提升LLM Agent性能表现,通常意味着更换更强大的模型、进行指令微调、强化学习或知识蒸馏。这些方法固然有效,但在许多垂直领域任务中,智能体(Agent)的失败根源往往并非模型能力不足。
北京大学研究团队发现,大量错误实际上发生在模型与外部环境的连接关口——当Harness工程的任务完成后,Environment工程的价值便凸显出来。
具体而言,常见的失败情形包括:模型大致知道需要执行什么操作,却未能正确调用工具;动作意图本无误,但生成的JSON、函数名称、参数或SQL格式无法被环境正确解析和执行;环境已经返回错误反馈,但模型未能触发有效的恢复机制;智能体在轨迹中反复搜索、点击、尝试,直至耗尽预设的步骤预算(step budget)。
这些现象表明,Agent 不能仅仅被视为一个大型语言模型(LLM)。它更像一个运行时系统:模型需要观察环境、理解工具、提交动作、接收反馈,并在多轮交互中持续做出决策。最终的性能不仅取决于模型参数,更取决于模型与环境之间的运行时接口(runtime interface)。
Adapting the Interface, Not the Model. 不修改模型,而是适配模型与环境交互的运行时接口——这正是该论文的核心原则。

基于这一洞察,北京大学的学者提出了LIFE-HARNESS 框架。
LIFE-HARNESS:从训练轨迹中演化运行时接口
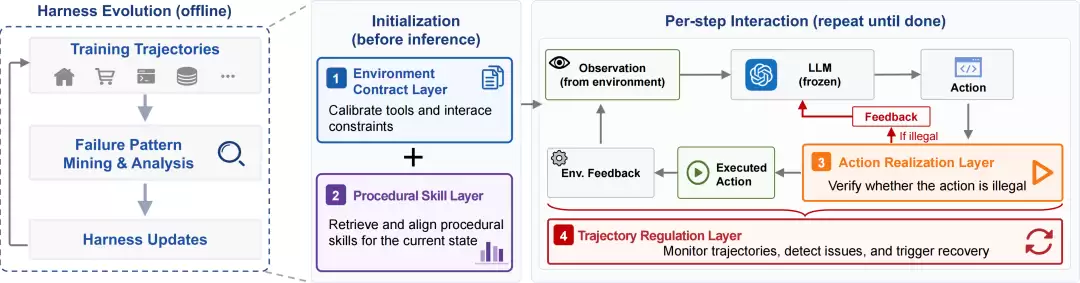
LIFE-HARNESS 不更新模型权重,也不修改评测环境,而是从训练轨迹中挖掘可复用的失败模式,并将其转化为运行时干预机制。该框架包含四层设计:
1. Environment Contract Layer
在交互开始之前,明确界定工具使用规则、动作交互协议、答案格式要求、环境约束条件以及常见的陷阱。这一层的目标是让模型首先理解:在这个具体环境中,我应该如何正确地行动?
2. Procedural Skill Layer
许多垂直领域任务都具备稳定的“操作流程”。例如,购物Agent通常遵循搜索、筛选、对比、购买的步骤;数据库任务则需先定位表和字段,再构造查询并验证结果。这类过程性经验可以从训练轨迹中提取出来,在新任务启动时检索并提供给模型。这相当于为模型提供了一份可复用的任务攻略:遇到类似场景时,可以参考历史成功轨迹中的有效操作路径。
3. Action Realization Layer
模型想对了,并不代表动作一定能被环境执行。例如,模型本应调用工具,却输出了自然语言描述;或者生成的JSON缺少必要字段、参数类型错误、函数名拼写有误,导致环境无法解析。Action Realization Layer 就像一个动作质量检查器,在动作提交给环境执行前,先对其进行校验和修正。它关注的是:模型意图执行的操作,能否真正转化为环境可执行的指令。
4. Trajectory Regulation Layer
