RAG确实给不少企业和组织带来了实实在在的变化。把Gemini这类大模型的能力和你自己的数据一结合,能做出一些体验极其碘伏的应用。不过话又说回来,要想让RAG应用真正处理好那些结构复杂的非结构化文档——比如PDF,挑战依然不小。
这篇文章会介绍一项新技术,能把PDF里的文本精准提取出来,并转换成Markdown格式。对于提升RAG应用的准确性和上下文丰富度来说,这一步至关重要。
要注意的是,Markdown的价值远不止用于最终输出。你把它用在提示词里,效果会比纯文本好得多,因为它能传达更丰富的语义。这个思路很关键。
PDF的问题
PDF这玩意儿,大家都知道,处理起来有多头疼。每个文档的布局都可能千差万别:多列排版、文本像是随机散落在页面上,甚至有些页面看起来是文本,实际上一张图片。更别提那些表格数据,解析起来相当费劲。最后,想把PDF里的文本连同格式信息(比如加粗、斜体、项目符号)一起提取出来,难度极大。如果只提取纯文本,原始文档里的很多意义和细微差异就全丢了。
这些因素都让RAG应用在处理PDF时步履维艰。市面上有不少专门处理PDF的Python库,像PyPDF、PDFPlumber、PDFMiner,但能同时搞定上述所有复杂情况的,几乎没有。根据源文档的不同,这些库生成的结果要么不完整,要么干脆就是错的。
最近倒是有了一些新路子,比如用Docling这样的机器学习模型来解析PDF。但问题在于,它速度太慢,一旦PDF页数超过几页,基本就跑不动了——我之前在笔记本上测试过,处理一个12页的文档,Docling足足跑了18分钟。
所以,这篇文章要重点讨论一种新技术:借助Gemini和Google Cloud,快速、准确地读取PDF,并生成对应的Markdown。生成的Markdown非常适合直接喂给RAG数据存储进行索引。
关于Markdown的简要说明
Markdown是一种很轻量、很简洁的标记语言。它比HTML和CSS简单得多,专注于有限的几种样式元素:标题、加粗、斜体、超链接、项目符号和简单的表格。
Gemini这类大模型生成的输出,多数也是Markdown格式。它自带的样式对读者理解信息非常有帮助。用实际的项目符号列出来,显然比纯文本里那些行首的连字符要直观得多。加粗和斜体能让关键信息更突出。另外,Markdown把信息组织成表格的能力,也相当实用。
一个不太直观的点是,Markdown在构建提示词时同样好用。你可以有选择地突出提示中的关键词句,或者把信息整理成项目符号列表,这等于给模型提供了比纯文本更丰富的语义线索。模型理解能力上去了,也就更容易聚焦在你当前的任务上。
不过要清醒地认识到,Markdown本质上是一种简单的语言,它不一定能支持PDF里存储的所有内容。比如,Markdown表格不支持跨行或跨列,而这种格式在表格表头里很常见。在用这个新方法做测试时,这一点要牢记,因为它会影响你对某些PDF文件的提取准确度。
尽管有这些限制,能把PDF内容提取成Markdown,在处理RAG应用时确实非常有用。在分块和索引阶段,你可以利用标题来识别章节和小节,这就把文档分割成了离散的主题。同样,按Markdown表格排列的数据,也比纯文本更容易让模型理解。
总而言之,从PDF提取的Markdown能显著提升Gemini的响应质量,因为它比纯文本提供了更多的语义差异。而且,在RAG的吞吐过程中,Markdown还能帮你更好地分块文档——你可以用标题这类线索来检测文档中的逻辑部分。
理解了Markdown的价值,接下来就看怎么从PDF文档里把它提取出来。
如何从 PDF 中提取 Markdown
简单来说,核心流程分三步:
- PDF中的每一页,都需要单独处理:先生成这一页的图像,然后把这个图像传给Gemini,指示它把这页的内容提取为Markdown。
