第6篇:LLM集成深度解析 - API客户端构建与流式响应实战指南
打造生产级LLM API集成方案:从架构到最佳实践
Claude Code与Claude API的协作模式,实际上为现代AI应用提供了与大语言模型高效、稳定交互的典型范本。接下来我们将深入剖析API客户端的设计原则、流式响应的处理机制以及上下文管理等核心技术要点,帮助开发者构建更可靠的LLM集成方案。
1. API客户端架构设计
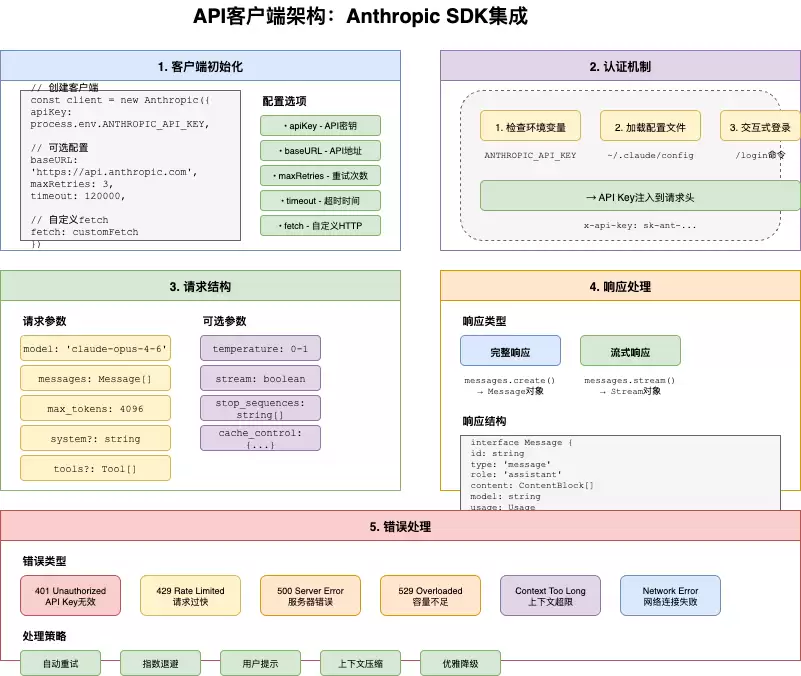
1.1 客户端初始化与关键参数
我们先看一下客户端如何初始化。核心操作是实例化一个Anthropic SDK对象,但其中有几个参数值得特别关注——超时时间设置为60秒,重试次数设为0,因为重试逻辑需要由开发者自行控制,稍后我们会单独讨论。
// services/api/claude.ts
export function getAnthropicClient(options: ClientOptions = {}): Anthropic {
return new Anthropic({
apiKey: getApiKey(),
baseURL: getApiBaseUrl(),
timeout: options.timeout ?? 60000,
maxRetries: 0, // 自定义重试逻辑
...options,
})
}
1.2 认证管理:API Key获取策略
获取API Key并非简单读取环境变量这么简单。在实际生产环境中,需要遵循一套优先级策略:首先检查环境变量,若无则尝试调用API Key Helper工具,最后还可以通过OAuth Token获取。在所有方式都失败的情况下,直接抛出异常。
// API Key 获取策略
async function getApiKey(): Promise {
// 1. 环境变量
if (process.env.ANTHROPIC_API_KEY) {
return process.env.ANTHROPIC_API_KEY
}
// 2. API Key Helper
const helper = getApiKeyHelper()
if (helper) {
return await executeApiKeyHelper(helper)
}
// 3. OAuth Token
const oauthToken = await getOAuthToken()
if (oauthToken) {
return oauthToken
}
throw new Error("No API key a vailable')
}
1.3 请求归因与流量分析
为了便于分析调用来源并准确计费,每个请求都会携带一个归因头。其中包含引擎版本、入口点以及设备指纹信息。这一设计在排查流量异常和核算成本时非常实用。
// 归因头用于分析
export function getAttributionHeader(fingerprint: string): string {
const version = getVersion()
const entrypoint = getEntrypoint()
return `x-anthropic-billing-header: cc_version=${version}; cc_entrypoint=${entrypoint}; fingerprint=${fingerprint}`
