经过长达六年的等待,OpenAI 终于推出了其开源大模型——GPT-OSS。这是继 GPT-2 之后首次向社区开放模型权重,但单看性能表现,它并未带来令人惊艳的突破:与 DeepSeek、通义千问等现有开源模型相比,并没有明显的领先优势。
真正值得深挖的,是这次发布背后 OpenAI 所展现的设计理念。正巧,Jay Alammar 在最新发布的《The Illustrated GPT-OSS》中用信息图做了细致拆解,我们顺着他的分析来探究其中的门道。
架构延续经典,MoE 已成标配
GPT-OSS 沿用了自回归 Transformer 的经典架构,逐 token 生成输出。
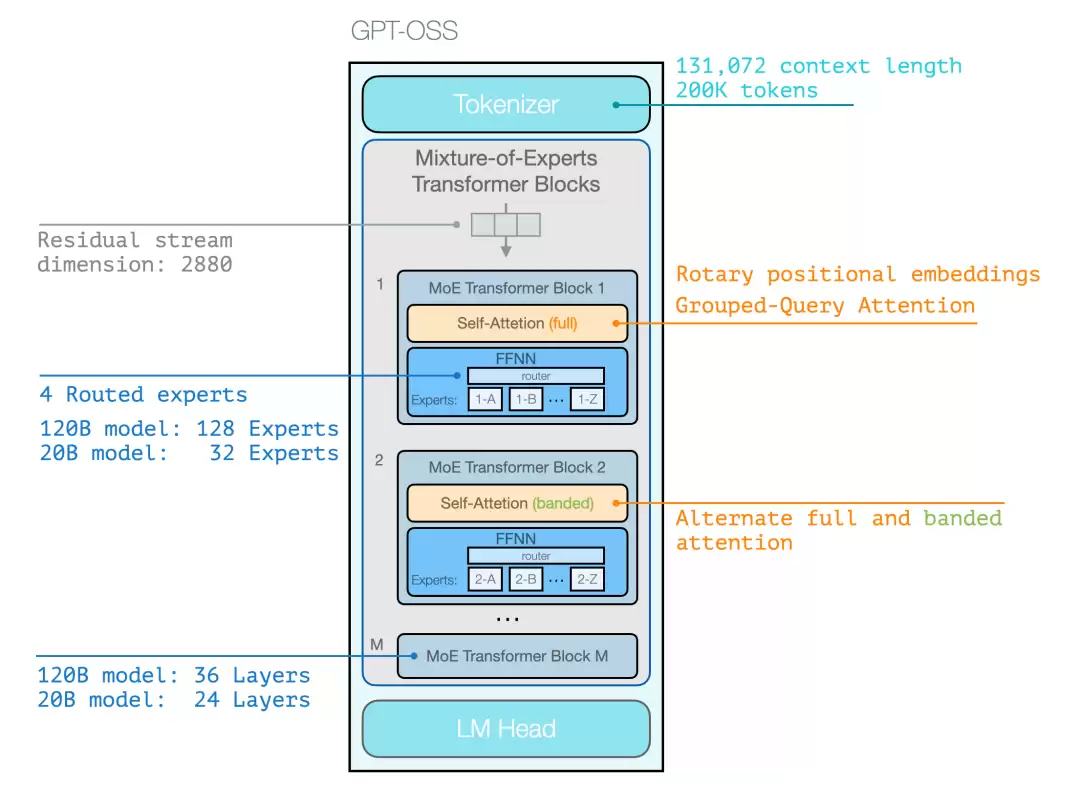