- 所有单独的页面都处理完后,把各页的Markdown合并成一个完整的Markdown字符串。
这个办法的效果很不错。我们用一个来自伊利诺伊州1040税表的页面来演示。注意看,这页被分成了两列,页面上下两部分是完全独立的:

下面是Gemini生成的对应Markdown,渲染后可以看到,项目符号、标题等等都应用得很好:
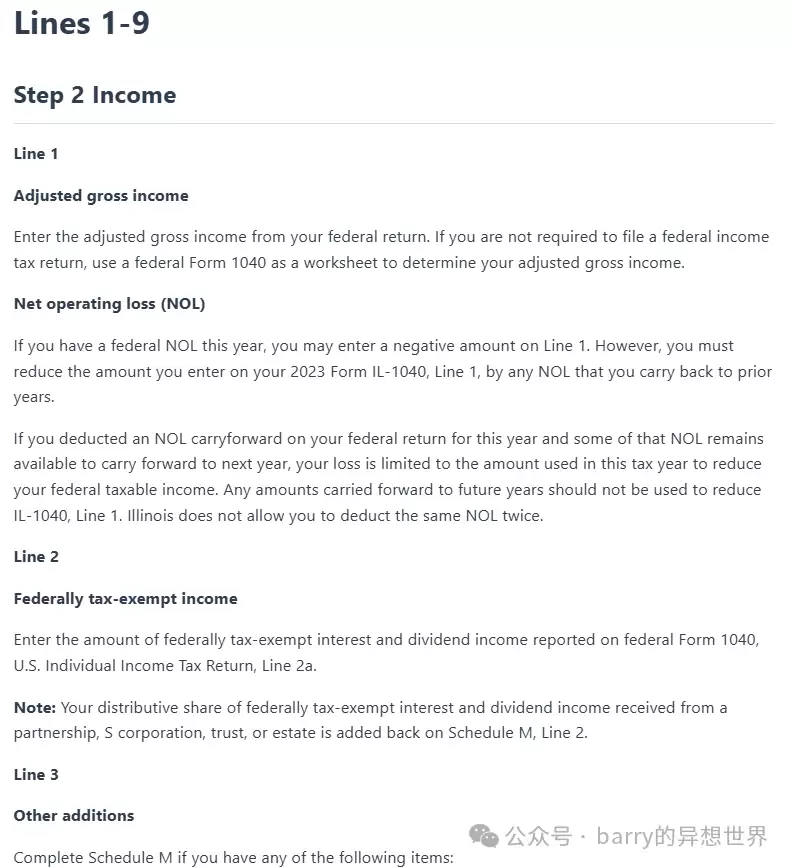
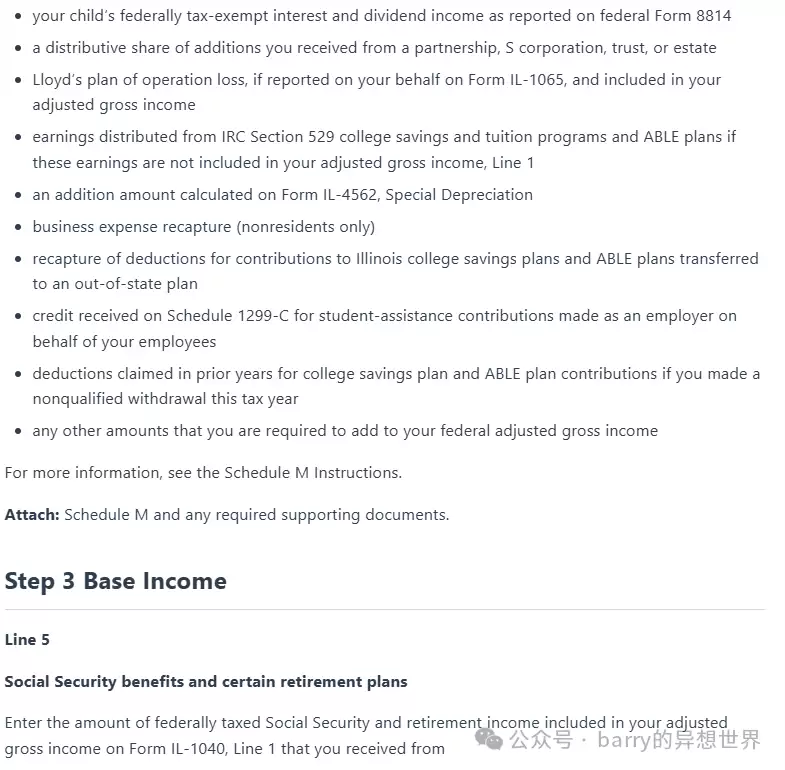
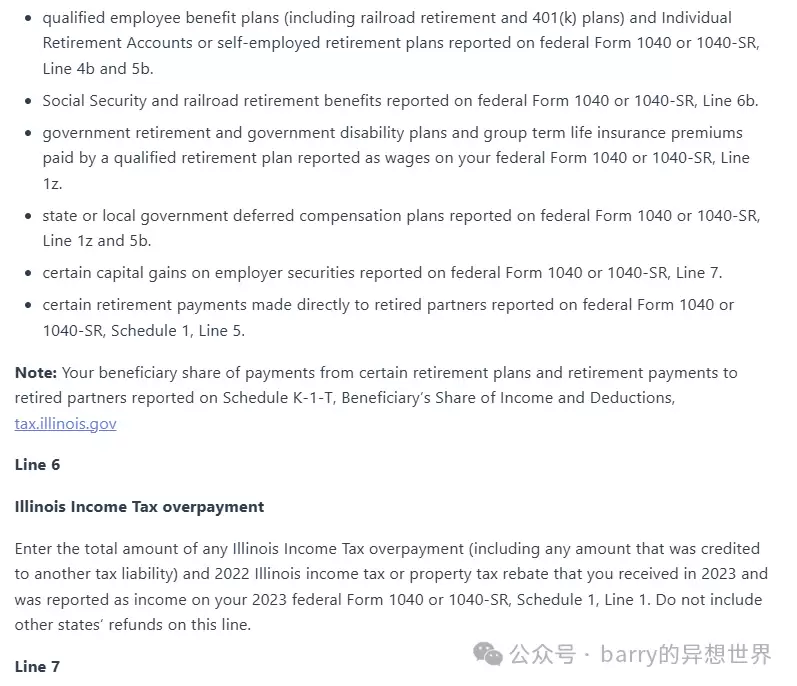
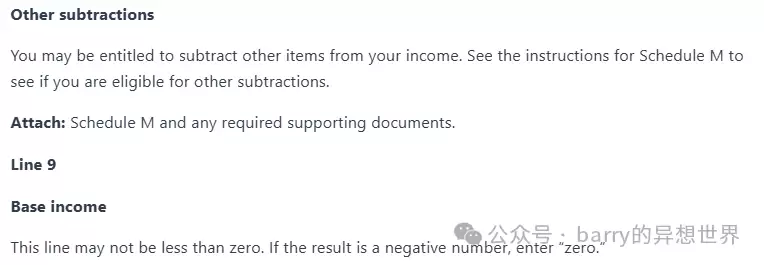
可以看到,提取出的Markdown质量非常高,它基本模拟了人类阅读页面的方式。上面的“步骤2”(页面上半部分)在“步骤3”(下半部分)之前被完整描述了出来。
另外,生成的Markdown包含了项目符号列表、加粗文本、标题等。所有这些都为提取的原始文本增加了含义,当把这个Markdown再传给Gemini时,通常会得到更好的结果。而且,如前所述,有了标题和副标题,我们就能把文档分块成逻辑分组,这对RAG的检索过程来说非常有用。
实施细节
具体实现时,你可以简单地遍历PDF的每一页,提取页面图像,然后传给Gemini来获取Markdown。但处理这个问题时,必须考虑扩展性。
在我的笔记本上,提取示例页面图像只用了0.140秒,这一步非常快。但调用Gemini 1.5 Flash来提取Markdown却花了23.857秒。对于页数更多的PDF文档,这个时间会迅速累积。
好在,这个问题非常适合用Map-Reduce方法来解决。这个思路是先拆解任务,把工作分成多个部分并行运行(Map步骤),然后等所有部分完成后,再合并结果(Reduce步骤)。
在我们的场景里,我们可以分别处理每一页,等所有页面都处理完,再合并Markdown。借助Google Cloud,我们可以用PubSub主题来分配任务,用Cloud Run Function来处理每一页。下面这张图说明了整体架构:
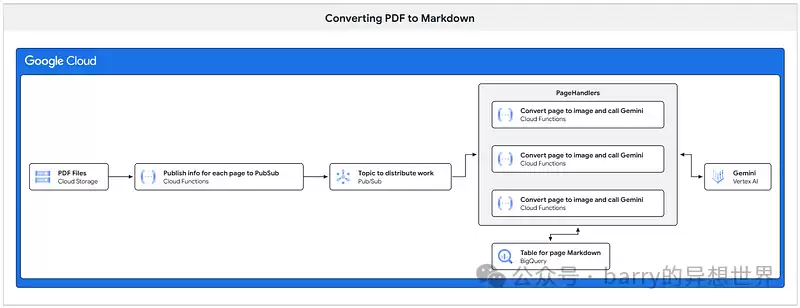
从左到右,具体步骤如下:
- 当PDF文件被放入Google Cloud Storage存储桶时,触发一个Cloud Function。
- 这个函数把PDF从存储桶复制到本地存储,然后打开它,确认里面有多少页。接着,对每一页,函数向PubSub主题写入一个小的JSON项,包含PDF名称、要处理的页码(从0到N-1)以及PDF的总页数。
- 当PubSub主题中间出现新项目时,触发Page Handler云函数。借助Cloud Run提供的并行处理能力,可以同时运行该函数的多个调用。你可以在配置函数时指定最大并发数。
- 该函数把PDF从存储桶复制到本地存储,打开PDF,为相关页码渲染图像,然后通过Vertex AI API调用Gemini来获取Markdown。
- 获取到页面Markdown后,把它存储在BigQuery表中,这个表包含三个字段:文件名、页码和提取的Markdown字符串。
前面这几步完成了每一页的Markdown提取(Map步骤),接下来还需要处理Reduce步骤,把所有单独的页面Markdown合并成一个字符串。
最简单的做法是:让页面处理函数检查一下,它处理的这一页是不是文档的最后一页。通过计算某个文档在BigQuery表中已有的页数,就可以判断所有处理是否完成(这就是为什么我们需要在PubSub消息里传递总页数)。
也就是说,在页面处理函数完成当前页的工作后,它会从BigQuery表中计算该文档已完成的页面数量。如果这个数字等于总页数,就说明所有页面都处理完了。此时,函数会检索所有单独的页面Markdown字符串(按页码排序),并合并成一个字符串。然后,你可以把这份文档Markdown存成文件,或者如果需要,做进一步处理(比如把它作为发送给Gemini的另一个提示的一部分)。
