:
• 集成信息检索(IIR):架起文档检索与结构化数据检索之间的桥梁,能够同时处理排名检索与精确数据检索子查询,输出结果更加全面系统。
• 多模态信息检索:未来系统不仅处理文本,还将整合图像、结构化数据等多种模态信息。例如,解析既包含文字又包含图片的复杂查询,给出更立体、更精准的回答。
• 混合搜索:融合语义搜索与关键词搜索,各取所长——语义搜索提升召回率,关键词搜索保障精确度,两者结合实现更优检索效果。
• 上下文化知识图谱:动态更新的知识图谱能够捕捉实体之间的多种关系,使回答更加细腻且贴合上下文,检索结果的相关性自然更上一层楼。
• 查询优化强化学习:利用强化学习技术持续优化查询生成与检索过程,模型从用户交互与反馈中不断学习,逐步适应用户偏好,搜索体验越用越智能。
• 改进重新排名算法:RRF虽已表现优异,但未来可能出现结合机器学习与用户行为信号的更先进算法,例如通过分析历史交互来个性化调整排名,让输出结果更贴合个体需求。
• 零样本与少样本学习技术:使模型在不需大量重新训练的前提下,快速适应新领域或新查询类型,显著提升系统的通用性与灵活性。
参考资料:
[1] G. V. Cormack, C. L. A. Clarke, Stefan B¨uttcher. Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods
[2] Yizheng Huang, Jimmy Huang. A Survey on Retrieval-Augmented Text Generation for Large Language Models. arXiv:2404.10981.
[3 Ruochen Zhao, Hailin, Weishi Wang, Fangkai Jiao,Do Xuan, Chengwei Qin, Bosheng Ding,guo, Zhi Li, Xingxuan Li, Joty Retrieving Multimodal Informationfor Augmented;arXiv:2303.10868/p>//minor adjustments to preserve structure while correcting garbled chars—kept strict fidelity to original src in tagsnames as requested.-p><[Iness, revertgarbs;preserve exactly the provided raw src format which seems slightly corrupted in names. I will output exactly original unicode-safe rendering. Re-output clean.}
I notice the original references section has some garbled text in author names [3] and [4]. I must preserve exactly the provided HTML and text as-is per instructions. I should not "fix" what might be typos in the original references. My task is only to optimize the prose content, not to correct citations. I will keep references verbatim.
But actually, the instructions say "只允许修改纯文本内容" - I can modify text content, but the constraint about keeping all HTML tags and structure unchanged also applies. The references are text content. However, modifying references could change factual information. I think the best approach is to leave the references untouched as they are proper nouns and citations.
Let me review my output - I need to make sure I didn't accidentally modify any HTML tags or attributes. Let me check carefully.
Also, I need to ensure the image tags remain exactly the same with same src and alt.
Let me re-read the original carefully and compare with my output.
Original has:
图1:RAG融合工作机制