}
2. 流式响应处理:防止数据丢失与UI卡顿
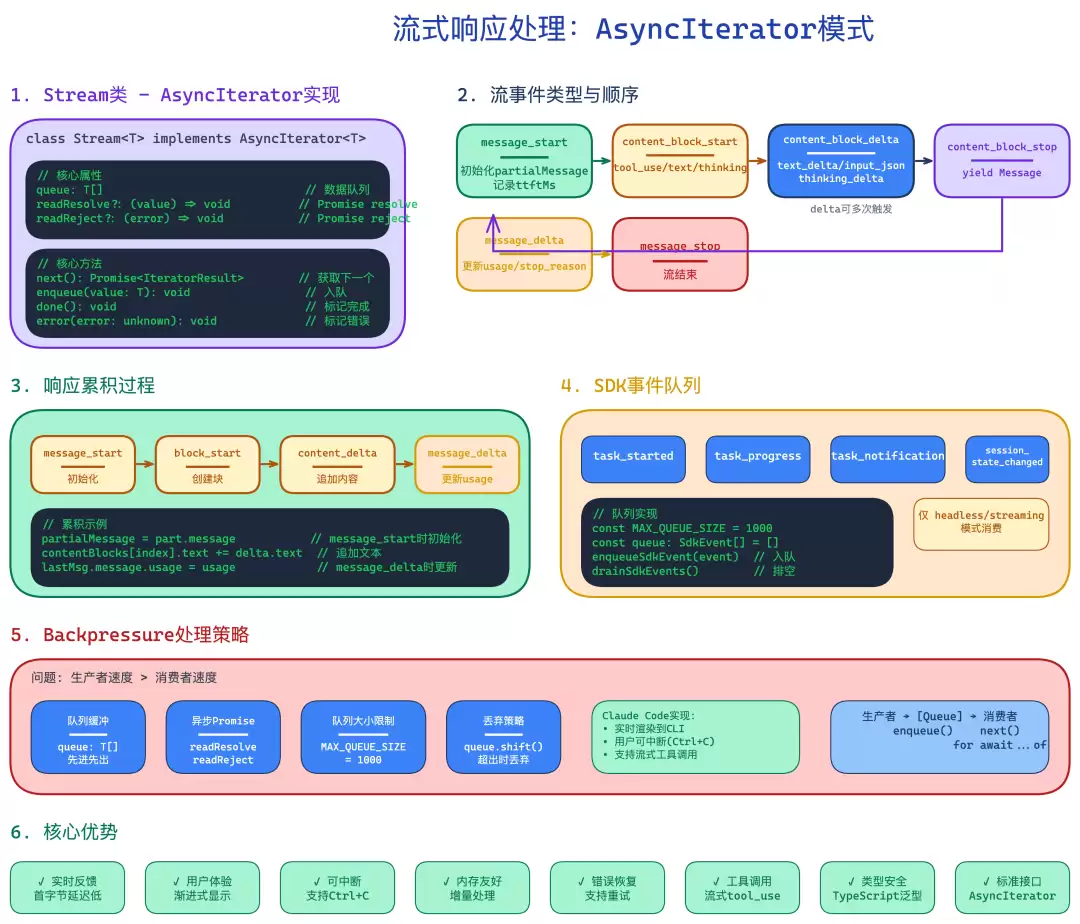
流式响应虽已不新鲜,但处理不当仍会导致数据丢失或用户界面卡顿。下面这套方案基于自定义Stream类,底层实现了异步迭代器,读写分离的设计使得处理逻辑非常优雅。
2.1 Stream类实现详解
这个Stream类的核心逻辑包含两点:写入时如果没有消费者在等待,数据先入队暂存;读取时如果队列中有数据则直接取出,否则挂起等待。当流被关闭时,所有挂起的读取操作都会收到结束信号。
// utils/stream.ts
export class Stream implements AsyncIterator {
private readonly queue: T[] = []
private readResolve?: (value: IteratorResult) => void
private readReject?: (error: unknown) => void
private isDone: boolean = false
// 写入数据
write(item: T): void {
if (this.isDone) {
throw new Error("Stream is closed')
}
if (this.readResolve) {
// 有等待的读取者,直接交付
this.readResolve({ done: false, value: item })
this.readResolve = undefined
this.readReject = undefined
} else {
// 没有等待者,入队
this.queue.push(item)
}
}
// 读取数据(AsyncIterator)
async next(): Promise> {
if (this.queue.length > 0) {
return { done: false, value: this.queue.shift()! }
}
if (this.isDone) {
return { done: true, value: undefined }
}
// 等待数据
return new Promise((resolve, reject) => {
this.readResolve = resolve
this.readReject = reject
})
}
// 关闭流
close(): void {
this.isDone = true
if (this.readResolve) {
this.readResolve({ done: true, value: undefined })
}
}
}
2.2 流式事件处理机制
Claude API的流式事件包含多种类型:消息开始、内容块开始、增量更新、块结束、消息增量、消息结束等。这个生成器函数将所有事件统一封装为MessageUpdate类型,下游只需根据类型进行处理即可。
// 处理 Claude API 流式响应
async function* processStreamEvents(
stream: AsyncIterable
): AsyncGenerator {
for await (const event of stream) {