实现代码
先来看PDF文件处理程序的代码——也就是PDF文件被放入存储桶时被调用的那个函数。我们用PDF库PyPdfium来计算页数。
from google.cloud import storage, pubsub_v1
import os
from typing import Callable
from concurrent import futures
import pypdfium2 as pdfium
import json
## 项目ID
project_id = os.getenv("PROJECTID")
## 要写入的PubSub主题
pubsub_topicname = os.getenv("TOPICNAME")
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(project_id, pubsub_topicname)
def handle_new_file(event, context):
# 从云存储复制文件到本地存储
bucketname = event['bucket']
filename = event['name']
if filename.lower().endswith('.pdf') is False:
print(f"文件 {filename} 不是PDF文件,跳过")
return
localname = '/tmp/test.pdf'
download_to_local(bucketname, filename, localname)
# 确定有多少页
num_pages = len(pdfium.PdfDocument(localname))
# 对于每一页,发布一条消息
publish_futures = []
for page_num in range(num_pages):
data = json.dumps({"filename": filename, "pagenum": page_num, "totalpages": num_pages}).encode('utf-8')
future = publisher.publish(topic_path, data)
future.add_done_callback(get_callback(future, data))
publish_futures.append(future)
futures.wait(publish_futures, return_when=futures.ALL_COMPLETED)
os.remove(localname)
def download_to_local(bucketname, filename, localname):
bucket = storage_client.bucket(bucketname)
blob = bucket.blob(filename)
blob.download_to_filename(localname)
def get_callback(publish_future: pubsub_v1.publisher.futures.Future, data: str) -> Callable[[pubsub_v1.publisher.futures.Future], None]:
def callback(publish_future: pubsub_v1.publisher.futures.Future) -> None:
try:
publish_future.result(timeout=60)
