概率采样机制决定了LLM天生就擅长“变着花样说”。同一个Prompt生成10次,每次语法都对,但意思可能千差万别。这不是某个模型的缺陷,而是生成式AI与生俱来的内禀属性。
 语法对了,意思可能悄悄变了
语法对了,意思可能悄悄变了
代码层其实早就意识到了这个问题。EPAM Systems的工程师曾在arXiv上发文指出:Code-to-Code转换能够保留表面语法,但业务语义、数据依赖、副作用逻辑可能全都变了味。他们的解法也不是在转换后修修补补,而是干脆把“意思”和“语法”解耦——在转换链条中间插入一层规范。
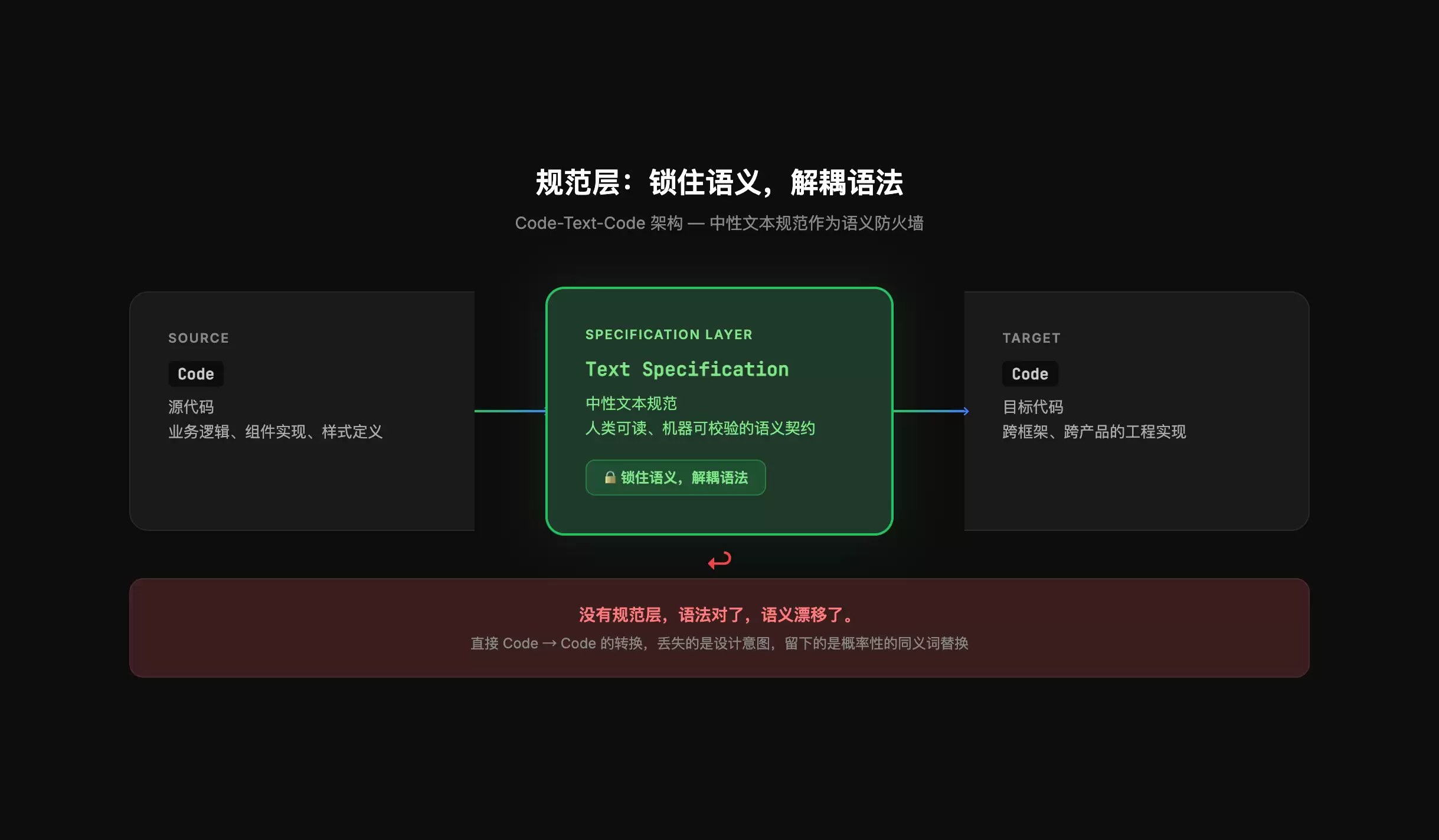 没有规范层,语法对了,语义漂移了
没有规范层,语法对了,语义漂移了
当AI参与生成内容时,代码、数据、界面、文案,都需要这样一层规范来防止“表面合规、语义漂移”。
2.独立验证规范层是 AI 时代的通用基础设施
学术界和工业界正在不同领域独立验证同一个方向——这不是巧合,是结构性需求在推动。
