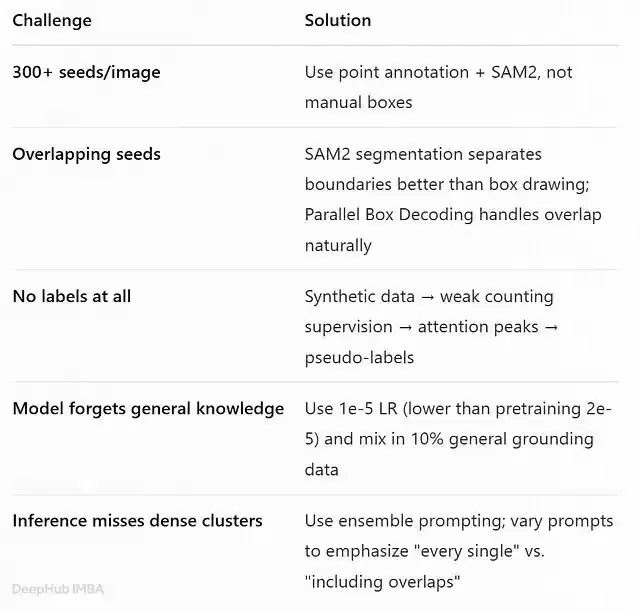
想象一下这样一个场景:你手头有一批种子发芽托盘、谷物质检图像,或者植物学调查的样本照片。每张图像里密密麻麻挤着100到500粒种子,它们互相重叠、彼此遮挡,而你的老板或导师要求模型能精准定位每一粒。这事儿听起来就让人头大,不是吗?
问题在于,要在每张图像里手动给三百个互相重叠的目标画精确的边界框,人工标注这条路根本走不通。算一笔账就清楚了——标注一个框大约5秒钟,处理一张图就要花掉25分钟;要是有一千张图,光是标注就得耗上超过400个小时,这显然不现实。
那么,有没有更聪明的解法?本文就来聊聊如何借助NVIDIA的LocateAnything-3B——一个支持并行框解码的视觉语言定位模型——搭配一套半监督流水线,把人工标注量压缩到最低。
为什么选择LocateAnything-3B?
市面上大多数视觉语言定位模型,像Grounding DINO或OWL-ViT,走的是自回归路线,一个Token一个Token地生成边界框。如果要检测300个目标,速度会慢到让人难以忍受。而LocateAnything-3B采用了一种叫并行框解码的技术,一次性并行输出完整的边界框,而不是逐Token生成。这就让它在处理成百上千个目标的密集场景时,效率优势非常明显。
它的核心构成如下:
- 基础语言模型:Qwen2.5–3B-Instruct
- 视觉编码器:MoonViT
- 解码方式:并行块级预测,非自回归
- 许可证:NVIDIA开放模型许可
整体策略:四步走
整个方案分为四个阶段,本质上是一条半监督流水线:
- 先做最少量点标注,而非框标注
- 用SAM2从点生成初始边界框
- 在合成数据和伪标签数据上训练一个轻量检测器
- 对全部未标注数据生成伪标签,再用高置信度的伪标签配合特定训练策略微调LocateAnything-3B
阶段一:最少量标注——点转框
点击目标的中心点,速度比画边界框快大约10倍。标注300粒种子,打点只需大概5分钟,而画框需要25分钟左右。这笔账怎么算都划算。
具体操作是这样的:用SAM 2(Segment Anything Model 2)把每个点击点扩展成分割掩码,再从掩码反推出边界框。
先安装依赖:
pip install sam2 torch torchvision transformers opencv-python点转框的流水线实现如下:
import cv2
import numpy as np
import torch
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
from PIL import Image
# 加载 SAM2
checkpoint = "./checkpoints/sam2.1_hiera_large.pt"
model_cfg = "configs/sam2.1/sam2.1_hiera_l.yaml"
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
def points_to_boxes(image_path, seed_points):
"""
Args:
image_path: 原始种子图像路径
seed_points: (x, y) 元组列表——每粒种子中心点击一次
Returns:
boxes: [x1, y1, x2, y2] 边界框列表
"""
image = np.array(Image.open(image_path).convert("RGB"))
predictor.set_image(image)
# 将点转换为 numpy 数组
point_coords = np.array(seed_points, dtype=np.float32)
point_labels = np.ones(len(seed_points), dtype=np.int32) # 1 = 前景
# 批量预测(SAM2 支持多点输入)
masks, scores, logits = predictor.predict(
point_coords=point_coords,
point_labels=point_labels,
multimask_output=False, # 每个点输出单一掩码
)
# 将掩码转换为边界框
boxes = []
for mask in masks:
# mask 形状:(H, W)
ys, xs = np.where(mask > 0)
if len(xs) == 0:
continue
x1, y1, x2, y2 = int(xs.min()), int(ys.min()), int(xs.max()), int(ys.max())
boxes.append([x1, y1, x2, y2])
return boxes, masks
# 使用示例
seed_points = [
(120, 340), (145, 342), (180, 338),
# ... 共 300 个点
]
boxes, masks = points_to_boxes("tray_001.jpg", seed_points)SAM2在处理边界分离的目标时表现不错。即便种子相互重叠,只要点击的是清晰可见的前景种子,它通常能正确分割出该前景目标。但如果遇到两粒种子严重粘连的情况,有几个小技巧:点击最上层种子的可见中心点,SAM2会优先分割包含该点的目标;对于那些被遮挡的种子,可以点击其可见的边缘或角落。万一SAM2把两粒相邻种子合并成一个掩码,试着把点位稍微下移再试一次,或者在提取边界框前对掩码做一次分水岭分割后处理。
