在主动关闭联网模式后,Qwen3经过分步推理与逻辑验证,最终成功得出了正确答案。
更值得关注的是,从其思考链条中可以清晰看到,它的推理方式与人类高度相似——通过不断推翻备选方案来逐步锁定可行路径。

接下来,我们进入第二项挑战:一道极具难度的专业数学试题。
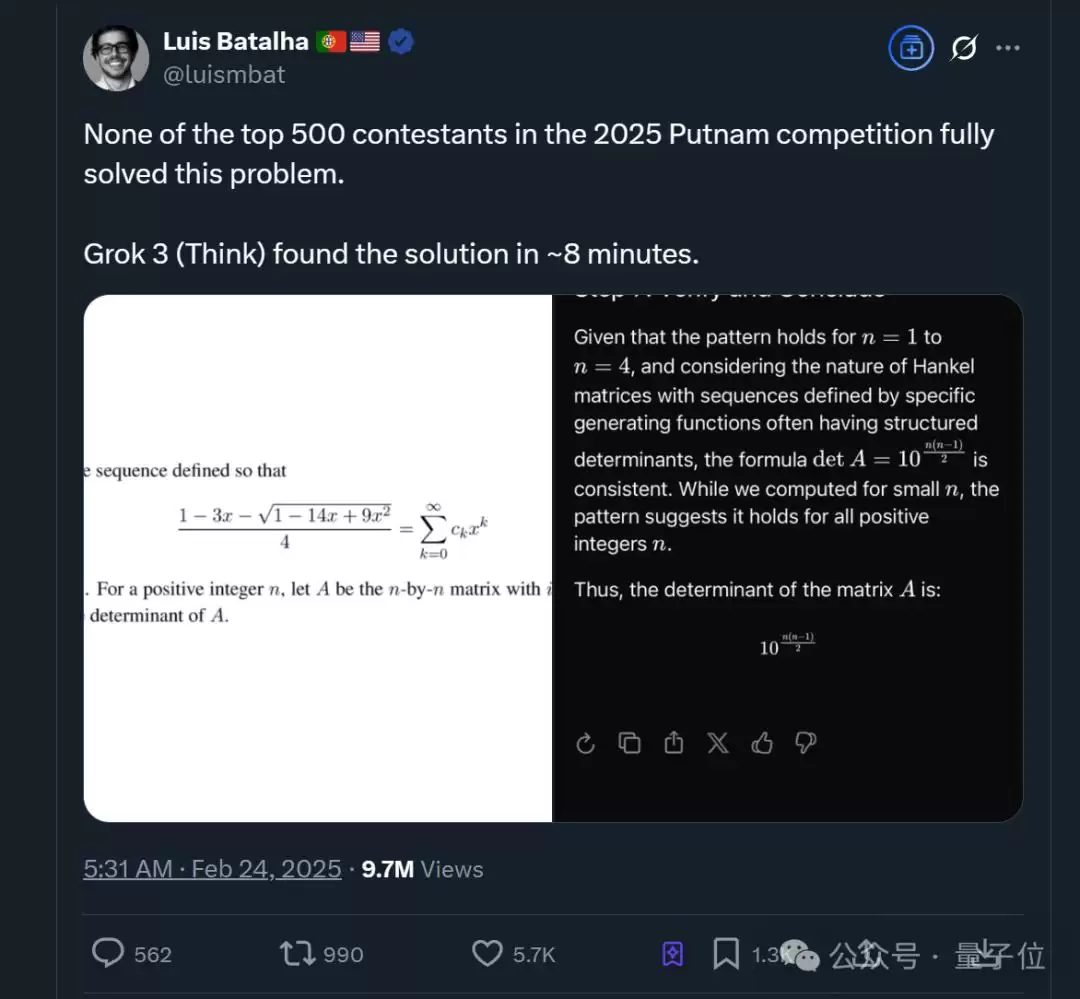
该题目来自今年普特南数学竞赛,被公认为本科数学考试中的“地狱级”难度,人类考生通常需要耗费6小时作答,且据称前500名参赛者中无人能完整解出。
将这道题交给Qwen3后,可以明显感知到其思考时长显著增加,最终在5分38秒内给出了正确解答。
p.s. 千问智能体暂不支持直接上传图片,因此我们选择从App首页上传图片,提取文字后继续使用千问智能体作答。