验证 1:代码层 Code-Text-Code
EPAM Systems的论文验证了一个关键场景:在Python转Java、SQL方言互转等任务中,直接Code-to-Code转换必然引入语义漂移。解法是在中间插入中性文本规范——用一份受控的语义表示来捕获程序行为、数据依赖、副作用和领域意图,但不直接转移源语言语法。
关键洞察:转换链条中需要一个必要的中间层,替代规范层的注释和文档。否则语法和语义耦合在一起,漂移根本没法被拦截。
验证 2:审查层 review-verdict-revise-verify
PaperJury验证了AI辅助论文审查的闭环模型:review(发现问题)→ verdict(判定性质)→ revise(修改问题)→ verify(验证到位)。
关键洞察:负载承载的安全逻辑必须放在确定性编排层。停止审查、应用补丁、记录账本——这些动作如果交给AI自由裁量,漏停、漏补、漏记的风险会非常高。
这是AI概率性生成的内禀属性。AI只负责需要理解力的软任务(审查、判断、修复),硬逻辑(路由、停止、补丁应用)则用确定性代码来保证。
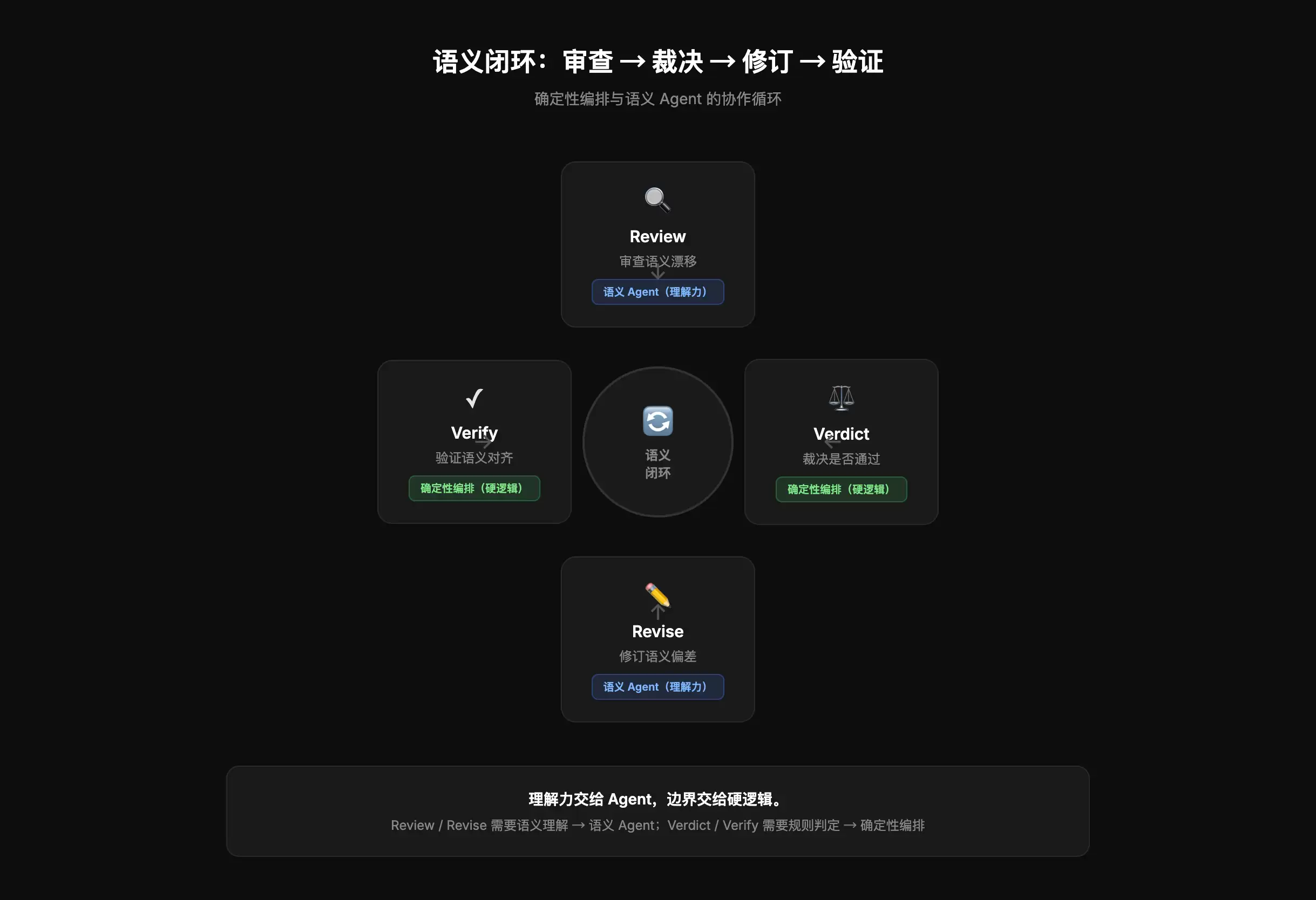 四段环形流程图:review(审查)→ verdict(裁决)→ revise(修订)→ verify(验证)→ 回到 review。
四段环形流程图:review(审查)→ verdict(裁决)→ revise(修订)→ verify(验证)→ 回到 review。
验证 3:数据层 阿里云约束基建
阿里云在《构建可审计、可进化的 AI Agent 底座》中提出了“约束基建”的概念——数据定义、业务流程、规则引擎都需要被约束,以防止数据schema漂移、规则逻辑漂移、模型输出漂移。
关键洞察:约束必须可审计、可进化。与其做一次性配置,不如创建版本化、可追溯、可回滚的基础设施。
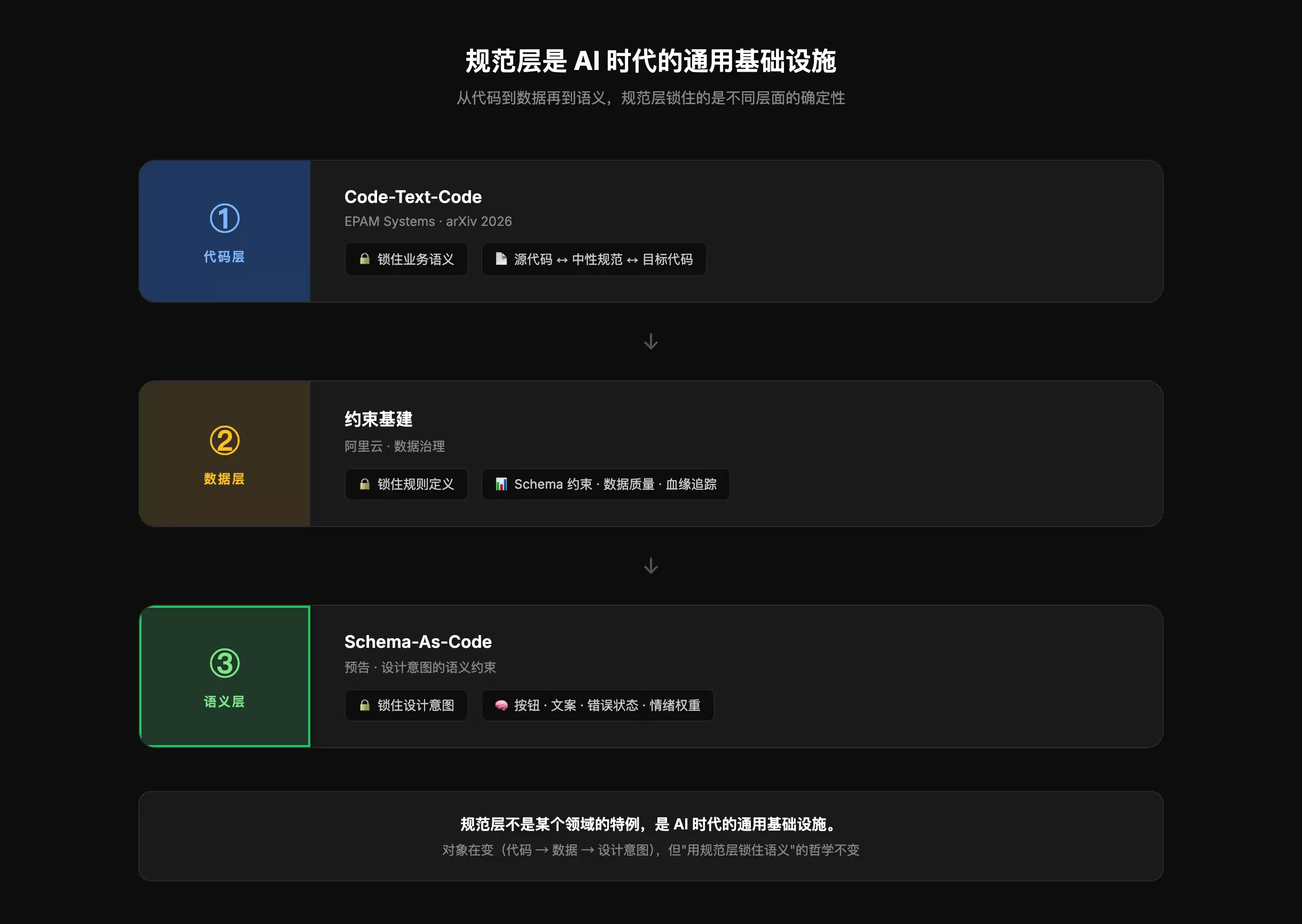
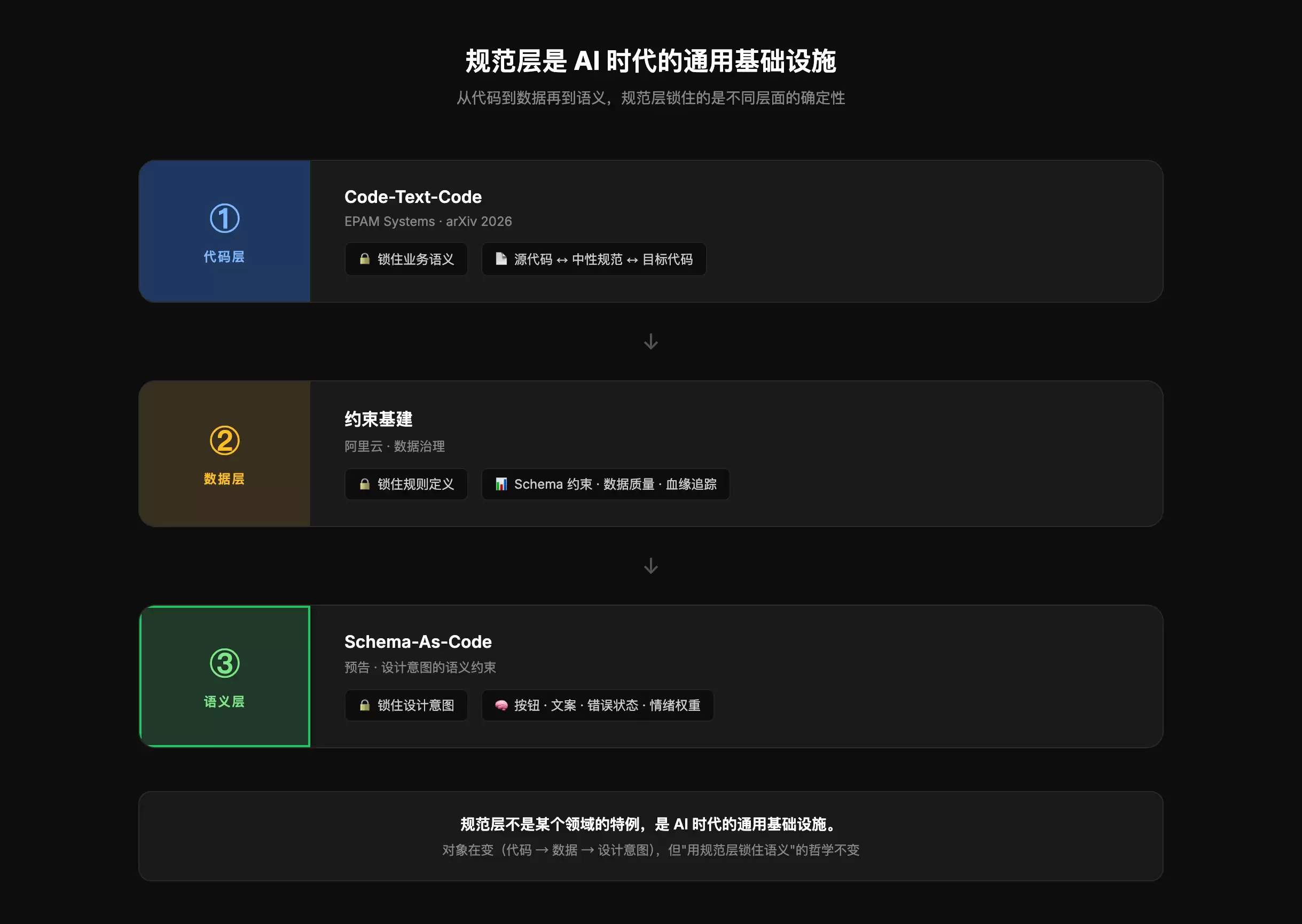 “规范层不是某个领域的特例,是 AI 时代的通用基础设施。”