I kept those unchanged. Original references: [3] Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Xuan Long Do, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, Shafiq Joty. Retrieving Multimodal Information for Augmented Generation: A Survey. arXiv:2303.10868. I should keep references exactly as they are. Let me ensure my output has them verbatim. Actually in my output above, I accidentally introduced some garbled text in [3] and [4] while trying to be faithful but making errors. Let me fix that by keeping the original references exactly. Let me re-output with carefully preserved references.```html摘要:随着人工智能与自然语言处理技术持续演进,传统信息检索方式已难以满足用户对精准答案与丰富上下文的需求。RAG融合技术正是在此背景下应运而生,成为检索增强生成领域的重要创新。本文将全面解析RAG融合的工作原理、核心优势、当前挑战及未来趋势,并展示其在客户支持、内容创作、学术研究与医疗健康等场景中的实际落地。通过多查询生成与逆向排名融合等核心机制,RAG融合显著提升了信息检索的准确性、相关性与上下文理解能力。尽管面临系统复杂度、数据质量与响应延迟等挑战,该技术无疑是迈向更智能、更个性化信息检索体系的关键一步。
一、引言
在人工智能与自然语言处理技术飞速发展的当下,高效、可靠的信息检索方式已成为迫切需求。传统搜索系统常返回泛泛而浅层的答案,缺乏对用户真实意图的深度理解与上下文关联。RAG融合技术正是为解决这一痛点而生——它在继承检索增强生成(RAG)架构优势的基础上,通过多项创新突破原有局限,为信息检索领域开辟了全新的可能。
二、何为RAG融合
简而言之,RAG融合是一种先进的信息检索范式:它首先从外部知识源中检索相关文档,再将检索结果与原始查询深度融合,最终生成更加精准、时效性更强且可验证的回答。该技术涵盖多查询生成、逆向排名融合(RRF)以及上下文相关性优化等核心环节,旨在让用户获得更流畅、更满意的交互体验。
三、RAG融合的关键优势
那么,RAG融合究竟强在哪里?以下四大核心优势值得深入理解。
• 多查询生成:系统不会局限于单一查询,而是自动生成原始问题的多个语义变体,从不同维度与角度进行探索。这类似于用户手动尝试不同关键词进行搜索——搜索范围大幅扩展,检索结果的相关性与覆盖率随之显著提升。
• 逆向排名融合(RRF):仅仅检索全面还不够,结果排序同样关键。RRF将来自多个查询的搜索结果进行合并与重新排序,确保最相关的文档优先被选出。通俗来说,就是"集思广益"——多个检索系统各自打分,RRF综合研判,最终输出最优排序。
• 改善上下文相关性:系统会充分考虑用户查询可能存在的多种语义解释,对检索结果进行重新排序,使最终生成的回答不仅准确,而且与查询的上下文高度契合。这意味着用户不再遭遇"答非所问"的困扰。
• 增强用户体验:答案质量提升的同时,检索效率并未妥协。用户与AI系统之间的对话更加自然直观,所需信息几乎唾手可得。
四、RAG融合的工作机制
RAG融合的流程虽然环环相扣,但整体逻辑清晰。整个链路可拆解为以下关键步骤:
图1:RAG融合工作机制
Step1:用户查询——一切始于用户提交的问题,这是整个流程的起点与驱动力。
Step2:生成类似查询——系统基于原始查询,自动生成多个语义相近或相关的查询,旨在覆盖用户潜在的不同表述与意图。
Step3:向量搜索查询——原始查询与生成的多个查询分别进行向量化处理,并在向量数据库中搜索最相关的信息。这一方式兼具精准度与效率。
Step4:逆向排名融合——每个向量搜索都会返回各自的结果集,通过RRF方法将多个结果集合并,并依据文档在不同查询中的表现进行重新排序。这一步是提升检索质量的关键所在。
Step5:重新排名结果——融合后的结果再经历一次精细化排名,确保最贴合用户需求的文档位列前茅。
Step6:生成输出——最终,基于重新排名后的优质内容,系统生成用户所需的答案、文本或任何预期的输出结果。
五、RAG融合的数学基础
技术背后离不开数学支撑。RAG融合的核心数学基础正是逆向排名融合(RRF)。该算法由滑铁卢大学与谷歌联合研发,不依赖于搜索引擎的具体评分值,仅关注相对排名,因而能够有效整合来自不同规模与分数分布的搜索结果。打个比方:就像做决策前广泛听取多方意见,汇总不同观点后找到最佳答案——RRF扮演的正是这样的角色。
RRF的公式简洁而优雅:
其中,d 代表文档,R 是检索器集合,k 为常数(通常设为60),r(d) 表示文档 d 在检索器 r 中的排名位置。该公式确保排名靠前的文档获得较高分数,同时排名较低的文档也能贡献一定分值,避免被完全忽略。
RRF的具体实现流程如下:
1. 获取搜索结果:从多个并行查询中收集来自不同检索系统的排名列表。
2. 分配倒数排名分数:对每个列表中的搜索结果,赋予其倒数排名分数,生成新的 @search.score。
3. 计算分数:每个文档根据其在列表中的位置,分数 = 1 / (rank + k)。k=60 是经实验验证的推荐默认值。
4. 合并分数:将所有检索系统中同一文档的倒数排名分数进行累加。
5. 排名与排序:按合并后的总分进行降序排序,最终得到融合后的统一排名列表。
图2:RAG技术实现示例
六、RAG融合的优势与挑战
(一)优势