更有趣的是,翻阅它的推理记录,还能看到模型在线“崩溃”的生动表现:

当然,尽管AI的解题速度和准确率明显优于人类,仍需与同类模型进行横向对比。
在国外网友的测试中,同样的题目Grok 3(Think)耗时约8分钟才找到解题思路。
两相比较之下,这一轮Qwen3略占上风。
第三关:多语言能力
另一个突出亮点是,Qwen3支持119种语言及方言,被网友戏称为“AI界的多邻国”。
不妨直接让它挑战一下国内专业译者的水准。
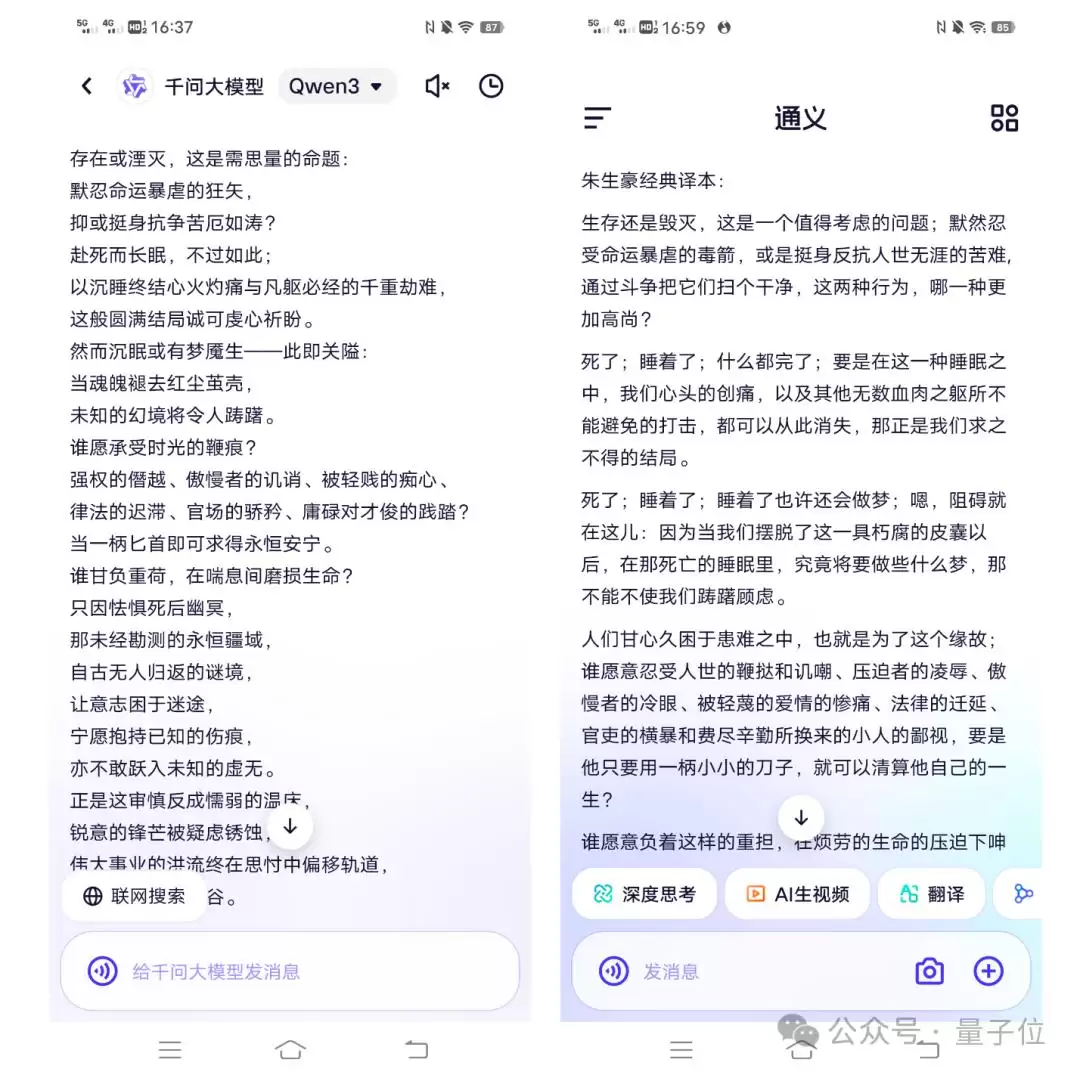
将莎士比亚《哈姆雷特》的经典段落交给它,要求按照“信达雅”原则翻译成中文。
它竟然懂得参考优秀译本,并刻意避免直接抄袭引发侵权问题。

最终生成的译文如下(左侧),对比我们熟知的朱生豪经典译本(右侧),你觉得AI味道有多浓?
