在人工智能发展的历程中,语言处理始终面临一个核心矛盾:我们总想用离散的“token”去捕捉本质上连续、复杂的人类思维。这种做法之所以大行其道,坦白讲,更多是出于工程实现的方便。计算机只认数值,所以任何文本都得先切分成token,再转化成向量,才能扔进模型里去算。这个方法简单、直接,效果也确实不错,但它有一个根本性的缺陷:它离人类的思维模式实在太远了。Hyperbolic的CTO Yuchen Jin就一针见血地指出,人类根本不是在用“token”思考,我们用的是“概念”。
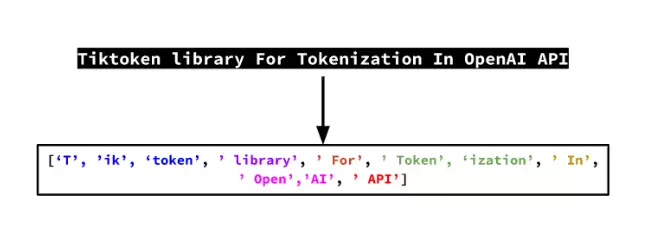 (tokenizaiton的示例)
(tokenizaiton的示例)
Token和概念的关系,很像是词汇和语义。想象一个外国人在学中文,他可能背下了每个字的发音和含义,但面对“山雨欲来风满楼”这句诗时,依然一脸茫然。因为要理解这句诗,你不能只认识字,你得理解“山雨”、“风”和“危机感”这些概念之间的联系。而传统的、基于token学习的AI,本质上是靠学习不完整的字词符号之间的统计关系,去“猜”下一个token是什么。这也是很多严肃的AI研究者并不认为这种模型能真正“理解”世界的原因。比如Meta的研究员、日内瓦大学教授Francois Fleuret就直言,OpenAI现在大力推广的思维链(CoT),不过是“对人类思维的拙劣模仿”。

他认为,一个真正有前途的大语言模型(LLM),应该能在潜空间里进行更可观察、更灵活的抽象思考。
其实,Meta已经在朝着这个方向悄悄发力了。整个2024年12月,他们连续丢出三篇论文,目标直指挑战“token思维”。最具标志性的一篇,是12月24日发布的《Large Concept Models: Language Modeling in a Sentence Representation Space》。这篇论文的核心思路很直接:让大模型直接从“概念”学起。

他们给这种用概念训练的模型起了个名字,叫“大概念模型”(Large Concept Model,简称LCM)。

让大模型直接学概念
Meta研究团队的思路其实不复杂:把原来喂给模型的token序列,替换成一组组概念的序列。用来做这个“概念转换”的工具,是他们自家的SONAR。你可以把它理解成一个编译器,能把文本映射到一个概念空间里,用一个1024维的向量来代表这个概念。在这个空间里,意思相近的概念,它们的向量距离也就更近。SONAR本身就具备在200种语言之间进行翻译的能力,因为它抓住了语言背后通用的“概念”。