except futures.TimeoutError:
print(f"发布 {data} 超时。")
return callback接下来,是处理单个页面的函数。
import base64
from google.cloud import storage
import os
import json
from read_pdf import get_markdown_for_page
from bigquery import sa ve_page_info, get_num_pages_for_filename, get_markdown_for_filename
BUCKET = os.getenv("BUCKET")
storage_client = storage.Client()
def handle_pubsub_message(event, context):
message_bytes = base64.b64decode(event['data'])
message_str = message_bytes.decode('utf-8')
message_json = json.loads(message_str)
filename = message_json.get("filename")
pagenum = message_json.get("pagenum")
totalpages = message_json.get("totalpages")
download_to_local(BUCKET, filename, "temp.pdf")
markdown = get_markdown_for_page("temp.pdf", pagenum)
sa ve_page_info(filename, pagenum, markdown)
num_pages_for_filename = get_num_pages_for_filename(filename)
if num_pages_for_filename == totalpages:
all_markdown = get_markdown_for_filename(filename)
sa ve_text_to_bucket(BUCKET, f'markdown{filename}.md', all_markdown)
def download_to_local(bucketname, filename, localname):
bucket = storage_client.bucket(bucketname)
blob = bucket.blob(filename)
blob.download_to_filename(localname)
def sa ve_text_to_bucket(bucketname, filename, text):
bucket = storage_client.bucket(bucketname)
blob = bucket.blob(filename)
blob.upload_from_string(text)这个函数调用了额外的模块。第一个是read_pdf.py模块,负责提取图像并调用Gemini获取Markdown:
import vertexai
from vertexai.generative_models import (
Part,
Image,
GenerativeModel,
HarmBlockThreshold,
HarmCategory,
)
import pypdfium2 as pdfium
import os
PROJECT_ID = os.getenv("PROJECTID")
REGION = os.getenv("REGION")