相比 GPT-2,最大的变化是引入了混合专家(MoE)架构——但这在当前的众多开源模型中早已是常见配置。
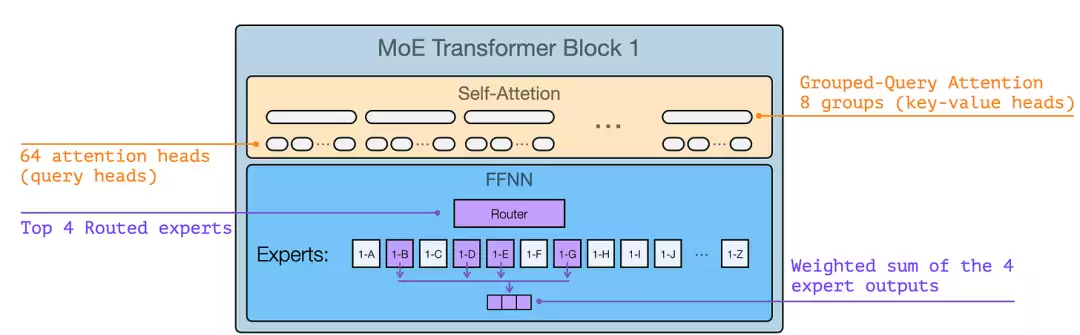
消息格式的创新设计
比起架构本身,GPT-OSS 在消息格式上的构思更值得关注。
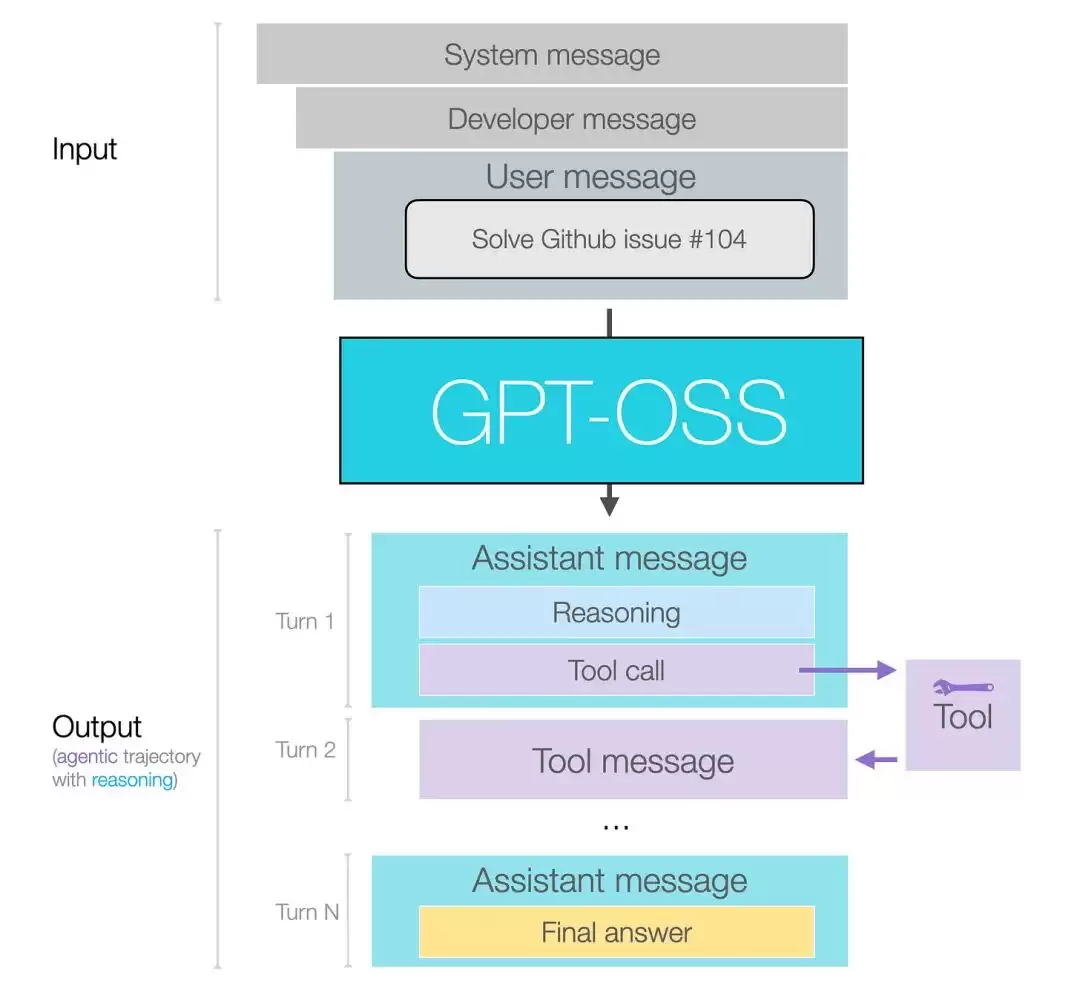
该模型引入了一个“频道”(Channel)概念,将输出划分为三类:
- Analysis —— 用于推理过程
- Commentary —— 用于工具调用
- Final —— 最终回答
这种设计让开发者能够精准控制向用户展示的内容。你可以仅输出最终答案,也可以让用户看到完整的推理链路。