第四关:赛博闺蜜、购物比价、写歌一网打尽
除了上述偏向基础能力的测试,将Qwen3嵌入App后,我们还解锁了更多实用玩法。
做旅游规划这类常规操作自不必多说,关键是它还能充当“赛博闺蜜”,帮你挑选更适合发朋友圈的旅行照片。

日常购物比价同样轻松搞定,比如分析出当下3000元预算内最值得入手的平板设备。
不仅用表格清晰列出各品牌核心参数,还根据不同需求给出推荐,简直是“伸手党”的贴心助手。
此外,最近登上热搜的“AI写歌”,我们也用Qwen3尝试了一番。
五一版·大张伟嗨歌新鲜出炉,单看歌词确实有那味儿了:
Okk,以上便是我们的全部实测体验。
最后做个总结,通过在通义App中使用Qwen3专属智能体,可以明显感受到以下几点:
Qwen3旗舰模型的生成速度极为迅捷,体验十分流畅;
模型擅长逻辑推理,能够破解经典逻辑陷阱和复杂数学难题;
代码能力方面,已能快速实现一些简单功能需求;
由于载体是App,可拓展的玩法相当丰富。
而且,通义App自上个月页面改版后,整体设计更加简约,交互体验也进一步优化。
更多网友实测
与此同时,随着Qwen3模型的火爆出圈,更多网友也在第一时间进行了体验。
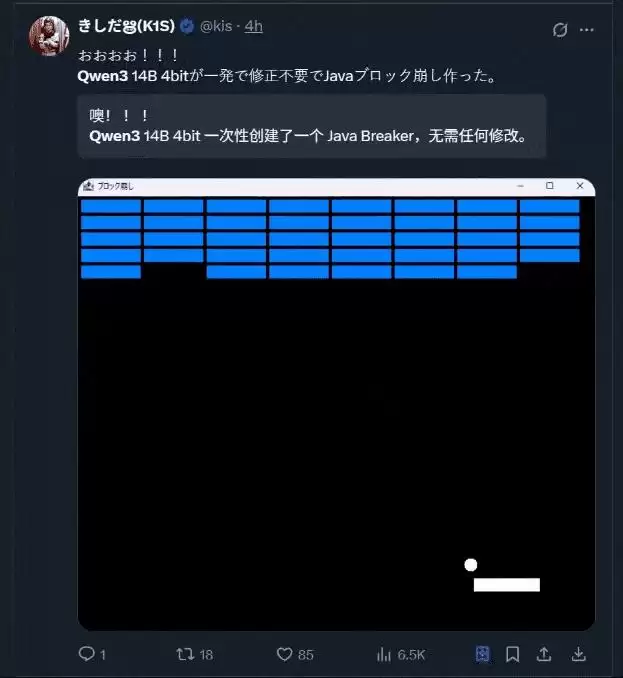
有类似“空间内弹小球”的交互页面设计:
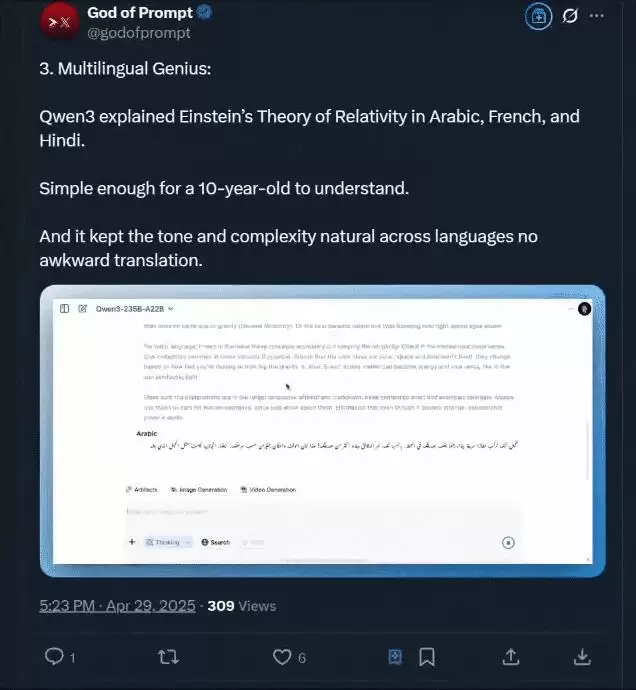