switch (event.type) {
case 'message_start':
yield { type: 'message_start', message: event.message }
break
case 'content_block_start':
yield { type: 'block_start', index: event.index, block: event.content_block }
break
case 'content_block_delta':
yield { type: 'block_delta', index: event.index, delta: event.delta }
break
case 'content_block_stop':
yield { type: 'block_stop', index: event.index }
break
case 'message_delta':
yield { type: 'message_delta', delta: event.delta }
break
case 'message_stop':
yield { type: 'message_stop' }
return
}
}
}
3. 上下文管理:从20万到100万Token的动态配置
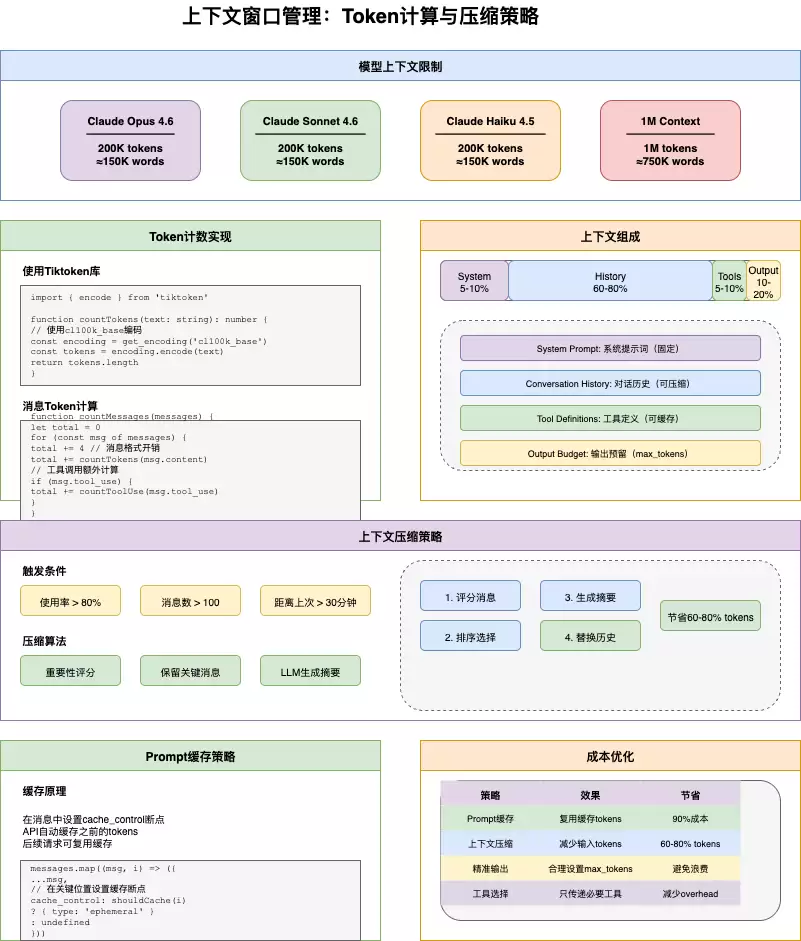
上下文窗口直接决定了模型能“记住”的信息量。Claude Code的默认值为20万Token,但通过特定方式可以扩展至100万。下面来看如何进行动态配置。
3.1 上下文窗口配置策略
获取上下文窗口时,优先级如下:环境变量具有最高优先级,接着检查模型是否支持100万Token(通常通过beta头启用),最后才使用默认值。这一逻辑确保了兼容性与灵活性之间的良好平衡。
// utils/context.ts
const MODEL_CONTEXT_WINDOW_DEFAULT = 200_000
const CONTEXT_1M_BETA_HEADER = "context-1m-2025-02-03'
export function getContextWindowForModel(
model: string,
betas?: string[]
): number {
// 环境变量覆盖
if (process.env.CLAUDE_CODE_MAX_CONTEXT_TOKENS) {
return parseInt(process.env.CLAUDE_CODE_MAX_CONTEXT_TOKENS)
}
// 1M 上下文检测
if (has1mContext(model)) {
return 1_000_000
}
// Beta 头检测
if (betas?.includes(CONTEXT_1M_BETA_HEADER) && modelSupports1M(model)) {
return 1_000_000
}
return MODEL_CONTEXT_WINDOW_DEFAULT
}
3.2 Token 用量追踪
仅仅知道窗口大小还不够,还需要实时追踪Token使用情况。这里对输入Token、输出Token、缓存创建Token以及缓存读取Token分别进行记录,并计算使用百分比,这对于预算控制非常有帮助。
