大语言模型与知识图谱的共生革命
先说一个核心判断:大语言模型(LLM)和知识图谱(KG),不是替代关系,而是互补关系。一个是参数化隐性的数据库,一个是形式化显性的知识库,它们各自有擅长的事,也在彼此最吃力的时候能搭把手。
一、背景概述
知识图谱(KG)概述
先说说知识图谱。它的本质,是一种知识表示方式。说通俗一点,就是以 (实体, 关系, 实体) 这样三元组集合的形式,把知识打包成结构化的数据。比如(周杰伦, 演唱, 《青花瓷》),这就是一个典型的三元组。
知识图谱的构建思路很清晰:先定义一个领域本体,把某个业务领域的知识结构——概念、实体属性、实体关系、事件属性、事件之间的关系——都表达清楚,形成知识规范。然后,通过实体识别、关系抽取、事件抽取这些方法,从各类数据源里捞出结构化数据,进行知识填充。最后,以属性图或RDF格式存储起来。整个过程听起来不算复杂,实际做起来相当耗费心力。
根据存储信息的不同,现有的知识图谱可以分成四类:百科知识型、常识型、特定领域型、多模态知识图谱。各自用途不同,构建难度和成本也差异很大。
大语言模型(LLM)概述
再来看看大模型这边。它的底子是transformer架构加多头注意力机制,把所有知识都隐含地表示在参数里。从架构上分,有encoder-decoder、encoder-only、decoder-only等类型。侧重点不同,能力边界也不一样。
可行性分析
现有的应用已经给出了方向。文心一言和Bard都把知识图谱融入了聊天机器人中,用来提高LLM的知识感知能力。Doctor.ai则做了一个医疗助手,把LLM和知识图谱结合起来提供医疗建议。
用一句话概括就是:KG和LLM都是储存、处理、利用知识的方式,但路径不同。知识图谱长于结构化推理和知识管理,大模型则擅长语义理解、内容生成和常识推理。两者可以互补,而不是非此即彼。
- LLM擅长的领域包括:语义理解、指令遵循、思维链、基础常识支持、上下文理解、情感分析、推理规划等,拿手好戏是智能对话、内容生成、内容加工、作品创作、机器翻译、意图识别。
- KG擅长的事则集中在:智能检索、智能推荐、辅助决策以及知识管理。而知识管理这一块,又包括了知识融合、知识存储、知识补全、知识查询、知识推理、知识溯源、知识共享与交换、知识更新与维护等核心能力。
可以看到,一个是“会说话但偶尔胡说八道”,一个是“条理清楚但比较死板”。把两个结合起来,没准就是最优解。
二、融合知识图谱和大语言模型
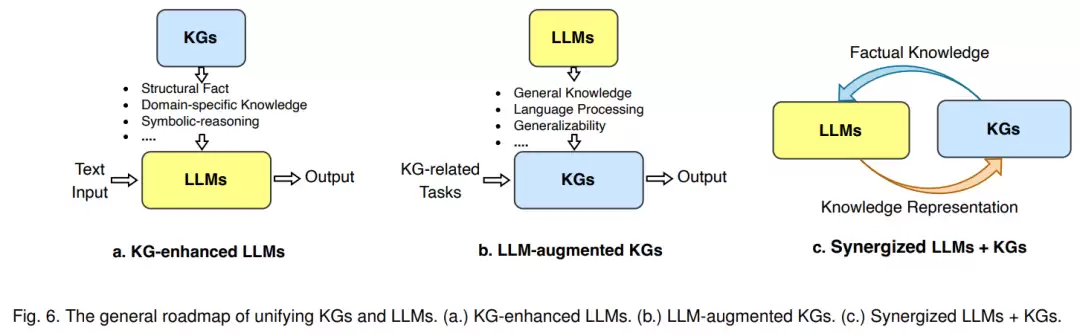
目前,这三种框架已经形成了共识:
1)KG增强的LLMs——在LLMs的预训练和推理阶段加入KGs,目的是加强对LLMs所学知识的理解;
2)LLM增强的KG——利用LLM完成不同的KG任务,比如嵌入、完成、构建、图文生成和问答;
3)协同的LLM+KG——LLM和KG各自扮演同样的角色,互相帮忙,实现双向推理,由数据和知识共同驱动。
1. KG增强LLM
1.1 KG增强LLM预训练
1.1.1 将KGs整合到训练目标中