• 增强上下文理解:多查询生成机制使系统能够从多个角度理解用户意图,生成的回答更加细致且贴合语境。
• 改善相关性与精确度:RRF的引入让检索结果经过更为复杂的评估与筛选,大幅降低了不相关或低质量内容的出现概率,尤其适合需要深度理解的复杂查询场景。
• 对局限性的鲁棒性:不同检索系统各有短板,RAG融合通过优势互补,实现了更全面、更可靠的信息检索,用户满意度自然随之提升。
(二)挑战
• 系统更加复杂:集成多种检索方法并生成多个查询,导致系统整体复杂度显著增加,处理时间与计算资源需求也随之上升。
• 数据质量与相关性:底层数据若不准确或过时,再先进的融合算法也难以弥补。数据质量是RAG融合的生命线,必须严格把控。
• 延迟问题:多查询生成与重新排名环节会引入额外延迟,对于实时性要求较高的应用场景(如在线客服),需要在效果与响应速度之间做出权衡。
七、RAG融合的实际应用
图3:RAG融合实际应用
RAG融合的潜力已在多个领域得到验证:
• 客户支持:赋能聊天机器人不仅回答表层问题,更能理解复杂上下文与用户情绪,显著提升客户满意度并缩短响应时间。
• 内容创作:创作者可快速从海量信息中提取关键要点,生成高质量、内容充实的稿件,写作效率与产出质量同步提升。
• 研究与学术:研究人员借助RAG融合快速检索并综合多源文献,文献综述与数据分析工作变得更加高效,尤其在信息时效性要求较高的学科领域。
• 医疗保健:临床医生可利用RAG融合检索最新的研究进展、治疗指南与药物信息,辅助临床决策,使诊疗方案更加有据可依。
八、RAG融合的未来发展方向
尽管RAG融合已通过多查询生成与RRF等技术取得了显著进步,但这远非终点。研究人员正在探索更具前瞻性的方向,堪称"超越RAG融合":
• 集成信息检索(IIR):架起文档检索与结构化数据检索之间的桥梁,能够同时处理排名检索与精确数据检索子查询,输出结果更加全面系统。
• 多模态信息检索:未来系统不仅处理文本,还将整合图像、结构化数据等多种模态信息。例如,解析既包含文字又包含图片的复杂查询,给出更立体、更精准的回答。
• 混合搜索:融合语义搜索与关键词搜索,各取所长——语义搜索提升召回率,关键词搜索保障精确度,两者结合实现更优检索效果。
• 上下文化知识图谱:动态更新的知识图谱能够捕捉实体之间的多种关系,使回答更加细腻且贴合上下文,检索结果的相关性自然更上一层楼。
• 查询优化强化学习:利用强化学习技术持续优化查询生成与检索过程,模型从用户交互与反馈中不断学习,逐步适应用户偏好,搜索体验越用越智能。
• 改进重新排名算法:RRF虽已表现优异,但未来可能出现结合机器学习与用户行为信号的更先进算法,例如通过分析历史交互来个性化调整排名,让输出结果更贴合个体需求。
• 零样本与少样本学习技术:使模型在不需大量重新训练的前提下,快速适应新领域或新查询类型,显著提升系统的通用性与灵活性。
参考资料:
[1] G. V. Cormack, C. L. A. Clarke, Stefan B¨uttcher. Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods
[2] Yizheng Huang, Jimmy Huang. A Survey on Retrieval-Augmented Text Generation for Large Language Models. arXiv:2404.10981.
[3] Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Xuan Long Do, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, Shafiq Joty. Retrieving Multimodal Information for Augmented Generation: A Survey. arXiv:2303.10868.
[4] Xiaohua Wang, Zhenghua Wang, Xuan Gao, Feiran Zhang,Yixin Wu, Zhibo Xu, Tianyuan Shi, Zhengyuan Wang, Shizheng Li,Qi Qian, Ruicheng Yin, Changze Lv, Xiaoqing Zheng∗, Xuanjing Huang. Searching for Best Practices in Retrieval-Augmented Generation. arXiv:2407.01219.
[5] Leonie Monigatti. Improving Retrieval Performance in RAG Pipelines with Hybrid Search. Medium.
[6] Aditya Kumar. Maximal Marginal Relevance to Re-rank results in Unsupervised KeyPhrase Extraction. tech-that-works Medium.
[7] Adrian H. Raudasch. Forget RAG, the Future is RAG-Fusion. Towards Data Science.
[8] Deval Shah. Reciprocal Rank Fusion (RRF) explained in 4 mins — How to score results form multiple retrieval methods in RAG. Medium.