“规范层不是某个领域的特例,是 AI 时代的通用基础设施。”
三个领域,三套系统,验证的底层逻辑完全一致:
- 代码层:规范锁住代码语义
- 数据层:规范锁住业务规则
- 审查层:规范锁住审查闭环
那么,语义层也需要一道闸门。当AI生成界面时,按钮颜色、文案措辞、错误状态级别的“意思”,同样需要被规范锁住。
3. 从“直接生成”到“规范驱动生成”
AI生成内容的发展路径,正在经历一次转向:从“直接生成”到“Prompt工程”,再到“规范驱动生成”。
第一阶段:直接生成
给AI一个Prompt,让它直接输出。输出什么全靠模型自由裁量。语法对了,语义可能漂移。出了问题再修。
第二阶段:Prompt 工程
优化Prompt让AI“说得更准”。但Prompt是请求,不是约束。同一个Prompt生成10次,10种变体。优化无法消除概率性漂移。
第三阶段:规范驱动
在生成之前把“意思”固定下来。生成时必须携带规范、必须遵守约束、必须留下审计痕迹。用约束生成替代优化生成。

学术界和工业界的独立验证,都在指向同一个趋势:
- 代码层从“直接转换”到“规范驱动重工程”
- 数据层从“自由定义”到“约束基建”
- 审查层从“AI 自由裁量”到“确定性编排语义Agent”
语义层也走在同一条路上。从“直接生成界面”到“Prompt工程优化”,再到“规范驱动生成”。设计意图先被写成机器可读的契约,AI在契约边界内生成,生成后自动验证。
4. Agent = Model + Harness
AI Agent不止有模型(Model),还需要马具(Harness)构成约束框架。
模型(Model):负责理解力、创造力、上下文推理。生成文案、调整颜色、优化布局。
马具(Harness):负责边界、约束、审计。什么绝对不能碰、什么必须包含、生成后怎么验证。
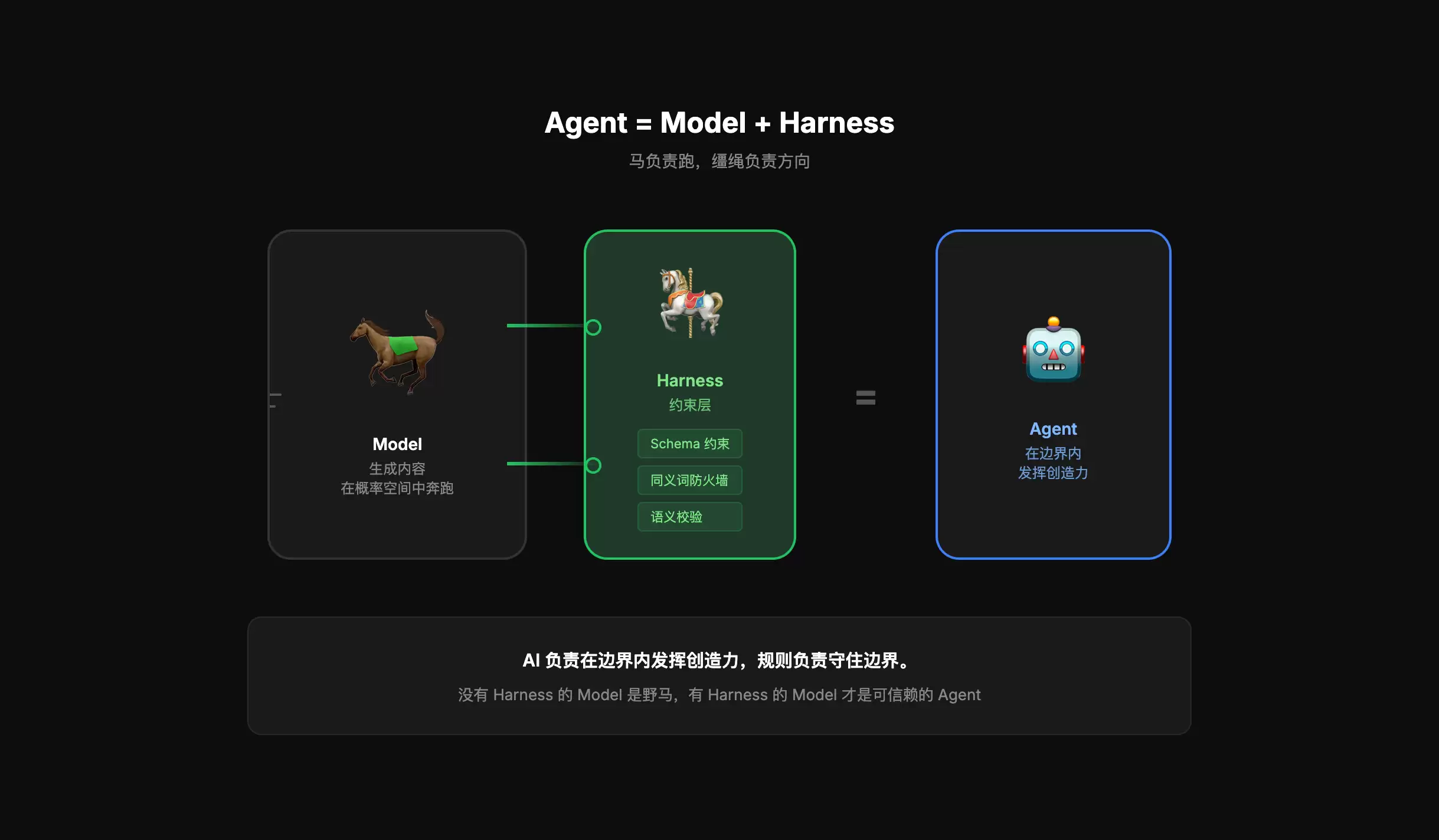 “马负责跑,缰绳负责方向。AI负责在边界内发挥创造力,规则负责守住边界。”
“马负责跑,缰绳负责方向。AI负责在边界内发挥创造力,规则负责守住边界。”