阶段二:构建初始检测器
在正式接触LocateAnything-3B之前,可以先基于SAM2生成的边界框训练一个快速的YOLO11或RT-DETR模型。训练完成后,你就得到了一个专门针对种子的检测器,运行速度可以达到100 FPS,非常适合对数千张图像批量生成伪标签。
from ultralytics import YOLO
# 在 SAM2 伪标签上训练 YOLO11
model = YOLO("yolo11n.pt") # 使用 Nano 版以提升速度,可按需换用 s/m/l
# 数据格式:YOLO 需要 .txt 文件,格式为 类别 x_center y_center width height(归一化)
# 转换边界框:
def box_to_yolo_line(box, img_w, img_h):
x1, y1, x2, y2 = box
x_c = ((x1 + x2) / 2) / img_w
y_c = ((y1 + y2) / 2) / img_h
w = (x2 - x1) / img_w
h = (y2 - y1) / img_h
return f"0 {x_c:.6f} {y_c:.6f} {w:.6f} {h:.6f}"
# 训练
model.train(
data="seed_pseudo_data.yaml",
epochs=50,
imgsz=640,
batch=16,
patience=10,
augment=True,
hsv_h=0.015, hsv_s=0.7, hsv_v=0.4,
degrees=15, translate=0.1, scale=0.5,
fliplr=0.5, mosaic=1.0, mixup=0.1,
)为什么要多此一举?YOLO11训练只需要几分钟,而且每个预测都附带置信度分数。一来可以按置信度过滤伪标签,二来也能过滤掉SAM2产生的明显误检,比如背景里的杂点。
阶段三:大规模生成伪标签
接下来,把训练好的YOLO11种子检测器应用到全部未标注图像上,保留高置信度的预测结果,过滤掉噪声。
import glob
import json
from ultralytics import YOLO
model = YOLO("runs/detect/seed_yolo11/weights/best.pt")
image_paths = glob.glob("raw_images/*.jpg")
pseudo_labels = []
CONF_THRESHOLD = 0.65 # 可调整——从 0.6 开始,若噪声过多可提高至 0.75
IOU_NMS_THRESHOLD = 0.5
for img_path in image_paths:
results = model(img_path, conf=CONF_THRESHOLD, iou=IOU_NMS_THRESHOLD)
boxes = results[0].boxes.xyxy.cpu().numpy().tolist()
confs = results[0].boxes.conf.cpu().numpy().tolist()
# 可选:跳过模型置信度较低的图像(平均置信度偏低)
if len(confs) > 0 and np.mean(confs) < 0.5:
print(f"标记为待人工复核:{img_path}")
continue
# 以 LocateAnything 对话格式存储
pseudo_labels.append({
"id": img_path.split("/")[-1].replace(".jpg", ""),
"image": img_path,
"conversations": [
{"from": "human", "value": "Locate all seeds in this image."},
{"from": "gpt", "value": format_boxes_for_locateany(boxes)}
],
"meta": {"source": "yolo_pseudo", "mean_conf": float(np.mean(confs))}
})
def format_boxes_for_locateany(boxes):
"""将 xyxy 格式边界框转换为模型所需的特殊 Token 格式。"""
# LocateAnything 要求坐标归一化至 [0, 999] 并使用特殊 Token 包裹
# 具体 Token 化方式取决于 processor;此处展示逻辑结构
lines = []
for box in boxes:
x1, y1, x2, y2 = box
lines.append(f"<>{int(x1)} {int(y1)} {int(x2)} {int(y2)}<< >")
return "".join(lines)
# 保存 data
with open("data/pseudo_labels.jsonl", "w") as f:
for item in pseudo_labels:
f.write(json.dumps(item) + "\n") 在密集场景中,标准NMS(非极大值抑制)可能会过度抑制那些互相重叠的种子。这里有个替代方案:采用尺寸感知的过滤策略。如果两个框的尺寸相近,就保留重叠的框。因为种子的大小大致均匀,若一个大框和一个小框重叠,大概率是误检。

def size_aware_filter(boxes, confs, size_tol=2.0):
areas = [(b[2]-b[0])*(b[3]-b[1]) for b in boxes]