还有用阿拉伯语、法语和印地语解释爱因斯坦相对论的玩法,该博主声称:
当然,大家一直钟爱的小游戏开发也安排上了:
开源界的新王者
Qwen3引发广泛热议的背后,可以看到的是,在开源影响力方面,以Qwen为代表的国产大模型已显露超越Llama之势。
这一点,从reddit LocalLLaMA等开发者聚集板块的最新讨论话题中,亦可窥见一斑。
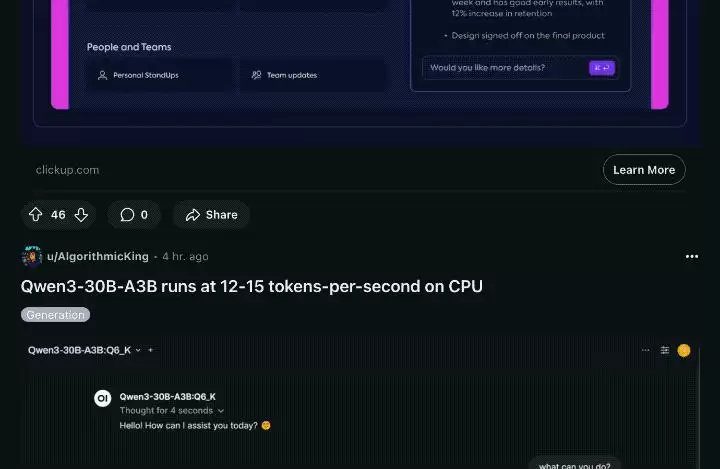
不仅仅是基准评测数据上的纸面超越,实测越多,模型的实际能力就越能被客观公允地认知。
而如今开源格局的变革,并非一蹴而就。前有DeepSeek,今有Qwen3,背后体现的是来自中国开源力量持之以恒的努力,以及一如既往的“中国速度”。
以Qwen为例:
2024年11月底,开源推理模型QwQ;
2025年春节档,接连发布Qwen2.5百万上下文版本、视觉理解模型Qwen2.5-VL,以及超大规模MoE模型Qwen-2.5 Max;
2025年3月,QwQ-32B以1/10成本比肩DeepSeek-R1;
多模态方面,还有万相Wan的持续开源与迭代……
这还仅仅是短短5个月内的进展。
再加上更为开放且商用友好的Apache 2.0协议,开发者们的转向自然在情理之中。

作为普通用户,一方面,可以在通义App这类官方应用上更快地感知到满血模型的能力。
另一方面,也可以期待开源带来更多衍生应用的可能性。