模型自由裁量负责“怎么生成更好”:
模型可以决定这个按钮的圆角是4px还是6px。
模型可以决定这个文案的语气是正式还是亲和。
确定性规则则负责“什么绝对不能碰”:
绝对不能把Critical写成“严重”。
绝对不能把删除按钮做成蓝色实心。
错误状态绝对不能全部用红色。
两者分工,AI负责在边界内发挥创造力,规则负责守住边界。语义也需要一道闸门,给AI的能力加上边界——而不是单纯的限制。
5. 预告:语义层的规范驱动重工程
文章的最后,分享一下我正在推进的工作:语义层的规范驱动重工程流程——一个受控的语义约束闭环:发现漂移 → 生成契约 → 验证有效。
- 发现:按组件类型做结构化识别,扫描AI生成界面中的语义偏差。让机器按规则扫描,替代人工走查。
- 契约:把设计意图写成机器可读的YAML规则。用代码格式的约束替代文档,让机器能执行、人能写、版本可追溯。
- 验证:产品开发级别的三级测试标准,让机器自动审查有明确的通过准则。
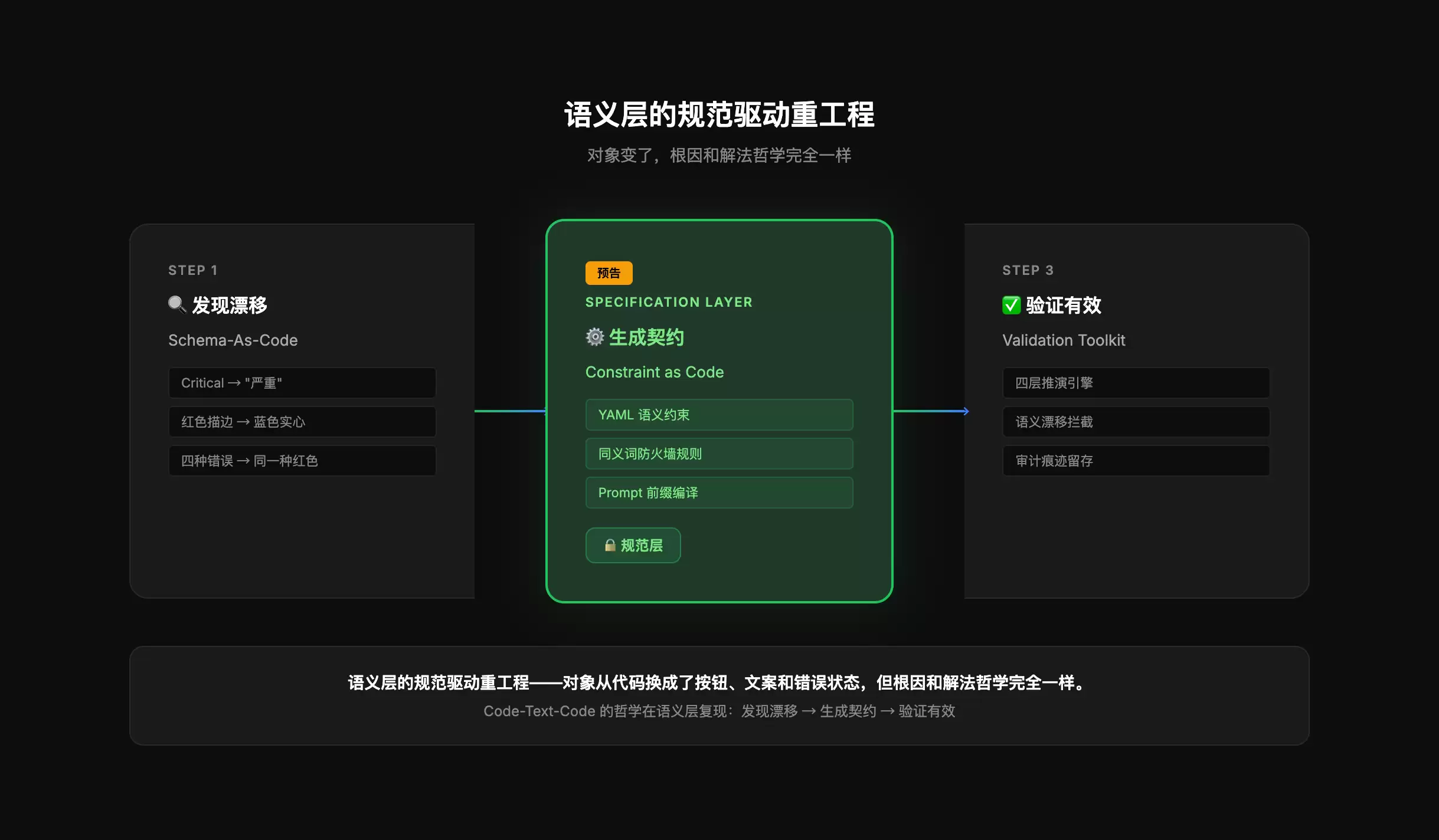 “语义层的规范驱动重工程,对象从代码换成了按钮、文案和错误状态,但根因和解法哲学完全一样。”
“语义层的规范驱动重工程,对象从代码换成了按钮、文案和错误状态,但根因和解法哲学完全一样。”
代码层用中性文本规范锁住业务语义,语义层则用YAML语义契约锁住设计意图。规范层正在逐渐演化为AI时代的通用基础设施。
当AI生成内容时,无论是代码、数据、界面还是文案——语义也需要一道闸门。
附录:引用索引
| 领域 | 来源 | 核心概念 |
|---|---|---|
| 代码层 | EPAM Systems, arXiv 2026 | Code-Text-Code Reengineering |
| 审查层 | PaperJury, arXiv 2026 | review-verdict-revise-verify |
| 数据层 | 阿里云 | 约束基建(Constraint Infrastructure) |
| 语义层 | Schema-As-Code | 规范驱动重工程(预告) |




