过去两年间,大模型行业的竞争几乎都聚焦在同一个方向:谁的参数规模更大、推理能力更强、排行榜名次更靠前。背后的逻辑也很直白——模型越强大,开发者和企业客户自然会主动靠拢。然而,当AI Agent真正被部署到生产环境后,越来越多的公司开始意识到一个略显尴尬的现实:无论模型多么出色,如果成本失控,这门生意依然难以持续运转。
最近,一家名叫Lindy的AI Agent创业公司,就公开展示了这种趋势变化。
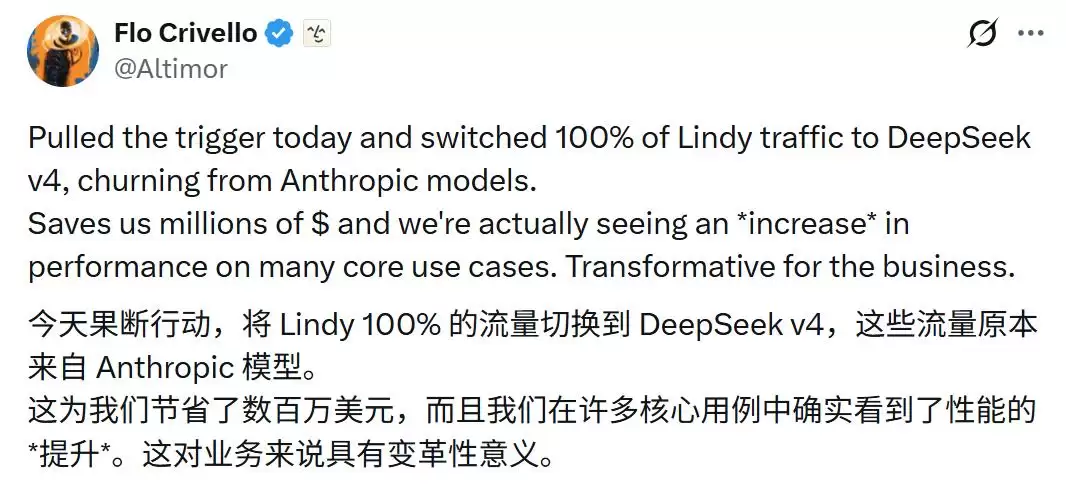
创始人兼CEO Flo Crivello宣布,公司已将生产环境中的所有模型流量从Anthropic切换至DeepSeek V4。按照他的说法,这一决策不仅让企业节省了上百万美元的推理成本,而且在部分核心业务场景中,模型的表现甚至有所提升。
消息传出后,在AI圈内引发了广泛讨论。
被推理成本倒逼出的战略转移
先说背景。Lindy是一家专注于AI Agent的平台企业,用户无需编写代码,就能自行创建AI助手,自动处理邮件、安排会议、录入CRM、跟进客户、整理数据等日常办公任务。
创始人Flo Crivello并非创业新手。他此前在Uber担任工程师和产品负责人,后来创办了远程办公平台Teamflow,融资额达5200万美元。2023年,他借生成式AI的热潮,将方向转向AI Agent,推出了Lindy。
与许多AI应用一样,Lindy的核心成本并不在于服务器、办公场地或市场推广,而是模型推理费用。今年4月,Crivello曾在X上公开表示,推理成本已成为公司最大开销,甚至超过了员工薪资支出。
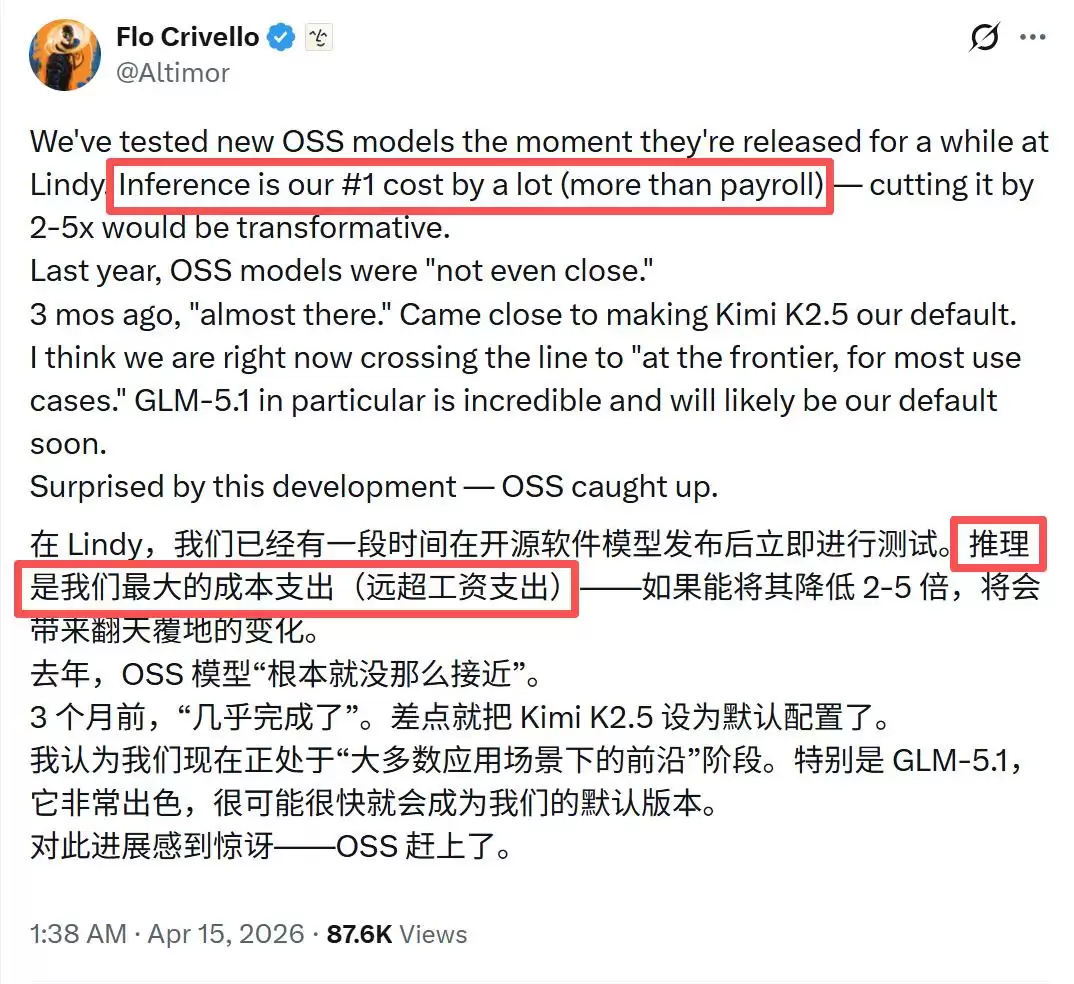
对于一款依赖AI持续运行的产品来说,这显然是个严峻挑战。而且,类似困境正在整个行业中蔓延:
● 不久前,GitHub宣布调整Copilot的订阅模式,部分服务从固定月费转向按量计费。原因是Agent式编程日益普及,用户单次触发的推理请求量显著增长,原有订阅价格已无法覆盖成本。
● Uber内部也遇到了类似问题:由于大量使用Anthropic旗下的Claude Code等AI工具,原本规划到2026年的AI预算,在短短四个月内就接近耗尽,管理层不得不再三权衡投入产出比。
正因如此,Linux基金会最近联合谷歌、微软、IBM、Salesforce等企业,共同成立了Tokenomics基金会,试图推动建立统一的AI Token成本标准。
DeepSeek并非一时冲动的选择