median_area = np.median(areas)
filtered = []
for box, conf, area in zip(boxes, confs, areas):
if area > median_area * size_tol or area < median_area / size_tol:
continue # 可能是误检(杂质、背景团块)
filtered.append((box, conf))
return filtered阶段四:微调LocateAnything-3B
伪标签数据准备就绪,接下来就是对主模型进行微调了。LocateAnything使用recipe JSON来定义数据混合比例。针对密集种子的场景,有必要提高密集/重叠数据的权重。
{
"datasets": [
{
"name": "seed_pseudo_dense",
"path": "data/pseudo_labels.jsonl",
"root": "data/raw_images/",
"repeat": 3,
"length": 15000
},
{
"name": "seed_sam2_verified",
"path": "data/human_verified_sam2.jsonl",
"root": "data/raw_images/",
"repeat": 8,
"length": 2000
},
{
"name": "seed_counting_captions",
"path": "data/weak_count_captions.jsonl",
"root": "data/raw_images/",
"repeat": 2,
"length": 5000
}
]
}注意人工核验数据的repeat设为8。数量虽少,但质量更高。提高重复比例可以防止模型仅仅学习YOLO的偏差。
训练脚本如下:
# 脚本位置:eaglevl/train/locany_finetune_magi_stream.py
torchrun --nproc_per_node=4 eaglevl/train/locany_finetune_magi_stream.py \
--model_name_or_path nvidia/LocateAnything-3B \
--meta_path "./recipes/seed_finetune_recipe.json" \
--output_dir work_dirs/locany_seed_sft \
--max_steps 10000 \
--learning_rate 1e-5 \
--warmup_ratio 0.1 \
--lr_scheduler_type cosine \
--bf16 True \
--block_size 6 \
--attn_implementation magi \
--max_seq_length 8192 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--sa ve_steps 2000 \
--logging_steps 10 \
--report_to tensorboard \
--deepspeed "deepspeed_configs/zero_stage2_config.json"如果显存紧张,可以用LoRA替代。LocateAnything支持use_backbone_lora和use_llm_lora参数。LoRA可以把可训练参数从大约38亿压缩到约2亿,这样一来,单张A100或两张RTX 4090上就能完成微调。
from transformers import AutoModel, AutoConfig
config = AutoConfig.from_pretrained(
"nvidia/LocateAnything-3B",
trust_remote_code=True
)
# 启用 LoRA
config.use_llm_lora = 64 # 语言模型的秩
config.use_backbone_lora = 64 # 视觉骨干网络的秩
model = AutoModel.from_pretrained(
"nvidia/LocateAnything-3B",
config=config,
trust_remote_code=True,
torch_dtype=torch.bfloat16
)进阶技巧:弱监督计数辅助定位
如果连点标注都无法提供,只有图像级别的计数(比如"这个托盘大约有320粒种子"),那该怎么办?可以通过以下方式引导定位:
def attention_peaks_to_points(model, processor, image_path, prompt, n_peaks=300):
"""
利用模型中文本('seeds')与图像 patch 之间的交叉注意力,
估计种子中心的可能位置。需要对模型进行前向 hook。
"""
image = Image.open(image_path).convert("RGB")
inputs = processor(text=prompt, images=image, return_tensors="pt").to("cuda")
# 开启注意力输出的前向传播(如模型支持)
with torch.no_grad():
outputs = model(**inputs, output_attentions=True)
