该消息发布后,迅速引发网友热议,大家纷纷开始畅想下一代AI架构的形态。


那么,这个被称为CoE的创新架构究竟有何来历?研究团队在其Notion博客中做了详尽阐述。
CoE:专为稀疏MoE架构量身设计
简而言之,CoE的核心突破在于为稀疏MoE引入了一套高效的“通信机制”,彻底改变了信息在稀疏神经网络中的传递与流转方式。
其实现思路非常直接:在单个层内,将MoE的输出反复作为下一次迭代的输入,使信息在连续迭代中不断传递、累积并优化。
用公式表示CoE的迭代处理机制,大致如下所示:

他们借鉴了DeepSeek-V2的实现方式,门控机制的定义如下:

这种设计带来的优势十分明显:每次迭代需要选择哪些专家,完全由上一轮输出的结果动态决定。如此一来,专家之间不再是“各自为政”,而是形成了紧密的依赖关系与灵活的动态路由。串行处理的信息在迭代过程中不断累积,最终实现了专家之间的直接通信——这正是整个架构的关键所在。
团队以DeepSeek V2架构为实验基础,在500M参数的MoE模型上,使用32K Tok的batch size训练了1000步,以验证CoE的实际效果。结果相当亮眼:CoE在性能表现、扩展策略、资源效率优化、专家组合自由度以及整体使用效率上,均展现出显著优势。
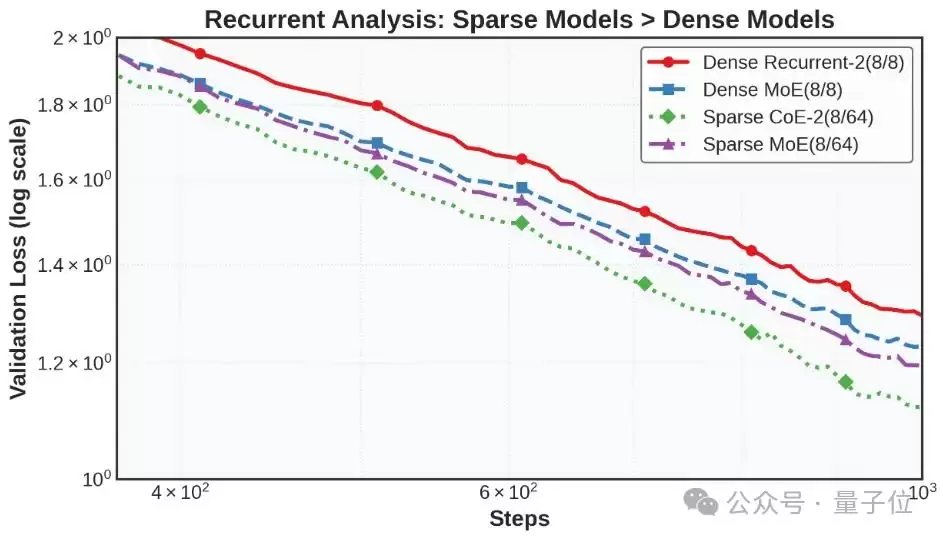
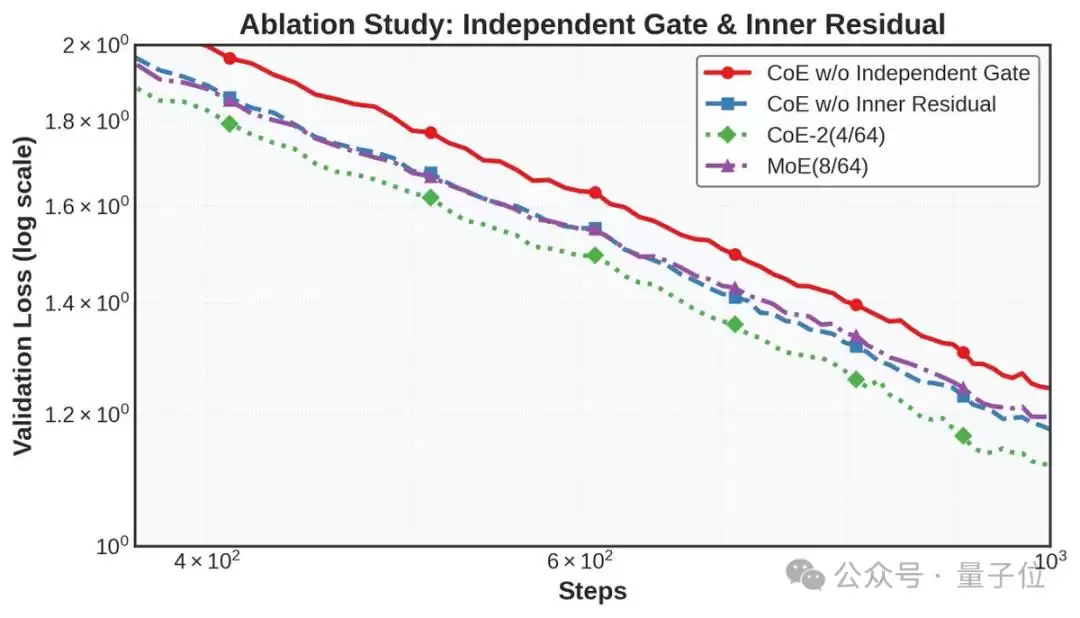
