从日常的外卖点单就能感受到,这个行业早已不只是送餐那么简单了。生鲜零售、同城跑腿、社区团购……各种场景都在往里装。对于开发团队来说,怎么造出一个能扛住高并发、高可用、还能随时扩展的外卖平台,已经成了系统设计里头绕不开的硬骨头。
外卖平台的核心业务分析
简单来说,一个完整的外卖平台,牵涉到的角色不少:用户、商家、骑手,再加上平台运营方。
业务流程的主干看着并不复杂:
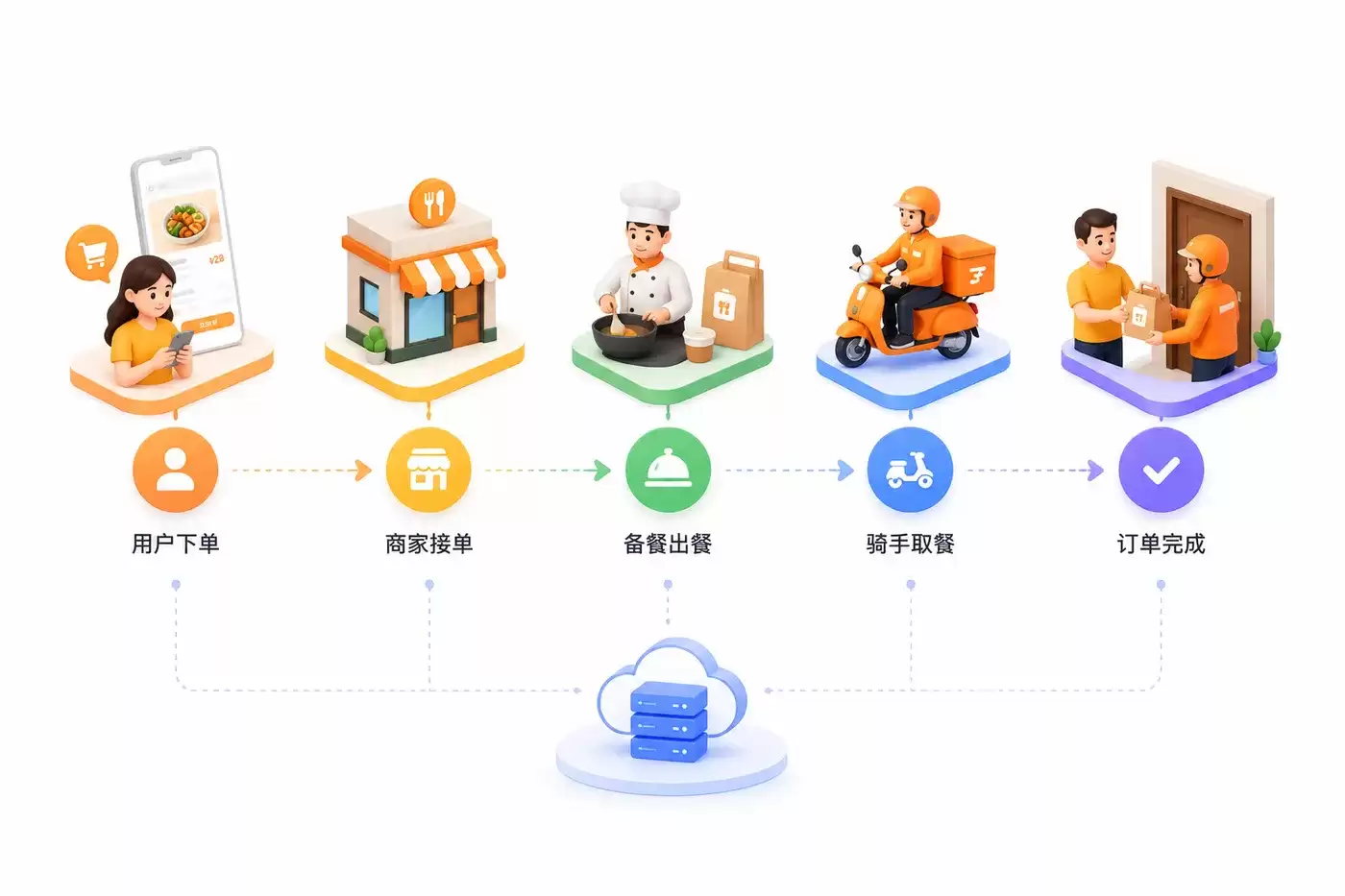
用户下单 → 商家接单 → 平台派单 → 骑手配送 → 用户确认收货 → 订单完成
但别被这条线骗了。看似简简单单的一串操作,背后是大量系统在协同作战。比如订单创建、库存扣减、支付回调、配送调度、消息通知、数据统计……一个都不能少。
所以,拿单体架构来扛这么重的活,后期业务一涨,基本就撑不住了。

为什么选择微服务架构?