LOCAL_IMAGE_FILE = "/tmp/page.png"
vertexai.init(project=PROJECT_ID, location=REGION)
model = GenerativeModel("gemini-1.5-flash-002")
def get_markdown_for_page(fname, pagenum):
imgname = get_image_for_page(fname, pagenum)
markdown = call_gemini_for_markdown(imgname)
return markdown
def get_image_for_page(fname, pagenum):
doc = pdfium.PdfDocument(fname)
page = doc.get_page(pagenum)
bitmap = page.render(scale=2)
bitmap = bitmap.to_pil()
bitmap.sa ve(LOCAL_IMAGE_FILE)
return LOCAL_IMAGE_FILE
def call_gemini_for_markdown(img_filename):
image1 = Part.from_image(Image.load_from_file(img_filename))
generation_config = {
"max_output_tokens": 8192,
"temperature": 1,
"top_p": 0.95,
}
safety_settings = {
HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE,
HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE,
}
responses = model.generate_content(
[image1, "检查图像并返回其中所有文本,转换为 Markdown。确保文本反映人类阅读的方式,遵循列并理解格式。忽略脚注和页码 - 它们不应作为 Markdown 的一部分返回。仅为页面上找到的文本生成 markdown。"],
generation_config=generation_config,
safety_settings=safety_settings,
stream=True,
)
response_text = []
for response in responses:
response_text.append(response.text)
return "".join(response_text)可以看到,我们用来提取Markdown的提示词是这样的:
检查图像并返回其中所有文本,转换为
Markdown。确保文本反映人类阅读的方式,
遵循列并理解格式。忽略脚注和
页码 - 它们不应作为 Markdown 的一部分返回。
仅为页面上找到的文本生成 markdown。最后,是与BigQuery交互的几个函数,位于bigquery.py模块:
from google.cloud import logging, bigquery
import os
import time
BQ_DATASET = os.getenv("BQ_DATASET")
BQ_TABLE = "pdf2markdown"
bq_client = bigquery.Client()
logging_client = logging.Client()
log_name = "debug-log"
logger = logging_client.logger(log_name)