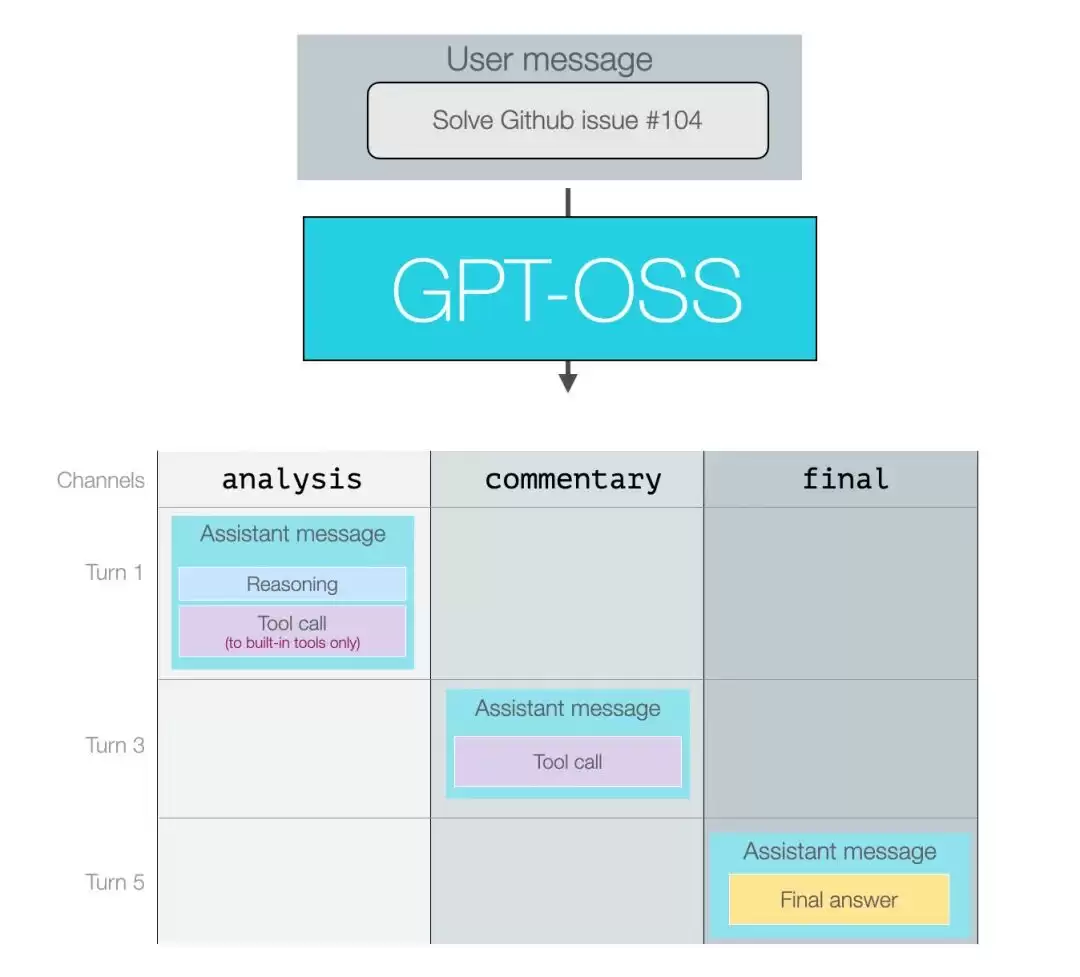
这一思路在实际开发中非常实用。很多时候用户无需看到模型的“内心独白”,但开发者却需要这些信息进行调试和优化——将两者分离,无疑是个聪明的做法。
灵活的推理强度调节
GPT-OSS 支持三档推理强度:低、中、高。这个想法并不新鲜,但实现得颇为优雅。
测试结果显示,中档和高档模式在复杂数学题上均能给出正确答案,但高档模式的计算耗时几乎是两倍。这正是典型的精度与效率权衡。
 不同推理模式效果对比
不同推理模式效果对比
