DiffusionGemma 一经发布,立即在人工智能领域引发了广泛讨论。其核心原因在于,它直接颠覆了当前大语言模型(LLM)文本生成的传统范式。这一技术突破,值得我们深入剖析。
标准 Gemma 4 系列依赖自回归解码机制,即逐词生成,每一步都依赖于前一步的输出结果。而 DiffusionGemma 则采用了离散文本扩散方法,能够同时生成并逐步优化整段文本,从而绕过了长期制约本地 AI 性能的关键瓶颈——硬件限制。

瓶颈转移:从内存带宽到算力
要理解 DiffusionGemma 的价值,首先需要认清传统自回归模型的核心瓶颈所在。
当你在单块 GPU 上本地运行标准大模型时,最常见的性能瓶颈是内存带宽。每生成一个 Token,都需要从内存中完整加载权重矩阵,而 GPU 的张量核心大部分时间处于空闲状态,等待数据传输,算力难以充分发挥。
DiffusionGemma 则巧妙地将瓶颈从内存带宽转移到了算力上。在每次前向传播中,它会并行构建一个 256 Token 的草稿画布,一次性向处理器提供更大的工作负载,从而真正利用了硬件的算术强度。这一架构变化,相当于从逐字打印的打字机升级为整版印刷的印刷机。效率提升的根本原因正在于此。
架构基础
DiffusionGemma 基于 26B 参数的混合专家模型 Gemma 4,推理时实际调用的参数量约为 3.8B 到 4B。稀疏 MoE 设计使其在保持深度推理能力的同时,经过量化后能够适配高端消费级 GPU 的 18GB 显存限制。
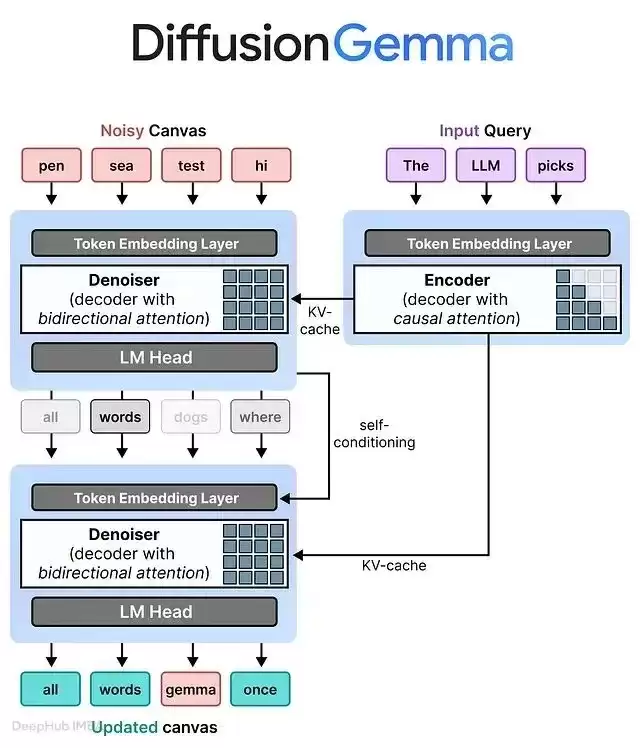
该模型采用编码器-解码器架构,两个部分各司其职:自回归编码器处理初始输入的 Prompt 上下文,使用因果注意力机制,结果存入 KV Cache;双向去噪器则在生成的画布上应用双向注意力,256 Token 画布中的每个位置都能同时看到其他所有位置的信息,并能参考 KV Cache 中已有的历史上下文。
对于超过 256 Token 的长序列,模型会启动块自回归扩散机制——一个块去噪完成后移交至 KV Cache,下一个画布则以已生成的历史信息为条件重新开始。通过这种混合方式,DiffusionGemma 融合了并行扩散的速度优势与长文本顺序生成的稳定性。
离散文本扩散的运作机制
整个生成过程是一个迭代去噪循环,与 AI 图像生成器的原理相似,具体分为三个阶段:
首先,画布初始化。模型用随机的占位 Token 填满一个 256 Token 的块。接着,迭代精炼。经过多轮去噪,置信度高的 Token 会优先确定,并作为全局上下文引导剩余占位符逐步优化。最后,收敛。所有 Token 逐渐收敛,最终序列形成连贯的文本。