除了开头那张图显示的,在算力和内存要求相近的前提下,CoE将loss从1.20显著拉低至1.12,且下降趋势更为迅猛。
更有意思的是,他们还在“密集”模型(即专家8选8)上进行了相同实验,结果证实串行处理在稀疏MoE上远比在密集模型中更有效。CoE确实是专门为稀疏混合专家模型量身定制的一套方法。对于密集模型而言,执行两次序列化处理带来的性能提升几乎可以忽略不计。
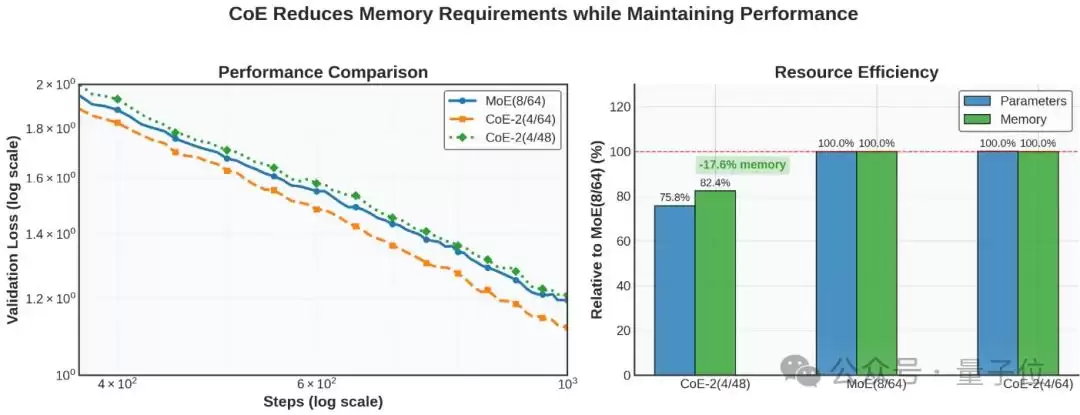
此外,在计算量和最终性能相近的情况下,CoE还能有效“节省内存”。例如,CoE-2(4/48)的效果能够与MoE(8/64)持平,但所需的专家总数大幅减少。在loss相当的前提下,内存需求直接降低了17.6%。
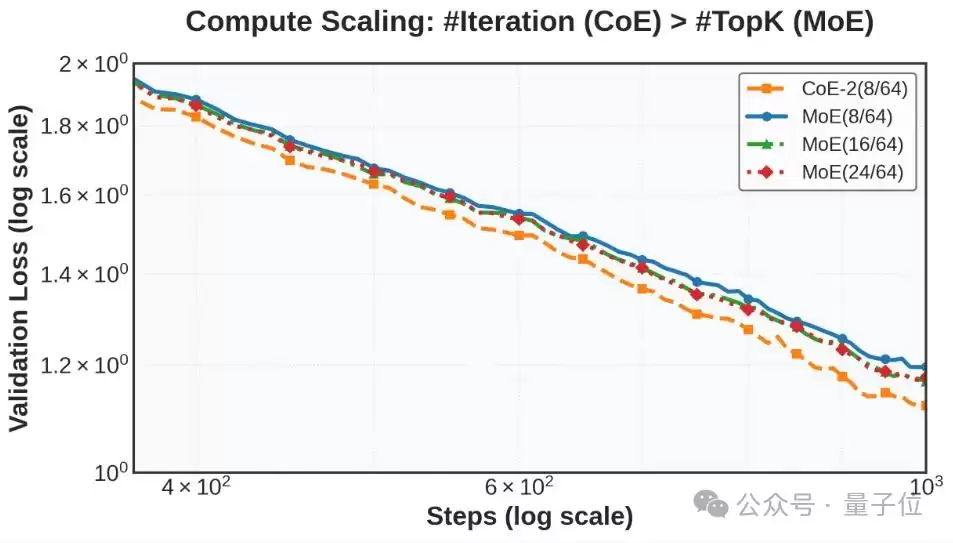
团队还做了一个极具价值的对比:在预算相似的情况下,究竟是扩展CoE的迭代次数更划算,还是扩展模型的层数或专家选择个数更优?结果非常清晰:扩展CoE迭代次数是更具优势的选择。
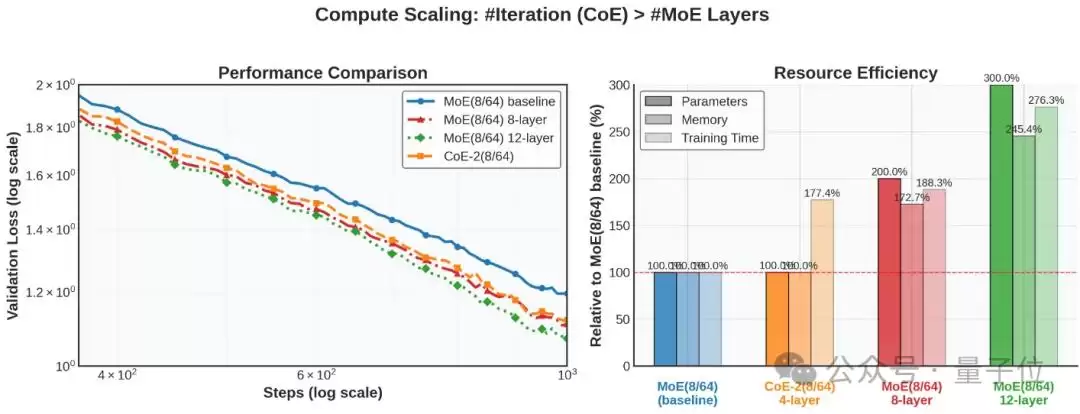
再举一个例子:CoE-2(8/64),4层模型对比MoE(8/64),8层或12层模型。8层的MoE与CoE效果几乎一致,但MoE对内存的要求却高出72%。换算下来,CoE相当于节省了42%的内存。