尽管推理成本压力不小,但Lindy最终选择DeepSeek,并非心血来潮。
按照Crivello的说法,团队为这次模型切换做了长期准备:“我们一直在寻找替代方案,评估各类开源模型,整个过程持续了大约6到9个月。”
过去一年里,开源模型的发展速度已让许多创业公司重新审视自己的技术路线。
如果把时间拉回到2024年,不少企业对开源模型的评价仍是“差距明显”。但到了2025年底、2026年,情况已截然不同:DeepSeek、Kimi、GLM等一系列中国模型不断刷新性能纪录,而推理成本远低于OpenAI、Anthropic等闭源模型。
Crivello透露,Lindy最初甚至考虑将月之暗面的Kimi设为默认模型,后来又认真评估过智谱AI的GLM系列。最终,他们将目光锁定在今年4月发布预览版的DeepSeek V4上。相比此前备受关注的DeepSeek R1,V4在通用能力与Agent任务上表现更优,且价格依然极具竞争力。
今年6月初,Lindy完成内部测试后,出现了一个让团队感到意外的结果:不仅成本更低,在某些关键业务场景中,DeepSeek的表现甚至超越了Anthropic。
比预想多出“100倍的工作量”
然而,从Anthropic迁移到DeepSeek,远没有修改几行API代码那么简单。Crivello后来在X上感慨:“整个过程最终比我们最初预想的多出了100倍工作量。”
很多人可能会困惑:都是大模型接口,迁移为何如此复杂?
原因在于,企业生产环境中的AI系统,实际上是一整套高度耦合的工程体系。模型后端连接着Prompt工程、自动化评测系统、用户反馈机制、监控与观测平台、路由调度逻辑、安全与合规流程等多个环节。更换模型后,这些环节往往都需要重新适配。
Crivello透露,团队进行了大量线上和线下评测,还实施了所谓的“Vibe Eval”——简单来说,就是通过人工主观判断输出结果是否符合预期,以验证DeepSeek在真实生产环境中能否达到甚至超越Anthropic的表现。
“我们做了大量评估,然后逐步放量上线,观察对用户留存的影响,同时还要不断调整Prompt,去适配新模型。”
值得一提的是,Lindy并没有选择自行部署DeepSeek,而是使用了美国推理服务商Atlas Cloud提供的DeepSeek V4服务。这样既保留了成本优势,又避免了自建推理基础设施带来的额外复杂性。
因此,从结果来看,Lindy真正投入的,并不仅仅是一次模型迁移,而是一次底层AI基础设施的升级。
DeepSeek究竟赢在哪里?
