当前具身智能领域的VLA(Vision-Language-Action)赛道,说实话有点“乱”。不同团队用的动作解码范式千差万别,数据管线高度耦合,评测协议也互不兼容。想横向对比?很难。想复现别人结果?成本高得离谱。而开源项目StarVLA没有去堆算力或者盲目刷榜,而是从系统抽象层面下手,搞了一套Backbone-Action Head的“乐高式”统一架构,直接切中痛点。
尽管VLA模型已经成为具身通用智能的主流范式,但学术研究正面临三重“巴别塔”困境:
架构割裂:自回归离散Token化、并行连续回归、流匹配去噪、双系统推理……不同动作解码范式背后是完全不同的代码实现和接口假设。
管线强耦合:现有开源框架大多是“单方法定制”,数据预处理、训练循环、评测协议深度绑定,模块根本没法跨项目复用。
评测标准不一:各论文只在互不相交的基准子集上报告结果,预处理和推理协议不透明,想公平对比几乎不可能。
这种碎片化状态,严重拖慢了具身基础模型的迭代节奏。
香港科技大学开源的StarV项目,核心洞察其实很直接:VLM-based与World-Model-based并不是根本对立的范式,它们本质上是在同一策略框架下,采用不同辅助学习信号(L_aux)的变体。基于这个认识,团队搭建了一个高度模块化、接口统一的开源底座,让研究者能像搭乐高一样自由组合主干网络和动作头,在完全受控的条件下验证单一设计变量的影响。

开源地址:https://github.com/starVLA/starVLA
项目主页:https://starvla.github.io
论文链接:https://arxiv.org/abs/2604.05014

架构解码,Policy-Centric的“乐高”抽象
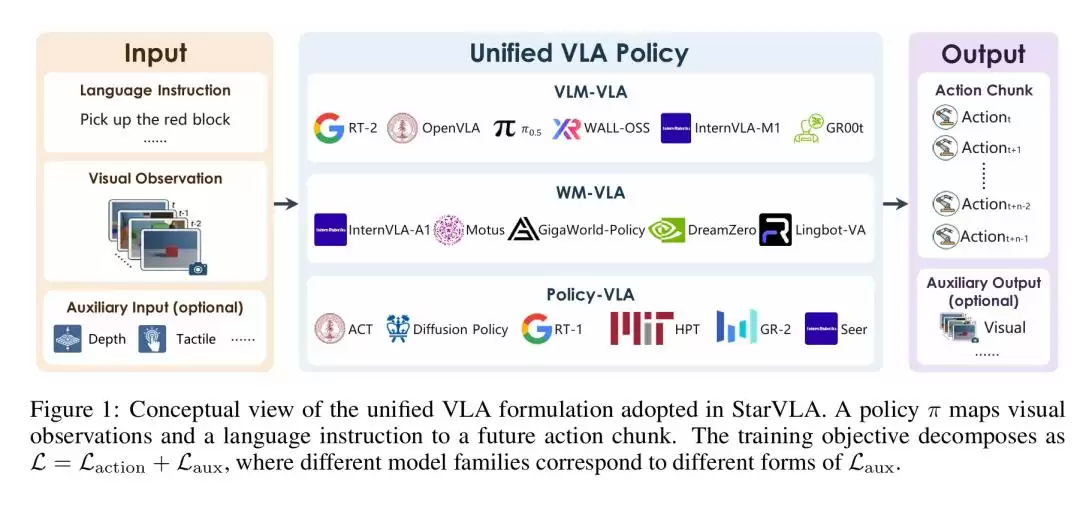
StarVLA在系统层引入了一个统一的策略中心公式,把多模态观测、语言指令和未来动作块全部映射到同一个计算图中:
其中
为多模态历史观测,ℓ为语言指令,
为预测的动作块,
为可选的辅助输出(如未来视觉帧、空间推理文本等)。训练目标被统一分解为:
其中Direct VLA:
是纯动作监督;VLM-based VLA则引入语言对齐辅助目标(如子任务规划、空间grounding);WM-based VLA则是把未来观测预测作为辅助目标或隐式先验。
在这一抽象下,StarVLA实现了双向模块化(Bidirectional Modularity):
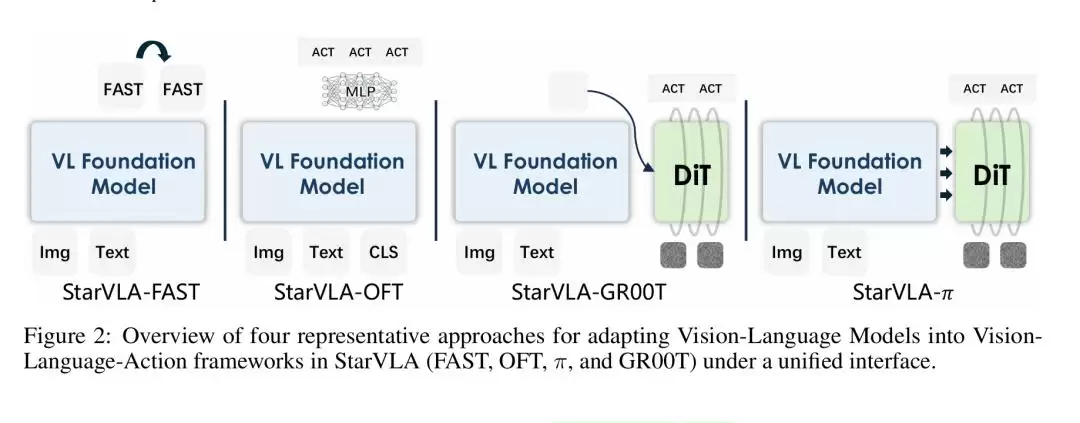
可插拔Backbone:支持Qwen3-VL、InternVL等指令微调VLM,以及Cosmos-Predict2等世界模型,只需轻量适配层即可接入统一表示契约。
可插拔Action Head:内置4种代表性动作解码器,共享同一forward()与predict_action()接口:
StarVLA-FAST:自回归离散Token生成
StarVLA-OFT:轻量MLP并行连续回归
StarVLA-π:层间Cross-DiT流匹配去噪
StarVLA-GR00T:System 2(慢推理)+ System 1(快动作)双系统架构
所有变体共享同一数据接口、训练循环与评测管线,只需替换Backbone或Action Head即可完成范式切换。这就彻底消除了跨方法对比时那些“隐性变量干扰”。
训练范式,从单基准微调走向多模态协同

StarVLA把训练策略抽象成与架构解耦的可复用配置,支持三大核心范式:
1. 行为克隆监督微调(SFT)
提供完整的分布式训练脚本(Accelerate + DeepSpeed ZeRO-2),支持全参数微调与子模块冻结。优化器采用多参数组独立学习率、bfloat16混合精度与余弦衰减调度,确保异构组件训练稳定。
2. 多目标协同训练(Co-Training)