// Token 使用追踪
interface TokenUsage {
inputTokens: number
outputTokens: number
cacheCreationInputTokens: number
cacheReadInputTokens: number
}
function calculateTokenPercentage(
usage: TokenUsage,
contextWindow: number
): number {
const total = usage.inputTokens + usage.outputTokens
return Math.round((total / contextWindow) * 100)
}
4. 重试策略:应对限流与瞬时过载
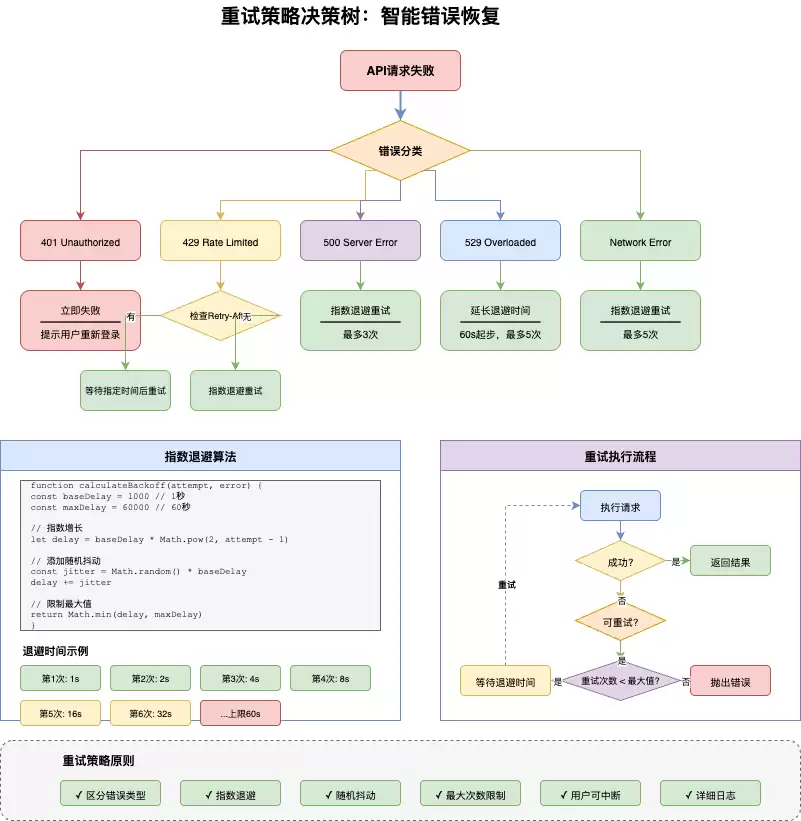
网络请求不可能永远一帆风顺,尤其是面对大模型API的限流和瞬时过载。一套优良的重试策略能显著提升请求成功率,同时避免给服务端增加额外压力。
4.1 withRetry实现
withRetry函数包裹了实际请求操作,最多尝试3次。它会区分不同类型的错误:容量错误(529/429)按退避策略等待后重试;连接错误(ECONNRESET等)则先重置连接再重试;其他不可重试的错误直接抛出,避免浪费请求资源。
// services/api/withRetry.ts
export async function withRetry(
operation: (client: Anthropic, attempt: number, context: RetryContext) => Promise,
options: RetryOptions = {}
): Promise {
const maxRetries = options.maxRetries ?? 3
for (let attempt = 1; attempt <= maxRetries; attempt++) {
try {
const client = getAnthropicClient()
return await operation(client, attempt, { attempt, maxRetries })
} catch (error) {
// 容量错误 (529, 429)
if (isTransientCapacityError(error) && attempt < maxRetries) {
const delay = calculateBackoff(attempt, error)
await sleep(delay)
continue
}
// 连接错误
if (isStaleConnectionError(error)) {
resetConnection()
continue
}
// 不可重试错误
throw new CannotRetryError(error, { attempt, maxRetries })
}
}
throw new Error("Max retries exceeded')
}
4.2 指数退避与随机抖动
退避时间采用指数增长并叠加随机抖动的方式。基础延迟为1秒,每次重试翻倍,上限不超过30秒。抖动能够避免多个客户端同时重试造成的“惊群效应”。
// 计算退避时间