(SONAR的基本运作逻辑)
SONAR就像一座桥梁,一头连着token,另一头连着高层语义。LCM接收和输出的,就只有这些概念向量。有了这层抽象,关键问题变成了:模型架构该怎么设计?Meta团队详细探索了三种方案。
第一种是基础LCM(Base-LCM)架构。 这个方案结构清晰,训练稳定。SONAR先把输入的token序列映射成概念向量,一个Transformer模型接收这些概念向量,并预测下一个概念向量,最后再由SONAR把预测出的概念向量解码成目标语言。但问题也很明显:所有的语义信息都得从中间这个“概念向量”的小管道里过,容易造成信息损失。比如,当模型看到“我今天很开心”,它后面可能接“因为考了满分”、“因为见到朋友”、“因为收到礼物”。Base-LCM会倾向于预测一个“中间状态”,把所有可能性混在一起,结果变得模糊不清。它就像个只会答“标准答案”的学生,缺少创造力和随机性。
第二种是Quant-LCM架构。 这个方案把SONAR提供的连续概念空间重新“离散化”。比如描述“苹果”,SONAR可能用一个1024维的向量来精确描述它的颜色、形状、味道等特征,而Quant-LCM则只用“红色、圆形、水果、甜味”这几个简单的特征码来代表。这样计算更快更简单,也更有创造力,就像用基本词汇组合新句子。但代价是精度损失明显,模型效能不太理想。
鉴于前两种方法各有短板,Meta最终选择了第三种方案:Diffusion双塔架构。 这个架构包含两个主要组件:左边的一“塔”和Base-LCM结构类似,负责输出一个结构准确、表意清晰的概念框架,好比一个写文章大纲的人。右边的一“塔”则是一个Diffusion去噪器,它像一个反复推敲润色的编辑,负责把从左边拿到的“大纲”变得更丰富、更生动。
(Diffusion双塔结构示意)
Diffusion去噪器的工作方式很有趣:它会先把得到的信息故意“弄模糊”(加噪),然后再通过一步步的“提炼”(去噪)来重建内容。训练时,系统还会使用一个特殊的掩码策略,刻意遮住一些信息(比如图里红色标注的部分),让模型学会在信息不完整的情况下也能工作。这种训练方法极大地提升了模型的鲁棒性。这个双塔结构既避免了Base-LCM的“古板”,又通过Diffusion引入了足够的随机性和细节,是三者中最优的方案。测试结果也证明了这一点,LCM在多个标准评测任务上表现优异,尤其在跨语言和长文本生成上优势明显。因为概念之间的关联,比token之间的关联覆盖范围更大,这相当于直接增强了模型的语义理解能力。
在跨语言任务上,LCM的表现尤其亮眼。比如翻译“望子成龙”这个成语,如果只看具体字词,无论如何都得不到“Like father, like son”这种意译。因为两者字面完全不同,但表达了相似的文化概念。而直接把握概念的LCM,可以轻松跳到这个正确的概念映射上。
当然,LCM也有短板。在文本扩展任务上,它的Rouge-L分数(30.85)就低于主流的LLM(如Llama-3.1-8B-IT的37.76)。这也不难理解,因为LCM的表达严格受限于SONAR编译器提供的概念词典,它能准确表意,但表达方式会相对简单。比如你问LCM“今天去哪玩?”,它可能回答“去公园散步”。但问一个LLM,它可能会洋洋洒洒说一大串:“考虑到今天阳光明媚,可以去城市公园散步,那里有漂亮的花园和儿童游乐设施……”不过,从准确性和效率来看,LCM的优势也很明显。相比同样大小的Llama 2 7B模型,LCM的推理速度大约是它的3到4倍,而成本仅为其一半。
不止LCM,Meta全方位发力潜空间
LCM实际上是Meta近期对“潜空间”发起挑战的第三次尝试。
BLT:让潜空间还原为字节
12月12日,Meta发布了另一篇备受关注的论文《Byte Latent Transformer: Patches Scale Better Than Tokens》,同样意在打破tokenization的统治地位。不过,这次的方法不是向上走寻找“概念”,而是向下走,用更底层的“字节”去取代token。这个方法被称作BLT。它和LCM很像,通过一个轻量级的Transformer模型把字节编组成“动态的字节包(patches)”,再用这些字节包去训练一个核心的Latent Transformer模型,最后再通过另一个解码器把字节包还原成字节序列。这里的编码器作用和LCM里的SONAR几乎一致。实验结果也说明这条路是可行的。BLT-Entropy模型在7项任务中的4项上,表现优于Llama 3模型。这主要得益于动态patch能更高效地利用计算资源,细腻地还原字节之间的关系,同时也避免了静态token词表带来的限制。这项研究的潜力巨大,以至于有知名AI研究者评论,2025年或许会因此成为“Tokenization终结之年”。
Coconut:用想法代替语句做推理
再往前,12月9日,田渊栋带领的团队发表了另一篇论文。他们选择了另一条路径:不再强制模型把中间推理过程转换成具体的语言token,而是直接用模型的“推理状态”(他们称之为“想法”)在潜空间里进行思维链推理。这个方法被称作Coconut。在这个模型里,研究团队直接利用模型的最后一个隐藏状态(即这个“想法”)作为下一个输入的嵌入。整个推理过程连续可微,可以通过梯度下降来优化。这就像让模型在“想法”的空间里直接思考,而不是非得把每一步的思考过程都说出来。它的训练方式也很特别:前几步还是用传统的思维链方式训练,用token作为元素,然后逐渐加大“想法”的占比,直到最后完全用“想法”取代token形成的语句。这个方法有效提升了LLM的推理能力,在部分测试项目上甚至优于传统的CoT。更重要的是,通过这种方法,模型的推理不再是简单的链式结构,而是一个由最后一个隐藏状态引发的树状搜索,可以一次性选择多个潜在节点,大大减少了因为第一步走错而导致后续推理全部跑偏的“幻觉”问题。
一场针对“潜空间”的范式转变
为什么说Meta近期的研究是范式变革的开始?因为它触动了最核心的底层架构——潜空间。无论是token、字节patch还是概念,它们都对应着语言模型的潜空间。换一种表征方法,潜空间的排列逻辑就会完全不同,模型的整个思维模式也会由此改变。
潜空间(Latent Space)这个词听起来玄妙,但它其实就是现代大语言模型的“思维殿堂”。在这个无形的空间里,万千概念被编织成一张精妙的多维网络。词语不再是孤立的,而是以一种概率的方式彼此呼应:相关的概念被放在附近,“狗”和“猫”离得近,“开心”和“快乐”挨着。我们甚至能在这个空间里做“计算”,比如“国王-男人+女人=王后”这种经典的类比,就源于此。
Meta对潜空间的改造,本质上是在重塑AI的“思考空间”。BLT让语言模型的理解变得更灵活多变,更接近“概率”的本质;Coconut则给了语言模型更宽广的推理路径;而LCM的尝试最为大胆,它意图粘合符号主义和连接主义,首次让AI突破词符层面的机械思维,转而在语义空间中进行推理和生成。这种架构上的革新,带来的是无限的可能性:它让跨语言理解成为一种与生俱来的能力,简化了长文本的连贯表达能力,更重要的是,为更高层次的抽象推理铺平了道路。
当我们站在2024年的尾声,屡屡听到“预训练碰壁”的说法时,也许正是打破这些常规思维,才能让AI再次进化。