Agent 的失败也可能发生在整条轨迹的层面。模型可能陷入重复搜索、反复点击、持续执行无效动作的循环,或者在收到错误反馈后依然沿着错误方向尝试。Trajectory Regulation Layer 会实时监控这类重复、停滞以及无效恢复的信号,并在必要时触发纠偏提示。其作用是:当轨迹开始陷入循环时,将模型及时拉回到有效的探索路径上。
实验结果:平均相对提升 88.5%
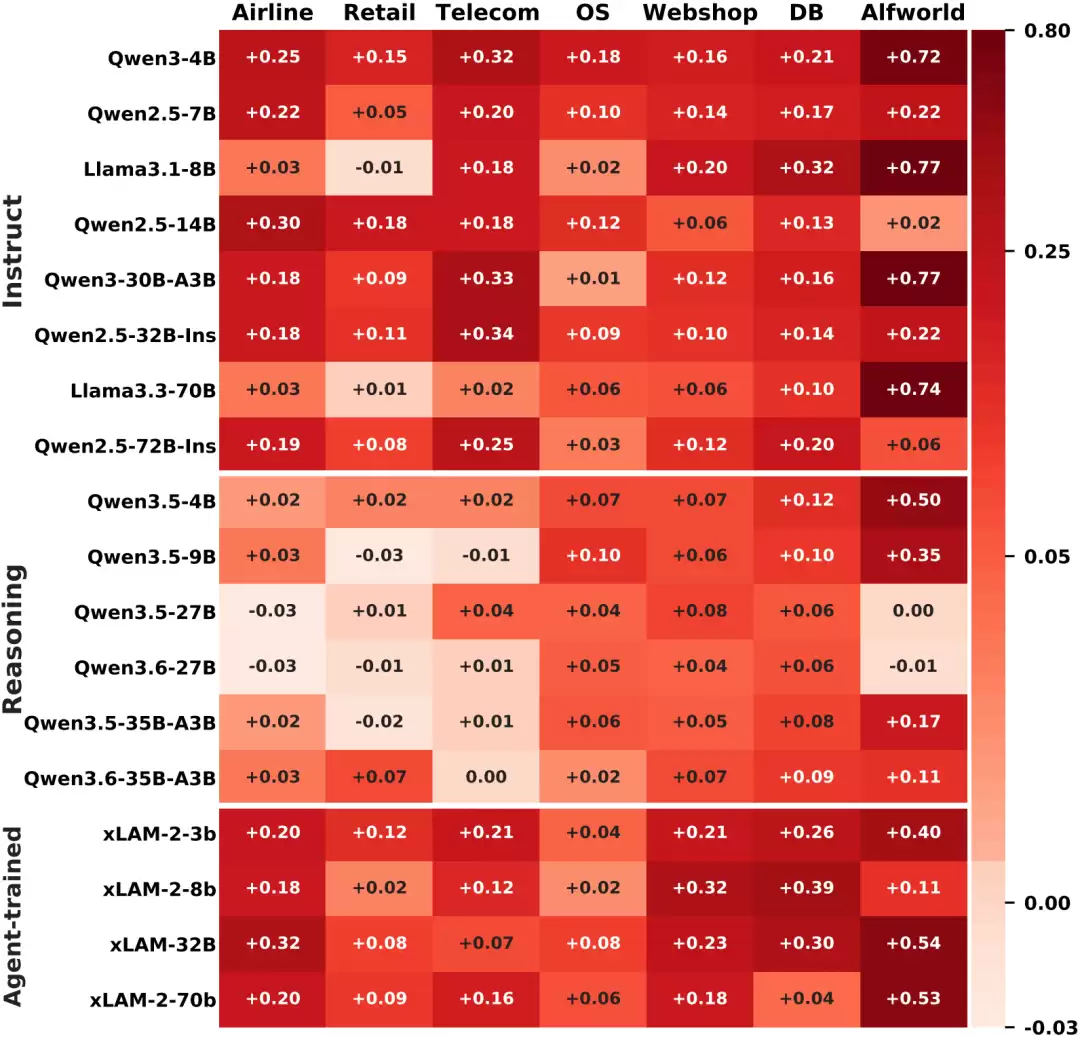
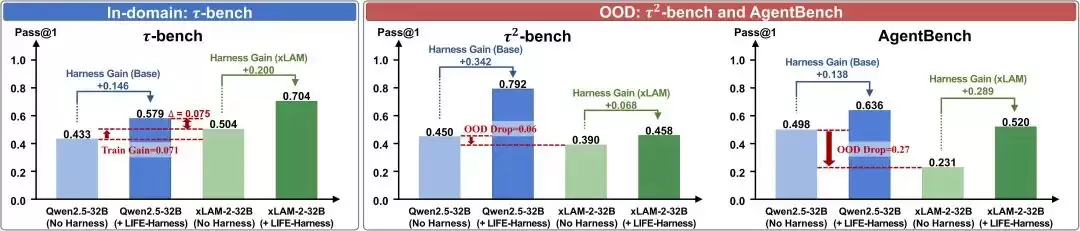
研究团队在三个基准测试套件(benchmark suite)上评估了LIFE-HARNESS的性能:τ-bench、τ²-bench和AgentBench,实验覆盖了7个确定性Agent环境。在模型方面,评测了18个不同的主干网络(backbone),包括指令微调模型、推理模型以及经过特化训练的Agent模型。
结果显示:在116 / 126个模型-环境组合中,LIFE-HARNESS 带来了性能提升,平均相对提升幅度达 88.5%。
更值得注意的是,这个运行时接口的演化过程仅使用了Qwen3-4B-Instruct的训练轨迹,但最终却能成功迁移到另外17个不同的模型上。这说明LIFE-HARNESS所习得的并非某个特定模型的特殊行为,而是环境中稳定存在的结构性知识:如工具协议、任务流程、典型错误模式以及恢复策略。
Harness 和模型训练是什么关系?
LIFE-HARNESS 并非要取代模型训练。模型训练本身依然至关重要。但在确定性垂直领域的Agent任务中,许多失败源于接口层面的错配,而非模型本身的能力缺失。实验中,研究团队发现即使是经过工具使用训练的专用Agent模型,在引入LIFE-HARNESS后仍能获得持续的性能提升。这表明,工具使用训练并不能完全消除来自接口层、动作层和轨迹层的失败风险。
换言之:模型训练提升的是模型本身的能力,而运行时接口(runtime harness)改善的是模型与外部环境之间的交互条件,二者是互补关系,相辅相成。
总结
LIFE-HARNESS 试图回答一个核心问题:能否在不更新模型权重的前提下,仅通过适配运行时接口来提升确定性LLM Agent的性能?实验结果表明,在规则明确、反馈可复现的垂直领域Agent任务中,这一方法是可行的。
Agent的适配优化不一定只能发生在模型内部,也可以发生在由观察、工具、动作、反馈和轨迹控制共同组成的运行时系统中。当一个垂直领域Agent表现不佳时,也许第一步不总是重新训练模型,而是先问一句:这个问题真的非要改模型不可吗?还是说,只需把模型与环境的接口适配得更顺畅即可?
论文链接:https://arxiv.org/pdf/2605.22166
题目:Adapting the Interface, Not the Model: Runtime Harness Adaptation for Deterministic LLM Agents
单位:北京大学
代码:https://github.com/Tianshi-Xu/Life-Harness