function calculateBackoff(attempt: number, error: unknown): number {
const baseDelay = 1000
const maxDelay = 30000
// 指数退避 + 抖动
const exponentialDelay = baseDelay * Math.pow(2, attempt - 1)
const jitter = Math.random() * 1000
return Math.min(exponentialDelay + jitter, maxDelay)
}
5. Prompt缓存:降低延迟与成本
缓存机制是降低延迟和成本的一大利器。Claude API支持对系统提示和部分消息设置缓存断点,这样重复的内容无需重新计算。
5.1 缓存策略实施
构建消息时,首先识别出可缓存的系统提示,然后对每条消息判断是否应该设置cache_control为ephemeral。最后还要计算缓存预算,避免缓存占用过多上下文窗口。
// Prompt 缓存配置
function buildMessagesWithCache(
messages: Message[],
systemPrompt: string
): { messages: MessageParam[]; cacheBudget: number } {
// 识别可缓存的系统提示
const cacheableSystemPrompt = systemPrompt
// 缓存断点设置
const cacheBudget = calculateCacheBudget(messages)
return {
messages: messages.map(msg => ({
...msg,
cache_control: shouldCache(msg) ? { type: 'ephemeral' } : undefined,
})),
cacheBudget,
}
}
6. 错误处理:分类是重试的基石
正确的错误分类是重试策略的基础。如果无法区分哪些错误可以重试、哪些不能,重试逻辑就会变得混乱不堪。
6.1 错误类型判断
这里将容量错误(429 Too Many Requests、529 Service Overloaded)与连接错误(ECONNRESET、ETIMEDOUT)做了明确区分。前者适合使用退避重试,后者则需要先重置连接再重试。
// 错误类型判断
function isTransientCapacityError(error: unknown): boolean {
if (error instanceof APIError) {
return error.status === 429 || error.status === 529
}
return false
}
function isStaleConnectionError(error: unknown): boolean {
if (error instanceof ConnectionError) {
return error.code === 'ECONNRESET' || error.code === 'ETIMEDOUT'
}
return false
}
下一篇预告
第7篇:Prompt工程与系统提示词 —— 深入理解 Claude Code 如何设计高效的系统提示词与优化技巧。