# 提取视觉-语言注意力(层次相关,通常取最后几层)
attn = outputs.attentions[-1] # [batch, heads, text_tokens, image_patches]
# 对多头取均值,并对种子相关的文本 Token 求和
seed_token_indices = find_seed_tokens(inputs.input_ids, processor)
seed_attn = attn[:, :, seed_token_indices, :].mean(dim=2) # [batch, heads, patches]
# 重塑为空间网格(MoonViT 使用合并后的 patch,448px 下约为 24x24)
H = W = 24
attn_map = seed_attn.mean(dim=1).reshape(H, W).cpu().numpy()
# 寻找局部极大值
from scipy.ndimage import maximum_filter
local_max = (attn_map == maximum_filter(attn_map, size=3))
peaks = np.argwhere(local_max)
# 将 patch 索引转换为图像坐标
img_w, img_h = image.size
points = [(p[1] * img_w / W, p[0] * img_h / H) for p in peaks[:n_peaks]]
return points这些注意力极值点可以作为伪点输入阶段1的SAM2。虽然这个结果存在一定噪声,但配合NMS和置信度过滤,理论上足够为整个流水线提供初始数据。
使用微调后的模型进行推理
from transformers import AutoModel, AutoProcessor
import torch
model = AutoModel.from_pretrained(
"work_dirs/locany_seed_sft/checkpoint-10000",
trust_remote_code=True,
torch_dtype=torch.bfloat16
).cuda()
processor = AutoProcessor.from_pretrained(
"nvidia/LocateAnything-3B",
trust_remote_code=True
)
# 加载密集种子图像
image = "germination_tray_A7.jpg"
# Prompt 措辞很重要——明确说明对重叠情况的预期
prompts = [
"Locate every single seed in this image, including overlapping ones.",
"Detect all seeds. Do not miss any, even if they are partially covered.",
"Count and bound each individual seed. Return all bounding boxes.",
]
best_result = None
max_boxes = 0
for prompt in prompts:
inputs = processor(text=prompt, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=1024, # 允许输出大量边界框
do_sample=False
)
result = processor.batch_decode(outputs, skip_special_tokens=False)[0]
n_boxes = result.count("<>")
if n_boxes > max_boxes:
max_boxes = n_boxes
best_result = result
print(f"检测到 {max_boxes} 粒种子")
print(best_result) 集成提示:对于关键应用场景,比如种子质检,可以用多个Prompt分别推理,再通过NMS合并结果:
from collections import defaultdict
def merge_prompt_results(results_list, iou_thresh=0.5):
"""不同 Prompt 会发现不同的种子,合并它们!"""
all_boxes = []
for res in results_list:
all_boxes.extend(parse_boxes(res)) # 自行实现解析器
# 标准 NMS 或 soft-NMS
return weighted_boxes_fusion(all_boxes, iou_thresh)不同Prompt的召回范围往往不完全重叠,融合后通常能找到更多目标。
参考资源
- 模型:nvidia/LocateAnything-3B
- 论文:LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
- 代码:NVlabs/Eagle/Embodied
- SAM2:facebook/sam2.1
- 标注工具:CVAT(支持点标注),Label Studio
总结
密集重叠场景下的目标检测,并不需要消耗数百小时的手工标注。点监督、SAM2自动分割、轻量级伪标签模型、LocateAnything-3B的并行解码——把这四者结合起来,就能构建出生产级的种子检测器。与传统框标注流程相比,标注时间减少了大约90%。让廉价模型和几何方法承担繁重的工作,人力精力留在验证和边界案例上,这才是更明智的选择。