这种设计在实际场景中价值显著。举例来说:执行 Agent 任务时,每一步都使用高强度推理可能导致速度过慢;而离线分析场景下,速度要求不高,直接采用高精度模式即可。
分词器性能小幅提升
GPT-OSS 的分词器与 GPT-4 相似,但在非英文 token 的处理上略微更优。emoji 和中文字符从三个 token 降至两个,阿拉伯文语段被整合为单个 token 而非逐字母拆分。
代码与数字的 token 化基本一致:三位数以内的数字仍分配单个 token,更大的数字会拆分。
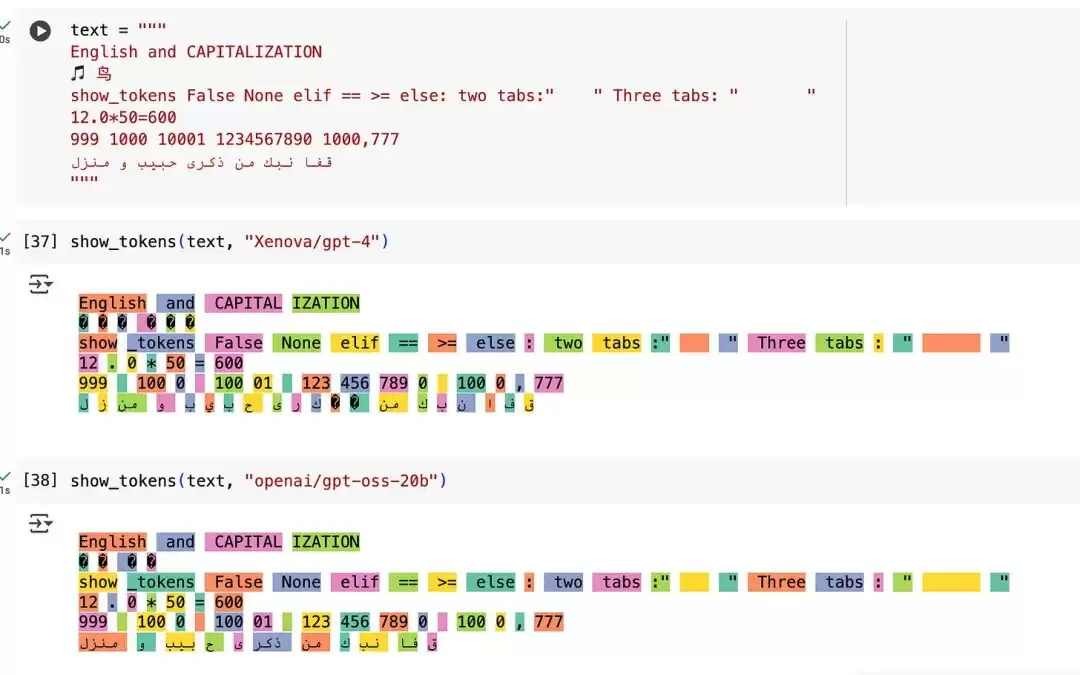 分词器对比说明
分词器对比说明
不过话说回来,由于模型主要在英文数据上训练,这一改进更多停留在理论层面——实际收益还需结合具体应用来评估。