纯动作微调很容易让VLM主干出现“灾难性遗忘”。StarVLA内置了双数据流协同机制:交替执行VLA动作前向与VLM语言建模前向,通过trainer.loss_scale.vlm动态平衡动作学习与多模态表征保留。实验表明,协同训练能显著提升空间grounding能力,在WidowX与Google Robot上带来4%~10%的成功率增益。
3. 跨形态混合训练(Cross-Embodiment)
通过LeRobotMixtureDataLoader,用户可以在YAML中声明任意机器人数据集组合与采样权重,框架自动处理动作空间对齐与形态标签追踪。这一设计让“跨形态预训练”从定制脚本变成了标准化配置。
评测与部署,Server-Client架构打通Sim2Real
为了避免benchmark依赖污染模型环境,StarVLA采用轻量级WebSocket Server-Client评测抽象:
模型侧只需暴露predict_action()接口,加载checkpoint后启动策略服务。
评测侧(如LIBERO、SimplerEnv、RoboTwin 2.0等最新环境)通过独立Client封装观测字典,用msgpack通信,返回归一化动作。
真实机器人部署无需修改任何代码:只需将机器人控制器替换为Client,提供相同格式的相机观测与指令,即可无缝迁移至物理世界。
目前已经集成了7大主流基准(含LIBERO、SimplerEnv、RoboTwin 2.0、RoboCasa-GR1、BEHA VIOR-1K、CALVIN等),并附带完整的benchmark-specific adapter,实现动作反归一化、Chunk拆分、Delta/Absolute转换等后处理逻辑。
性能与效率,极简配置下的强泛化证明
StarVLA刻意避开了复杂的数据工程与在线优化(比如DAgger),仅用公开的VL预训练权重在基准最新演示集上微调,就达到了极具竞争力的性能:
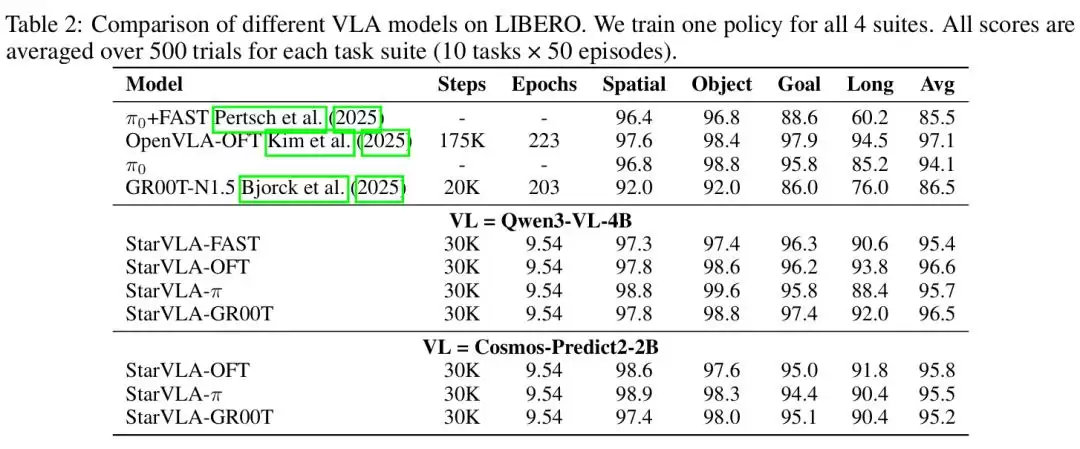

更关键的是,Backbone替换几乎不损失性能:把Qwen3-VL-4B换成Cosmos-Predict2-2B,LIBERO平均分仍然稳定在95.2%以上,这验证了架构的泛化鲁棒性。
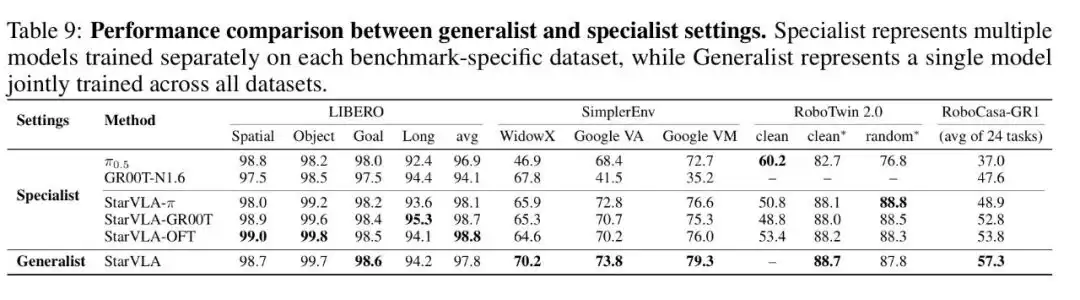
在跨基准Generalist设置中,单模型联合训练LIBERO + SimplerEnv + RoboTwin 2.0 + RoboCasa-GR1,RoboCasa平均成功率从Specialist最优的48.8%提升到了57.3%,证明了一体化训练在统一管线下的可行性。
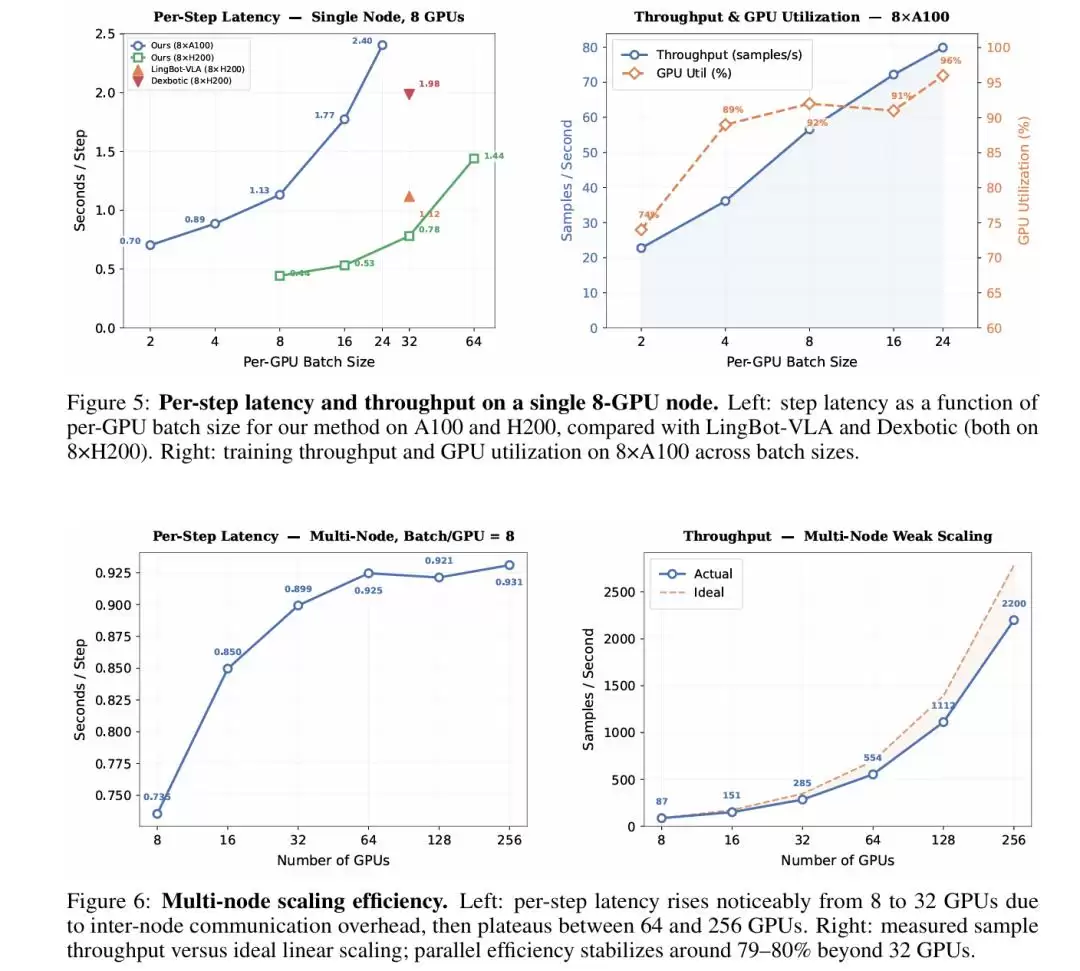
计算效率方面:在8×A100单节点上测试,Per-GPU Batch Size=8时GPU利用率达到92%,样本吞吐量56.6 samples/s;扩展到256 GPU多节点时,通信开销仅在8→32 GPU阶段有一次跃升(0.735s→0.899s/step),之后稳定在约0.93s,并行效率维持在79%~80%,为大规模分布式训练提供了清晰的Scaling Guide。
总结与展望
StarVLA的价值在于,它为具身智能社区提供了一套可复现、可对比、可组合的基础设施标准。它用工程化的克制——统一I/O契约、声明式YAML配置、Server-Client解耦——加上理论上的洞察(L = L_action + L_aux的策略统一视角),终结了VLA研究的“巴别塔”时代。
对于研究者,它是验证新动作头或新主干的即插即用沙盒;对于工程师,它是从仿真到真实机器人零代码修改的部署底座;对于社区,它是降低复现门槛、推动标准化评测的公共品。
参考资料:https://arxiv.org/abs/2604.05014