第一个方向,是在预训练目标里暴露更多的知识实体。比如GLM,利用知识图谱结构,给重要的学习实体分配一个高的掩码概率。E-BERT更进一步,控制了token级和实体级训练损失之间的平衡。SKEP则在预训练期间注入情感知识,给确定的情感词语分配较高的掩蔽率。
另一个思路是明确利用知识和输入文本的联系,加强对实体的识别。文心一言提出了一种新颖的word-entity对齐训练目标——把句子和文本中提到的相应实体一起输入到LLM中,然后训练LLM预测token与知识图谱中实体之间的对齐连接。
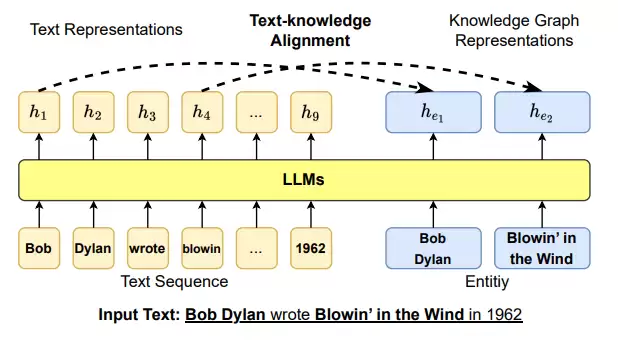 图注:文本-知识对齐损失将知识图谱信息注入到LLM的训练目标中,其中h表示由LLM生成的隐藏表示。
图注:文本-知识对齐损失将知识图谱信息注入到LLM的训练目标中,其中h表示由LLM生成的隐藏表示。
1.1.2 将KGs整合到LLM的输入中
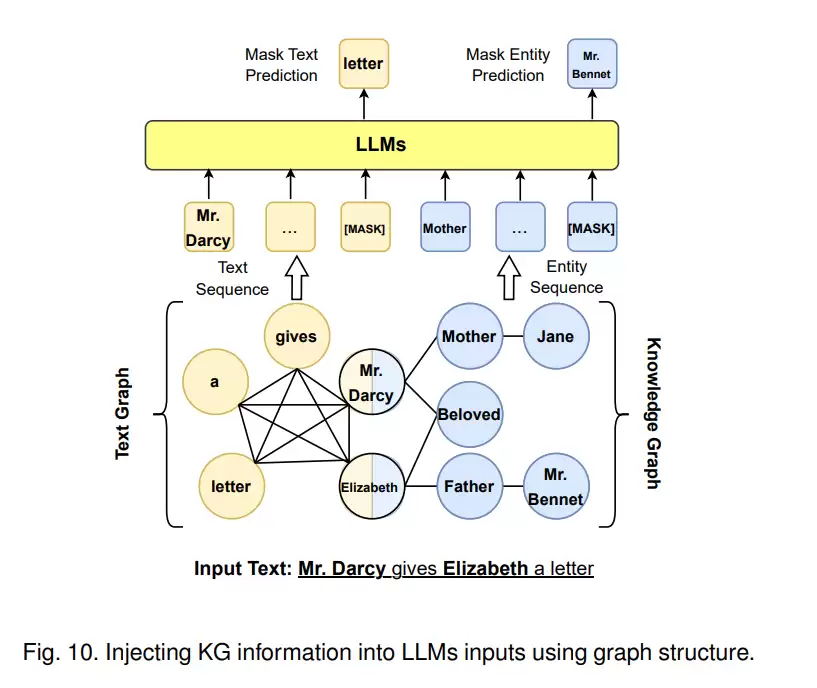
另一个做法,是把相关的知识子图直接塞到LLM的输入里。ERNIE 3.0的做法是,把一个三元组和相关的句子表示成一连串token,直接跟句子连接起来,再随机mask掉三元组中的关系标记或句子中的标记。
不过这样操作有个风险:Knowledge Noise。知识喂得太多了,反而会让原始句子偏离本意,过犹不及。为了解决这个问题,word-knowledge graph被提了出来——输入句子中的token形成一个完全连接的词图,与知识实体对齐的token跟相邻实体连接在一起。这样既保留了知识,又不至于喧宾夺主。
1.1.3 通过额外的融合模块来整合KGs
还有一种方案是文本-知识双encoder架构,简单说就是LLM负责处理文本,KG模块负责处理知识,两者各司其职,再通过融合模块把信息整合起来。
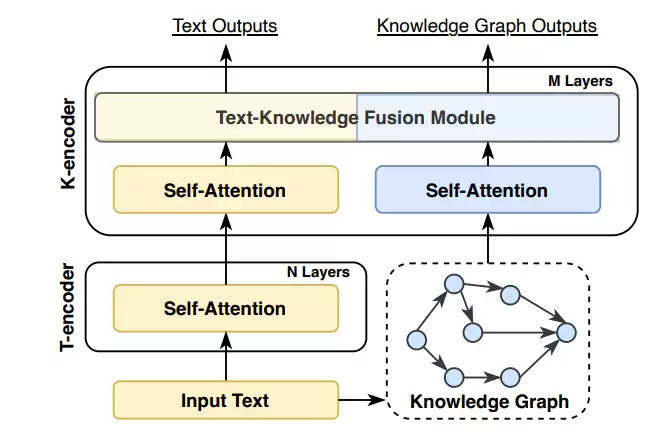 图注:THU-ERNIE的双encoder架构
图注:THU-ERNIE的双encoder架构
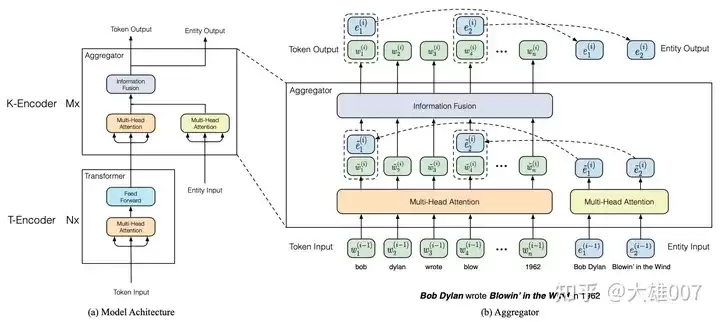
1.2 KG增强LLM推理
1.2.1 动态知识融合
这个方向的核心思路,是双塔架构:一个模块处理文本输入,另一个模块处理相关的知识图谱输入。然后通过LM到KG和KG到LM的双向关注机制,在文本输入中的任何token和任何KG entity之间进行细粒度的交互。再根据注意力得分动态剪枝,让后面的层能够专注于更重要的子KG结构。
1.2.2 检索-增强型知识融合
非参数模块和参数模块结合起来。先用Maximum Inner Product Search(MIPS)在非参数模块里检索相关的KG,然后把这些信息当背景知识给大语言模型。这种方式的好处是灵活性高,不用动模型本身。
1.3 KG增强LLM的可解释性
1.3.1 用于探测
通过预先定义的提示模板,把KGs中的事实转化为填空问题。然后用LLMs来预测缺失的实体。这样就能评估LLMs里存储的知识到底有多少是靠谱的。
1.3.2 用于LLM分析的KGs
让LLMs在每个推理步骤产生的结果以知识图谱为基础。这样一来,LLMs的推理过程就变得可追踪、可分析——不再是黑盒了。
总结一下,KG增强LLM的好处有四点:
1. 提高知识可信度:依托知识图谱中经过质量评估的知识,能帮助大模型提高信息的质量和可信度,保障知识的正确性和时效性。
2. 增强通用性、领域能力、认知能力:可以帮大模型获得跨领域和跨语言的知识,更好地适应不同的领域任务和场景。
3. 降低构建成本:依托知识图谱中的结构化知识,可以减少大模型对标注数据或专家知识的需求,从而降低构建成本和难度。
4. 提高可生成性:能帮大模型生成更贴近实际、更有解释性的内容。同时也能提升创作能力——通过知识增强,大模型创作的内容会显得更有逻辑、一致性和创新性。
2. LLM增强KG
2.1 增强KG embedding
知识图谱嵌入(KGE)的目标很简单:把每个实体和关系映射到一个低维向量(嵌入)空间中,希望这些嵌入能包含知识图谱的语义和结构信息。
传统KGE主要靠KG的结构信息来优化评分函数。短板也很明显——因为结构的连通性有限,这些方法在未见实体和长尾关系上,表现一言难尽。所以,利用LLM来丰富KG的表征,就成了自然的选择。
2.1.1 LLM做文本编码器
这个方向的代表性方法是Pretrain-KGE。给定一个三元组 (head entity, relation, tailed entity),先让LLM(Bert)编码器把实体h、t和关系r的文本描述编码,得到初始嵌入。然后,初始嵌入被输入到KGE模型里,生成最终的嵌入。这样既能学到充足的结构信息,又能保留部分LLM中的知识。
2.1.2 同时联合文本和KGE
另一个方法更直接——用大语言模型把图结构和文本信息同时合并到嵌入空间。kNN-KGE是代表。它把实体和关系视为special token。训练期间,它把每个三元组 (h, r, t) 和对应的文字描述组成一个句子,将尾部实体做掩码后喂入LLM,微调它去预测掩码。微调后的模型,直接用作嵌入模型。
2.2 增强KG Completion
知识图谱补全(KGC),就是推断给定知识图中缺失的事实。传统的方法也主要集中在结构上,不太考虑文本信息。引入LLM,可以让KGC方法编码文本或生成事实,从而取得更好的性能。
2.2.1 LLM作为编码器 (PaE)
用encoder-only的LLM来编码文本信息和KG事实,然后通过将编码后的表述输入预测头来预测三元组的可信度。预测头可以是一个简单的MLP,也可以是传统的KG评分函数(比如TransE和TransR)。
PaE在LLM编码的顶部加了一个预测头,所以更容易微调:冻结LLM,只优化预测头。而且预测的输出可以轻松指定,跟现有的KGC功能集成。
但缺点也很明显:推理阶段要求计算每个KG candidate的分数,计算成本不低。而且它们不能泛化到没见过的实体。更大的问题是,PaE需要LLM的中间输出,像GPT-4这种闭源模型,根本拿不到。
2.2.2 LLM作为生成器 (PaG)
encoder-decoder或decoder-only的LLMs,接收三元组的序列文本输入 (h, r, ?),直接生成尾部实体t的文本。
这个方案面临的挑战也不小:生成的实体可能五花八门,根本不在KG里。加上自回归生成,单次推理时间比较长。另外,怎么设计有力的prompt把KG送进LLM,也是个开放的难题。
2.3 增强KG构建
