我的世界成AI新考场 高三生评测DeepSeek-R1列第三
时间:2026-06-26 16:53
MC-Bench利用《我的世界》游戏环境评测人工智能,相较于传统方法更直观安全,能测试自主推理与规划的能力。目前Claude3 7Sonnet排名第一,DeepSeek-R1位列第三。该项目仅由八名志愿者运营,获得了多家大型人工智能公司支持。
诚如 Adi Singh 所言,MC-Bench 相较于传统 AI 评测更加直观,也能更真实地反映人工智能在实际场景中的表现。最关键的是,游戏环境提供了一个安全可控的测试空间,有助于深入研究 AI 的推理与规划能力:“游戏或许可以成为检验‘自主推理能力’的媒介,比现实世界的测试更安全、更易控制,因此我认为这是一种更理想的方案。”
那么,相较于传统 AI 评测方式,游戏化路径究竟赢在哪里?归根结底,传统方法如今已经难以全面衡量大模型的实际水平,而游戏化评测具备多个独特优势:
首先,游戏通常包含多层次挑战,能够考验 AI 的问题解决、策略思维与适应能力,这模拟了现实世界的复杂性。其次,在游戏环境中,AI 需要独立做出决策,而非仅执行预设任务,这有助于评估其自主决策能力。再者,游戏提供了可重复测试的环境,可以在相同条件下对比不同 AI 的表现。最后也是最重要的一点是安全性——与直接部署到现实世界相比,游戏环境为 AI 评测提供了一个更安全的试验场。
基于这些判断,Adi Singh 的观点十分明确:游戏化评测有望成为未来 AI 评测的重要趋势。它不仅让 AI 研究变得更有趣,也让普通人能够更直观地理解 AI 的发展水平。
而他之所以选择《我的世界》作为评测对象,很大程度上是因为其广泛的知名度——毕竟,这是全球销量最高的电子游戏之一,即使是不玩游戏的人,也能直观地判断哪个方块版的“酒杯”更符合实际。除此之外,还有几个关键原因:
一是全球用户群体庞大。《我的世界》全球拥有上亿玩家,可以轻松吸引大量用户参与 AI 评测,形成众包数据。二是易于理解和评判。相比代码输出或文本生成,视觉化的建筑作品更容易让普通用户参与评测——你无需懂编程,也能看出哪座建筑更具创意和写实感。三是能测试 AI 的复杂能力。建造建筑不仅考验 AI 的生成能力,还涉及逻辑推理、规划、空间认知等维度,而传统 AI 评测很难全面覆盖这些方面。
其实,从技术角度看,MC-Bench 也是一个编程基准测试,因为 AI 模型需要编写代码来完成建造任务,例如“堆雪人”或“在宁静的沙滩上建造一座迷人的热带小屋”。只不过,它通过视觉化方式降低了参与门槛,使得任何人都能轻松参与 AI 模型的评测。这种方式不仅增加了项目的吸引力,也为收集关于 AI 性能的数据提供了新途径。
大型 AI 公司支持,8 名志愿者推动
目前,MC-Bench 是一个公开网站,任何人都可以访问、评判 AI 生成的作品,并给出自己的投票数据。根据官网信息,其团队仅由 8 名志愿者组成,负责日常的开发和维护工作:
此外,Anthropic、Google、OpenAI 和阿里巴巴等大型 AI 公司提供了模型访问权限用于基准测试,但与该项目并无官方合作关系:

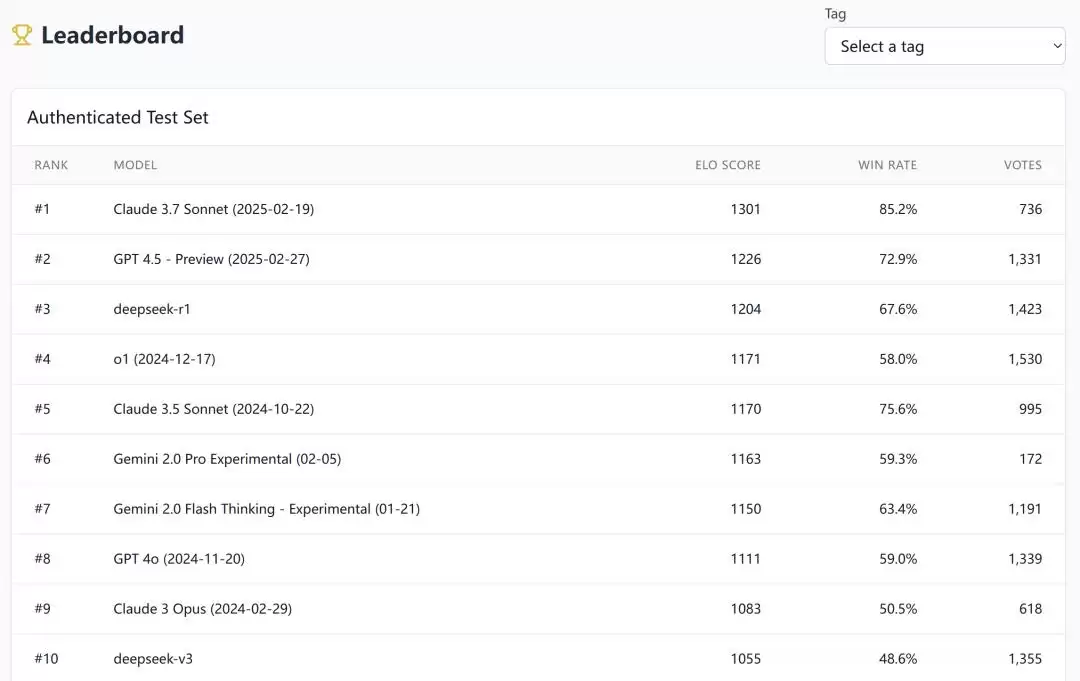
从 MC-Bench 官方给出的胜率最高的 Top 10 大模型名单来看,Claude 3.7 Sonnet 目前位居第一,而近来爆火的 DeepSeek-R1 排在第三名。
当前,MC-Bench 主要测试基础建造能力,以评估 AI 从 GPT-3 时代发展至今的进步。至于未来规划,Adi Singh 透露,他计划拓展到更复杂的任务,比如长期规划和目标导向型任务。他还补充说,MC-Bench 的排行榜与他的个人体验高度一致,说明该平台确实能为用户提供有价值的见解。
也许,未来的 AI 评测方式不再是刷题,而是通过“玩游戏”来评估——你觉得这种方式靠谱吗?