项目初期,用Spring Boot搭个单体应用快速上线,这事儿常见。但业务规模一大,问题就来了:
首先是模块耦合得厉害。订单、支付、用户、商品全挤在一个工程里,改哪儿都怕牵连整体。然后是扩容成本高——订单模块压力大了,没法只给订单模块扩容,得把整个应用服务器一起扩。最后是部署效率低,一次功能更新就要重新发布整个项目,既拖慢节奏,也影响稳定性。
这就是为什么成熟的系统都会转向Spring Cloud微服务。把业务拆开,各管各的。
微服务架构设计方案
根据外卖业务的特点,可以把系统拆成这么几个核心服务:
用户服务(User Service)——负责用户注册、登录认证、地址管理、信息维护。
商家服务(Merchant Service)——负责商家入驻、店铺管理、商品管理、营销活动。
订单服务(Order Service)——负责创建订单、状态流转、退款处理、订单查询。这个模块通常是访问量最高的。
支付服务(Payment Service)——负责微信支付、支付宝支付、回调处理、对账管理。事务一致性是必须保证的。
配送服务(Delivery Service)——负责骑手管理、自动派单、配送轨迹、运力调度。
消息中心(Message Service)——负责信息通知、App推送、站内消息、邮件通知。靠消息解耦来降低系统耦合度。
服务治理体系设计
在Spring Cloud体系里,服务治理是微服务稳定运行的底座。核心组件包括:
Nacos注册中心——搞定服务注册、服务发现、配置管理,避免地址硬编码。
Gateway网关——统一入口管理,负责权限认证、限流控制、日志记录、请求转发,提升安全性。
OpenFeign远程调用——实现服务之间的通信。比如订单服务调用商品服务扣库存,或调用配送服务派单。开发接口的复杂度大大降低。
Redis缓存优化策略
外卖平台最明显的特征就是高并发,尤其是午高峰和晚高峰。数据库压力会急剧增加,必须想办法顶住。
常用的缓存方案包括:
热门商家缓存——把热门店铺信息丢进Redis,减少数据库查询压力。
商品列表缓存——商品详情是高频访问数据,天然适合缓存。
用户会话缓存——登录状态统一存在Redis里,方便分布式部署。
缓存架构优化好,数据库的QPS压力能明显降下来。
RabbitMQ实现异步削峰
订单高峰的时候,大量同步操作会把系统搞堵。举个例子,用户支付成功后,后台要更新订单状态、扣减库存、生成配送任务、推送通知……如果全同步执行,接口响应时间会明显拉长。
这时候通常用RabbitMQ做异步处理。支付成功后,订单服务只负责发一条消息,后续业务由消费者异步去执行。这样做的好处很直接:流量削峰、系统解耦、响应速度更快。
数据库设计优化
订单表是整个系统最核心的数据表。常见的字段包括:order_id、user_id、merchant_id、rider_id、order_status、pay_status、total_amount、create_time。
订单量一上来,单表性能就会开始下降。常见的应对方法有:
建立合理索引——比如user_id索引、merchant_id索引、create_time索引,能明显提升查询效率。
分库分表——订单量到了千万级甚至更高的时候,可以考虑用ShardingSphere或MyCat做水平拆分,提高数据库的吞吐能力。
云原生部署实践
现在越来越多项目选择容器化部署。推荐的技术栈是:Docker + Kubernetes + Jenkins + Harbor。
带来的好处很实在:
自动化发布——代码提交后自动构建镜像。
弹性扩容——高峰期自动增加Pod实例,低峰期自动缩容,省资源。
故障自愈——容器异常退出自动重启,系统可用性大幅提升。
高并发场景下的性能优化思路
真要面对百万级订单,有几个问题需要重点盯住:
缓存穿透——用布隆过滤器把非法请求挡在外面。
缓存击穿——热点数据加互斥锁保护。
缓存雪崩——用随机过期时间策略分散风险。
数据一致性——通过MQ最终一致性方案来解决。
服务限流——利用Sentinel做熔断降级,防止系统崩盘。
总结
外卖平台说到底就是一个典型的高并发互联网系统。业务在涨,单体架构迟早撑不住。采用Spring Cloud微服务架构,再配合Redis缓存、RabbitMQ消息队列、Nacos服务治理以及Kubernetes容器化部署,能有效提升系统的可扩展性、稳定性和运维效率。对开发团队而言,技术架构的选择不仅影响当下的开发节奏,更决定了系统未来的天花板。提前把服务拆分、缓存设计和云原生部署方案规划好,后面业务增长起来,才能站得稳。