团队特别强调,独立的门控机制以及内部的残差连接,是CoE最核心的架构创新。消融实验的结果也充分佐证了这一点:移除任何一个关键组件,都会导致性能出现断崖式下跌。
如果想了解更详尽的技术细节,建议直接查阅他们的技术报告原文。
研发团队是谁?
CoE项目由一支5人小团队共同打造。

核心成员Zihan Wang是美国西北大学计算机科学专业的博士生,本科毕业于中国人民大学高瓴人工智能学院。他的研究方向主要集中在大模型自主性、效率以及长上下文理解等领域。

这位Zihan Wang曾任职于DeepSeek,是ESFT(Expert-Specialized Fine-Tuning)论文的第一作者。ESFT的思路是只调整MoE中与特定任务相关的部分,从而在降低资源和存储消耗的同时,高效实现模型定制化调整,提升整体效率与性能。

值得一提的是,CoE并非Zihan Wang首次围绕DeepSeek开发“衍生架构”。此前,他还基于verl复现了DeepSeek-R1(-Zero)框架,命名为RAGEN(Reinforcement learning AGENt),该项目在GitHub上已获得近1k星标。
Zihan Wang的导师是Manling Li,她是西北大学计算机科学系的助理教授,此前曾在吴佳俊教授的指导下工作,并获得过李飞飞教授的指导。
另外,在RAGEN的贡献者名单中,也能看到Manling Li、吴佳俊以及李飞飞的名字。