根据Crivello透露的信息,Lindy目前最核心的业务之一,是邮件处理。
系统需要读取用户收件箱内容,理解上下文关系,并按照用户过往的表达习惯自动生成回复草稿。正是在这些高频任务上,DeepSeek交出了超出预期的成绩单——Crivello表示:“我们在一些核心用例上看到了令人惊讶的性能提升。”
不过,他也强调,DeepSeek并非在所有方面都占据优势。在复杂工作流自动化任务上,Anthropic旗下的Claude Sonnet目前仍然更强:“在工作流自动化领域,DeepSeek还不如Sonnet,但那并非我们最核心的业务场景。”
因此,虽然Lindy已将生产流量全部切换至DeepSeek,但Anthropic并未完全退出其技术栈:
一方面,Lindy内部员工仍然大量使用Claude,因为Anthropic的Max订阅计划性价比依然很高。Crivello坦言:“如果不是Max订阅计划,我们可能连Claude也换掉了。”
另一方面,面对复杂任务时,Anthropic可以充当“保险丝”的角色。此前有用户询问,未来Lindy是否会重新使用Anthropic?Crivello的回答是:“当系统检测到任务失败时,我们大概率还是会升级调用Opus。”同时他补充道,这种情况只占极小比例。
简单来说:Anthropic从过去Lindy的默认选择,转变为一个备用模型。但Crivello也补充说,如果未来Anthropic推出更强的新模型,同时大幅降价,他会重新成为客户:“如果下一代模型足够有竞争力,我们很可能还会用回它的产品。”
省下的钱,到底值不值?
到目前为止,Crivello并未公开具体的节省金额,只表示“省了上百万美元”。
不过,对于一家推理成本已超过工资支出的AI创业公司来说,哪怕只是节省30%到50%的模型费用,也是一笔相当可观的资金。
而如果将Lindy的决策放到行业大背景下审视,它其实代表了一种日益明显的趋势:过去几年,大模型市场基本由OpenAI和Anthropic主导,企业选模型时更看重能力上限。但随着模型之间的差距不断缩小,成本开始成为新的决策要素。
来自Vercel AI Gateway的数据显示,仅在2026年5月的一个月内,DeepSeek在平台Token调用量中的占比就从不到1%飙升至17%,但其对应的收入占比却只有约1%——原因很简单:DeepSeek实在太便宜了。
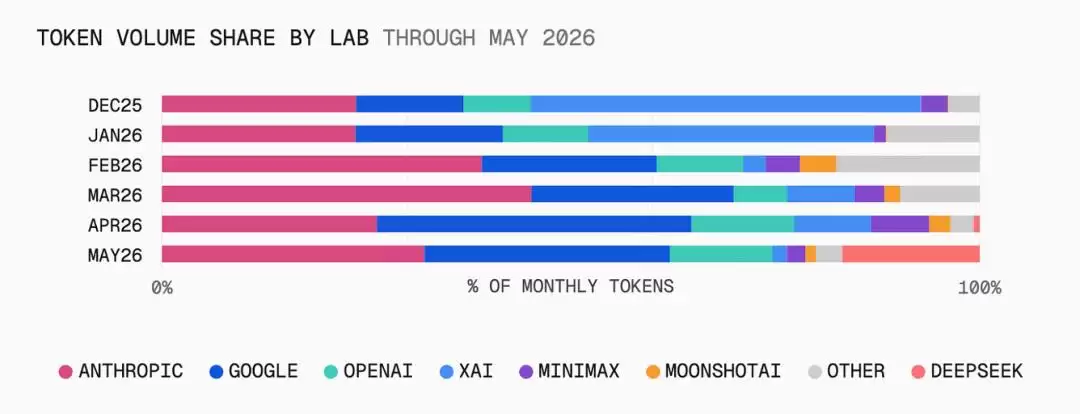
于是,一种新的市场结构正在形成:
一边是OpenAI、Anthropic等提供最强性能、最高价格的旗舰模型;
另一边则是DeepSeek、GLM、Kimi等性能越来越接近、价格却低得多的开放权重模型。
对于Lindy这类每天消耗海量Token的公司来说,问题变得非常现实:如果能用更低成本获得80%到90%的效果,那么为剩下那部分能力支付数倍的价格,还划算吗?
Crivello给出的答案非常直接:
“像我们这样消耗大量Token的公司,100%必须这么做,否则就是不负责任。”
在他看来,许多企业之所以尚未行动,可能是因为更习惯信任那些知名品牌。但未来几年,或许企业会越来越不在意模型来自哪里,而更关注最终效果与成本。