知识图谱构建,涉及在特定领域内创建知识的结构化表示。它包括识别实体及其相互关系,一般会经过多个阶段:entity discovery、coreference resolution和relation extraction。
2.3.1 端到端的知识图谱构建
2.3.2 从LLM中蒸馏出KG
这一步的核心,是把LLM里的隐性知识转化成显性的知识图谱。
2.4 生成描述KG事实的自然语言
KG-to-text的目标是生成高质量的文本,准确且一致地描述输入的知识图谱信息。这项工作把知识图谱和文本连接起来,大大改善了KG在更现实的NLG场景中的适用性——包括讲故事和基于知识的对话。
当然难点也很清楚:收集大量的图-文并行数据成本很高,而且容易导致训练不足、生成质量差。
2.4.1 利用大语言模型的知识
2.4.2 构建大规模弱对齐KG-文本语料库
预训练的大语言模型很难跟KG-to-text这个下游任务对齐,所以研究者开始开发大规模的KG-文本对齐语料库。比如从维基百科搞来的130万无监督KG到图形的训练数据。做法是先通过超链接和命名实体检测器检测文本中间出现的实体,然后只添加与相应的知识图谱共享一组常见实体的文本。
2.5 知识图谱QA
KGQA的目标是基于知识图谱里存储的结构化事实,找到自然语言问题的答案。这个任务里不可避免的挑战是检索相关的事实,并把知识图谱的推理优势扩展到问答。
2.5.1 LLM作为实体/关系提取器
识别自然语言问题中提到的实体和关系,再在知识图谱中检索相关事实。
2.5.2 LLM作为答案推理器
对检索到的事实进行推理并生成答案。LLM可以直接干这个活。
LLM增强KG的好处,也总结四点:
1. 增强理解能力:大模型的语义理解能力帮知识图谱更好地理解和分类非结构化信息。
2. 降低构建成本:大模型的上下文理解能力和基础常识支持,帮知识图谱提升非结构化数据的知识获取、建模、融合能力,降低构建和维护成本。
3. 丰富输出形式:大模型的生成能力帮知识图谱获得更多元的知识输出和服务形式,增强系统服务效果,提升人机交互水平。
4. 提高知识完备性:大模型中涵盖的知识及其对新数据的理解能力,帮知识图谱做知识补全和知识校验,提高知识完备性。
3. LLM和KG协同
理想状态,是把LLMs和KGs的优点结合起来,相互增强性能。
3.1 统一知识表示
对齐文本语料库和知识图谱中的知识,统一表示。
3.2 推理
1. 用LLMs处理文本问题,引导知识图谱上的推理步骤。这种方法能弥合文本和结构信息之间的差距,给推理过程提供可解释性。
2. 在知识图谱推理任务中,有一种由LLM引导的逻辑推理方法:把传统的逻辑规则转化为语言序列,让LLMs对最终输出进行推理。
3. 在统一框架里融合结构推理和语言模式的预训练。给定文本输入,用LLMs生成逻辑查询,然后在知识图谱上执行查询获取结构化上下文,最后融合起来生成最终输出。
4. 结合知识图谱和LLMs,在对话系统中提供个性化的推荐。
协同的好处有六点:
1. 提高可解释性:显性知识加隐性知识,能提高知识应用的可解释性。
2. 实现交叉验证:不同来源的输出结合起来,可以为知识应用提供校验手段,提高可信赖性。