def sa ve_page_info(filename, pagenum, markdown):
table_id = f'{BQ_DATASET}.{BQ_TABLE}'
table_ref = bq_client.dataset(BQ_DATASET).table(BQ_TABLE)
try:
errors = bq_client.insert_rows_json(
table_ref,
[{
"filename": filename,
"pagenum": pagenum,
"markdown": markdown
}])
if errors == []:
logger.log_text("数据已插入表中")
else:
logger.log_text(f"插入数据时遇到错误: {errors}", severity="ERROR")
except Exception as e:
logger.log_text(f"插入数据到 BQ 时出错: {e}", severity="ERROR")
def get_num_pages_for_filename(filename):
query = f"SELECT COUNT(*) as numpages FROM `{BQ_DATASET}.{BQ_TABLE}` WHERE filename = '{filename}'"
query_job = bq_client.query(query)
results = list(query_job.result())
count = results[0].numpages
return count
def get_markdown_for_filename(filename):
query = f"SELECT markdown FROM `{BQ_DATASET}.{BQ_TABLE}` WHERE filename = '{filename}' ORDER BY pagenum"
query_job = bq_client.query(query)
results = list(query_job.result())
parts = [row.markdown for row in results]
return "n".join(parts)需要注意一点,这段代码假设BigQuery表pdf2markdown已经预先创建好了。虽然你可以通过代码来创建表,但在创建后立刻插入数据,会有一个短暂的延迟,容易导致错误。实践经验是,先用Terraform或其他基础设施即代码(IAC)工具在代码之外把空表建好。
结论
这篇文章主要讨论了处理PDF文档时面临的挑战,特别是针对RAG应用。PDF文件的设计初衷是支持几乎任何能想象到的布局,所以当你试图从中提取文本和相关的上下文信息(比如标题、表格)时,往往非常困难。
而Markdown则非常适合与Gemini这类大模型配合使用。它在提升输出可读性和上下文丰富度方面作用明显,在构建提示词时更是如此,同时它也能帮助你在RAG解决方案中更好地分块和索引文档。真正的挑战在于,如何把PDF里的内容提取成Markdown。
通过把PDF的每一页都转换成图像,然后让Gemini把页面内容提取成Markdown,我们可以快速、轻松地从文档中提取文本及其上下文。再借助Google Cloud的并行处理能力,这个流程可以变得极其高效。当所有页面处理完毕后,再合并结果。
最后,另一个值得探索的选项是Google Cloud的DocumentAI。它也利用Google基础模型来解析和分块文档,并内置了OCR支持,可以解析基于图像的页面。你可以把这种方法同本文描述的方案做个对比,看看哪个更适合你的文档。但请记住,DocumentAI返回的不是Markdown。在做选择时,这一点需要纳入考量。