整块一次性评估带来了自回归模型无法实现的能力:自我修正。如果在某次传播中对某个位置的置信度下降,采样器可以对该位置重新加噪并替换。而自回归模型一旦采样某个 Token,便无法回头——这是两种架构之间最具实质性的技术差异。
推荐的部署与优化方案
Google 提供了具体的部署配置建议,旨在平衡延迟与输出质量。值得注意的是,模型的实际表现对去噪采样器的调参方式非常敏感。
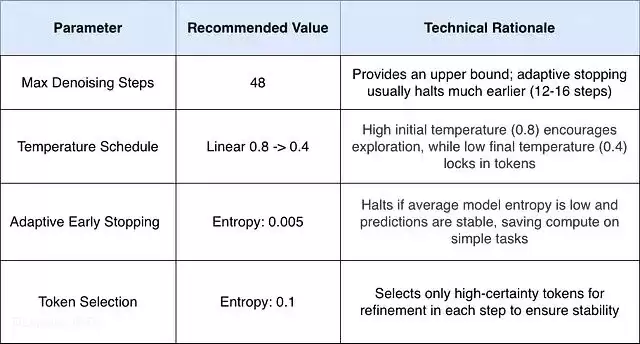
目前,模型已针对 NVIDIA Blackwell 和 Hopper 架构上的 NVFP4(4 位浮点)进行了优化,在保持接近无损精度的前提下,进一步提升了计算吞吐量。
性能数据与实验结果
最直观的指标是原始生成速度。在实验室专用硬件上的测试结果如下:
- NVIDIA H100:超过 1,000 Token/秒。
- NVIDIA GeForce RTX 5090:超过 700 Token/秒。
与同等硬件上的传统模型相比,Token 生成速度最高提升了 4 倍。不过,这些数字在低并发的本地工作流中最为有效。在请求已批量处理、GPU 算力高度饱和的高流量云环境中,并行解码的优势会减弱,部署成本反而可能上升。
案例展示:数独求解实验
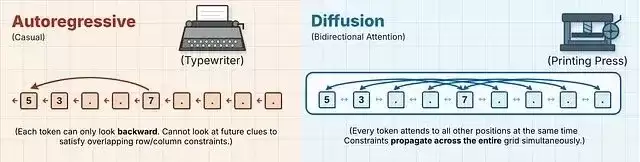
研究人员利用数独来检验双向上下文的实际价值。数独模型人皆知,自回归模型在处理时面临很大挑战——网格中的每个数字受水平、垂直和宫格三重约束的交叉限制,必须能够评估后续位置,并在发现冲突时进行回溯。顺序生成架构在结构上天然处于劣势。
实验结果令人关注:
- 基础模型表现:未经专项训练的 DiffusionGemma 基础模型,成功率几乎为零。
- Fine-tuning 后的表现:使用 Hackable Diffusion 工具箱应用监督微调方案后,成功率直接飙升至 80%。
- 效率变化:微调后的模型收敛更快,自适应提前停止机制将步数从最多 48 步压缩至 12 步。
总结
必须指出,这是一次实验性发布。整体输出质量目前仍低于标准自回归 Gemma 4 模型,因此它更适合对速度敏感的交互式本地工作流,而非高要求的生产级文本生成任务。
从落地场景来看,主要集中在三类:内联编辑与快速迭代这类需要实时反馈的场合;非线性文本结构,如代码填充、氨基酸序列、数学图(双向上下文在此优势明显);以及代码生成中的实时渲染代码和闭合复杂 Markdown 格式。
DiffusionGemma 在技术层面证明了一个重要事实:文本生成确实可以从打字机模式切换到印刷机模式。双向注意力加上迭代并行去噪,在专用 GPU 上实现了推理速度 4 倍的提升。虽然原始质量尚不及标准自回归模型,但它在解决非线性约束问题上的潜力,以及面向本地用户的高吞吐量,都是值得持续关注的发展方向。