3. 优化知识存储:结构化信息存储和非结构化信息处理结合,可以优化存储和检索效率。
4. 提高决策能力:不同推理结果结合起来,能进一步丰富辅助决策的知识背景,提供更精确的建议。
5. 增强隐私保护:知识图谱的数据加密和保护能力跟LLM数据调用能力结合,可降低对个人隐私数据的依赖,保障隐私安全。
6. 增强伦理边界:通过优化知识图谱的知识结构及LLM训练样本结构,构建约束规则类知识降低数据偏见,强化输出边界。
三、未来方向
1. 用于检测LLM幻觉的KGs:通过KG增强预训练或推理,利用KG来获取更可靠的LLMs。
2. 用于编辑LLM中知识的KGs:LLMs能存大量的现实世界知识,但现实情况变化时,它们没法快速更新内部知识。虽然有研究提出了在不重新训练的情况下编辑LLMs的知识,但效果还不太理想——存在遗忘、不正确的知识编辑,或者计算开销太大的问题。现有方案也只能处理KGs中基于元组的简单知识。
3. 用于LLMs的KGs知识注入:传统的KG注入方法通过增加额外的知识融合模块来改变LLM结构。但闭源模型没门。把各种类型的知识转换为不同的文本提示,看上去是个方案。但问题是,这些提示能不能泛化到新的LLM?加上基于提示的方法受限于输入长度。所以,怎么让LLMs有效地注入知识,还是待探索的课题。
4. 多模态LLMs for KGs:现在的知识图谱通常依赖文本和图结构来处理相关应用。但现实世界的知识图谱常常是由多个模态的数据构建的。怎么有效利用多个模态的表示,将成为未来知识图谱研究的重要挑战。一个可能的方案是开发能准确对不同模态之间的实体进行编码和对齐的方法。近年来多模态LLMs的发展,在这方面有潜在前景。但填补多模态LLMs与知识图谱结构之间的鸿沟,仍然是这个领域的关键挑战。
5. 理解KG结构的LLMs:传统在纯文本数据上训练的LLMs,不是为理解知识图谱这种结构化数据设计的。所以LLMs可能无法完全掌握KG结构所传达的信息。现在最直接的办法是把结构化的数据线性化成句子。但KGs规模太大,不可能全部线性化作为输入,而且线性化过程可能会丢掉一些基本信息。发展能直接理解KG结构并推理的LLM,是未来的方向。
6. 双向推理的协同LLM和KGs:目前对LLMs和知识图谱协同作用的研究还不多。这种协同可以应用于搜索引擎、推荐系统、药物发现等现实场景。给定一个应用问题,可以用知识图谱来做基于知识的搜索,找潜在的目标和未见数据;同时用LLMs来做基于数据/文本的推理,看能得出哪些新东西。两者相互验证,能产生高效且有效的解决方案。可以预期,把知识图谱和LLMs整合应用于多样的下游应用,会越来越受关注。
四、个人思考补充
1. 知识图谱构建这件事,说起来容易做起来难。结构化知识之所以易于推理,是因为它有一套完整设计的结构或规则。做图谱其实就是做数据——对错综复杂的文档数据进行有效的加工、处理、整合(数据定义、数据挖掘、数据清洗、数据评估),转化成简单清晰的三元组。整个流程长,成本低不了。而且它对领域知识要求极高,不同领域之间基本没法迁移,得case by case来做。
2. LLM和KG从某种意义上说都是一种知识库。它们在实时性和时效性上面临的挑战是一致的——知识怎么及时更新。这个老问题,在两种技术路线下都悬而未决。